MAGAZINE
ルーターマガジン
PDFスクレイピング手法全公開
PDFでのデータ公開が止まらない
yugoyamamotoです。
文書のパーマリンクを共有しておけばリアルタイムに最新版が見れて便利だよねというのがインターネットの便利さではあるのですが、一向にPDFを添付しあうという文化がなくなりません。最新のスキマバイトアプリであっても労働条件だけはPDFでダウンロードする仕組みです。
厚生労働省のガイドラインでも「印刷や保存がしやすい添付ファイル」と明示されています。現時点ではPDFの一択です。 「二人が同じ書類をもってこその契約」というスタンスから考えるとパーマリンクの共有ではダメということが分かります。
いざ会社をまたがると、契約書や請求書もPDFが大半です。「大事な情報ほどPDF」「大事な情報ほど再利用しづらい」というねじれた環境となっています。そんなわけでPDFのスクレイピングを頑張っています。
表のスクレイピングではセル結合が大事
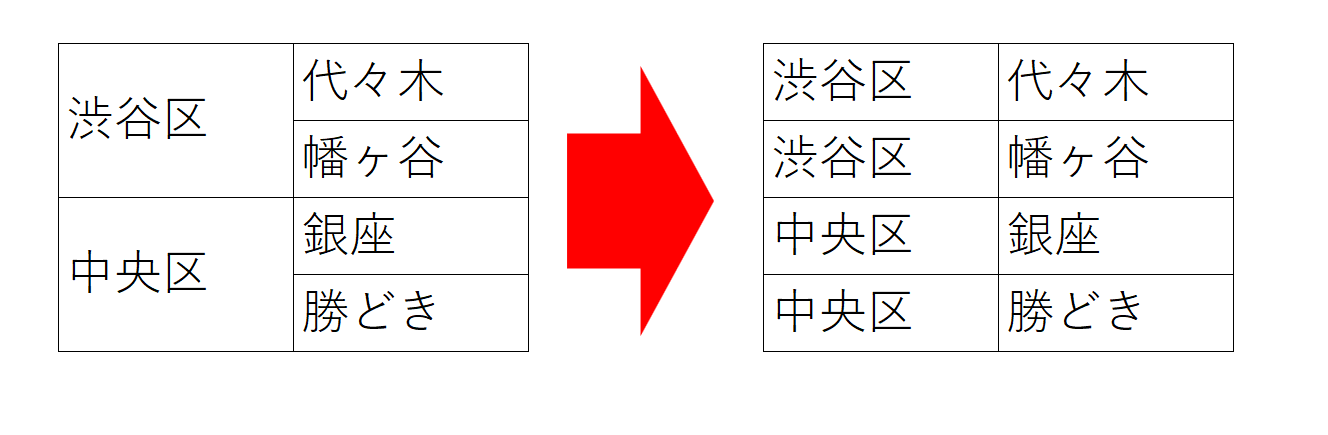
セル結合はデータとしては悪者扱いになりがちですが、それは単に「セル結合さえ認識できないシステムが無能すぎる」というだけで、人間が見ればセル結合のあるテーブルは一意にデータ構造が決まります。例えば次のデータはこういう形式です。
ExcelのCopilotにデータを分析させようとすると「セル結合したままでは分析できません」と門前払いされますが、セル結合の解釈こそ機械的にやって欲しいものです。
PDFスクレイピングにおいてもセル結合レイアウトのデータからその情報を維持したままツリー構造のデータとして取り出して、あとで1行ずつにバラしていくということをします。
これはPDFのスクレイピングに限った話ではなく、HTMLのスクレイピングにおいてもセル結合データを正しくバラすということが必要です。
以下のブログでアルゴリズムを紹介しています。 https://rooter.jp/web-crawling/parse-connected-table/
PDFのスクレイピングの方法
以上のようなゴールをふまえてPDF読み取りライブラリを検証しました。
- pdftotext
- pdftohtml
- tablula
- Solid Framework
- Word
- Excel
- PDF.jsで直接読み取ってカスタム処理
- PDFBoxで直接読み取ってカスタム処理
それぞれ紹介します
pdftotext
Popplerユーティリティのコマンドラインツールです。 プレーンテキストのみ抽出します。 表形式のデータ構造は潰れてしまいますが、例えばPDFから会社名だけを取り出したい場合には以下のようにワンライナーで出力可能です。
curl https://www.kanpo.go.jp/xxx.pdf | pdftotext - - | grep 株式会社
「官報に掲載されている会社を定点監視したい!」などのニーズであればこれで十分です。
pdftohtml
こちらもPopplerユーティリティのコマンドラインツールです。 プレーンテキストではなくhtmlになります。 フォントサイズや座標も再現してくれるので、「見出しだけ取り出したい」「フッターの文言は無視」などの用途にも耐えれます。
罫線情報はただの背景画像になるので、表形式のPDFは読み取るのが難しいです。 やろうと思えばOpenCVを使って表を画像認識で捉えるという方法もありますが、依存モジュールが増えすぎます。
OpenCVでPDFの表をパースにチャレンジしたブログ記事を以下に紹介します。 https://rooter.jp/web-crawling/parse_table_from_pdf/
tablula
Javaで作られたツールです。Python向けにもライブラリ化されています。その名の通り、表レイアウトのPDFをCSVに変換してくれます。 PDFからいきなりCSVに変換するという機能でみると優秀ですがセル結合には対応していません。
SolidFramework
有償のライブラリです。iLovePDFの裏で使われており、ここに挙げたライブラリでダントツで賢いです。PDFをExcelに変換する際にはセル結合も再現されるため、データの欠落がありません。エクセルに変換されたならあとはエクセル読み取りのライブラリを使えばOKです。
有償ライブラリのためAPIキーがないと使えません。弊社でも有償契約していたのですが、ライブラリの提供会社とその代理店が何回か変わっており、一時的にライセンスが更新できない状態に陥ってしまいました。そのタイミングで自社開発に切り替えました。
Word
伏兵です。OfficeのWordです。WordもPDFをインポートするとWordファイルに変換できます。セル結合レイアウトのPDFの表にも対応していて、Wordの表に変換してくれます。
ただし複雑な表になると表の部分を単なる画像に変換してしまうのが欠点です。
自動化するにはWord+VBAで実装する必要があります。「フォルダを定点監視してPDFをWordに変換してさらにそれをHTML形式で保存」というロジックを書けば以降はHTMLスクレイピングと同様の処理フローに合流できます。
またWindow+Officeの自動化なので、クラウドサーバー上では動かしにくいです。
Excel
ExcelもPDFの表を読み取ってくれます。ただし「表の部分だけ」で表の外は取り込みません。複数ある表のどれを読み取るか?などの指定もUI上で指示する必要があるので、バッチ処理では扱いづらいです。セル結合にも対応していません。
PDF.jsでPDFを読み取ってカスタム処理
弊社で一番長く使ってる手法です。PDFファイルの内部構造を浅くバラしていただいて、あとはカスタム処理で罫線の位置とテキストの位置を元に論理構造として解釈するというものです。
セル結合などの概念もカスタム処理の中で解釈します。
罫線に囲まれた文字はセルの中の文字として解釈し、表データの一部にします。罫線に囲まれてない文字は単なるパラグラフとして解釈できます。こうすることで表のタイトルの情報も維持できます。
ただPDF.jsのライブラリがJSライブラリとしては古く、今どきのJSの環境だったり他のライブラリとの組み合わせで苦労し始めています。JSのモジュール管理最強手法が毎年のように変わるので、10年スパンのシステムには導入しづらいです。
PDFBoxで直接読み取ってカスタム処理
最近の弊社の手法です。PDFBoxというJavaのライブラリを使ってPDFをパースします。TabulaがPDFBoxを使っておりそれにならっています。
PDFの表を読み取るときのコツ
- 罫線に見えても「細長い長方形」として描画されているケースがある
- 二重線の罫線は厳密には「長いセル結合」とも取れるため、二重線を一重線として解釈する必要あり
- 点線だと思ったら「断続的に続く長方形」といて描画されていることもあるため、これも直線扱いにする必要がある
セル結合を気にしないという選択
セル結合に対応していないPDF表の読み取りライブラリは多く存在します。NULLのセルがたくさん作られることになりますが、その場合は「一つ上のセルの値をコピー」で済ませてる人も多いです。上のセルと同じ値なのか左のセルと同じ値なのかはもはや不明のはずですがその粗さで済ませている人も世の中にはいます。弊社では許さないです。
あらためてPDFパースのコアライブラリ(オープンソースしばり)
あらためてPDFパースのコアライブラリをご紹介します。
- Poppler
- XPDF派生。Xという名の通りUNIX/Linux系OSでも動作することを前提としてるため、Cで記述されながらも移植性が高い
- InkscapeのPDFインポート機能はPopplerをライブラリとして使っているのでオープンソース界隈では実績が多い
- ただしInkscapeのPDFインポート機能も限界があって体裁が崩れるケースはある
- PDF.js
- PureJSのPDFパーサー
- 歴史が長い
- FirefoxのPDF表示エンジンとして使われているため「目にさらされるPDFパーサーでオープンソース」の中ではダントツの実績のはず
- PDFBox
- JavaのPDFパーサー
- Tabulaの依存モジュールでもあり、TabulaもPythonから呼ばれていたりもするので実績は多い
- Javaは言語レイヤーでフォントレンダリングを面倒みてくれるのが頼りになる。特に開発環境と本番環境の違いを気にしなくていい
弊社では、Poppler、PDF.js、PDFBoxを適宜使い分けています。
CONTACT
お問い合わせ・ご依頼はこちらから