カテゴリー : クローリング/スクレイピング
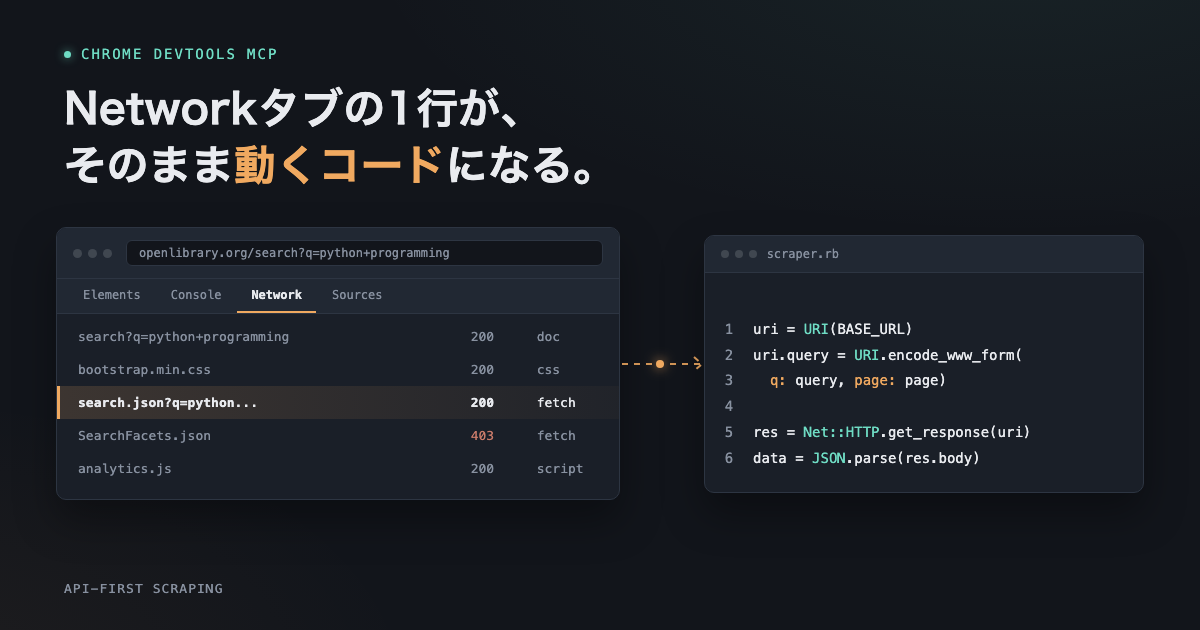
はじめに クローリング・スクレイピング案件を専門とする弊社では、「調査フェーズ」が開発全体のボトルネックになりがちです。具体的には、DevToolsのNetworkタブを開きながら「このXHRリクエストが欲しいデータを返 […]
はじめに こんにちは。エンジニアのmiyakawaです。 業務の中では毎日たくさんのEメールが受信されます。 Eメールを受信していくうちに過去に届いたメールは重要なラベルを付けていたとしても、2年前や3年前のメールを全て […]
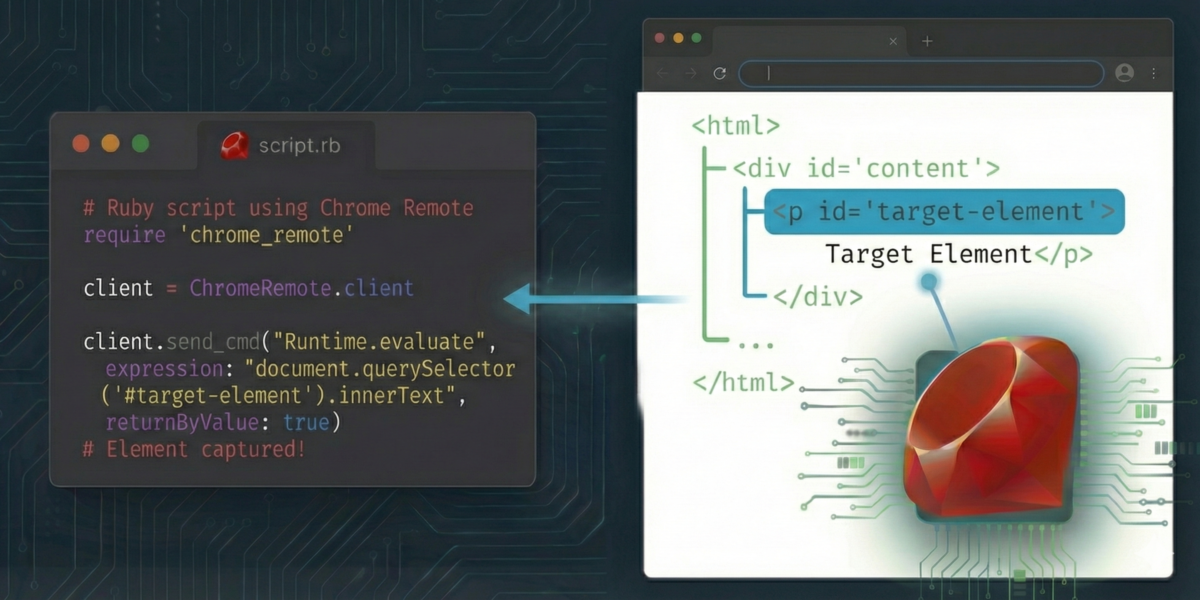
皆さん、こんにちは。エンジニアのHatanoです。 ブラウザ自動操縦でHTMLから特定のテキストを取得する際、クロールしたHTMLに対しNokogiriなどを使ってRubyで扱えるようにパースを行い、そこからCSSセレク […]
スクレイピングエンジニア8年目のitogaです。 今回は、私がスクレイピング、クローラーを実装するにあたって活用しているChrome拡張機能を4つ紹介します。 1. JavaScriptのON,OFFをするChrome拡 […]
yugoyamamotoです。 「ぽこぽこ界隈」というSNS動画界隈があります。界隈といいますが実際にはそういう動画編集フォーマットです。動画あたりの商品紹介の密度という点ではすばらしい発明です。教養として把握しておくべ […]
はじめに こんにちは、エンジニアのmiyakawaです。 ビッグデータとよく聞きますが、いまだに表に記載されているデータがPDFの中にあるということは珍しくありません。 PDF内に記載されている表が1つくらいなら手作業で […]
はじめに 近年、国内でも不正アクセスによる事件が相次ぎ、私たちが利用している多くのサービスで「二段階認証」の導入がほぼ必須となっています。 その中でも代表的なのが、Google Authenticatorを使ったワンタイ […]
PDFでのデータ公開が止まらない yugoyamamotoです。 文書のパーマリンクを共有しておけばリアルタイムに最新版が見れて便利だよねというのがインターネットの便利さではあるのですが、一向にPDFを添付しあうという文 […]
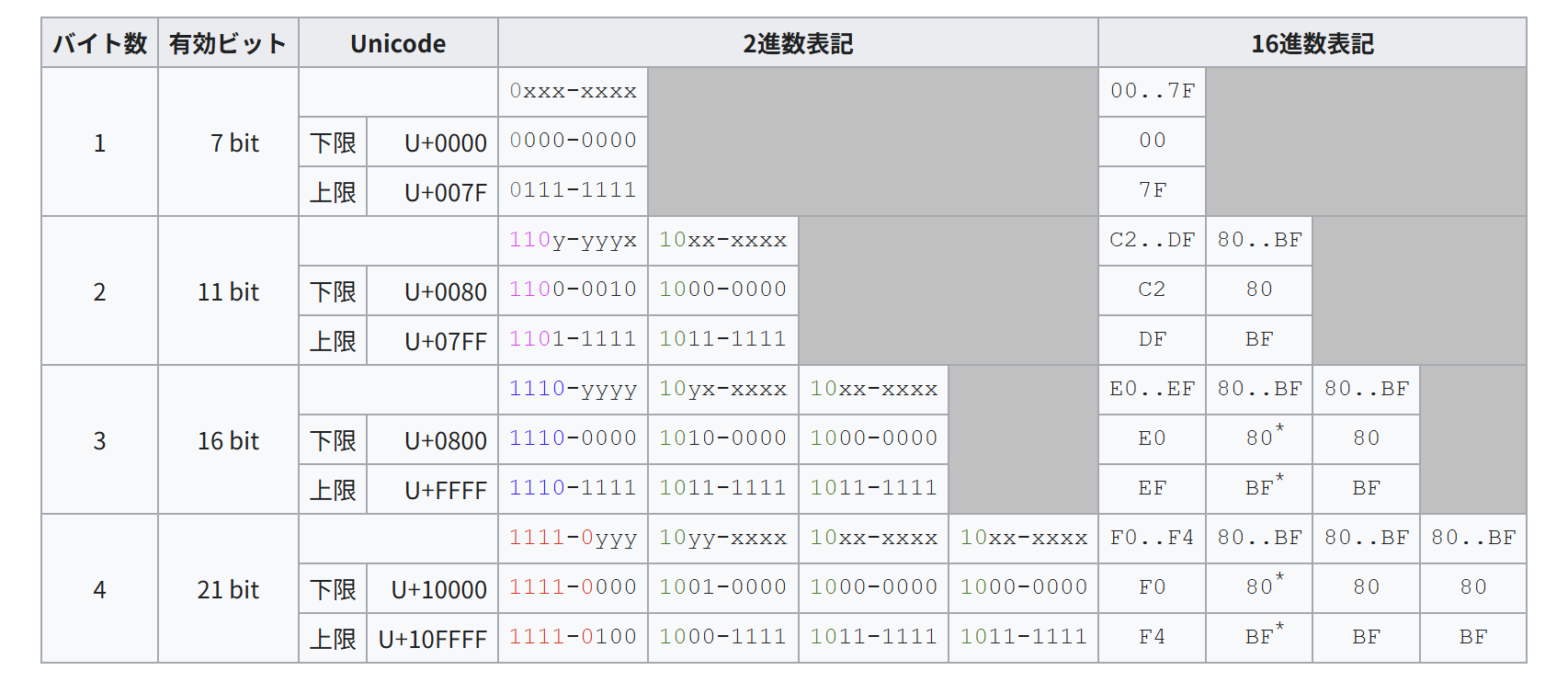
UTF8には3種類ある UTF8と一言で言っても業務上は3つの分岐が発生します BOMなしUTF8 一般的なUTF8ですね BOMありUTF8 「CSV拡張子のファイルをダブルクリックしてエクセルで文字化けせずに開かせた […]
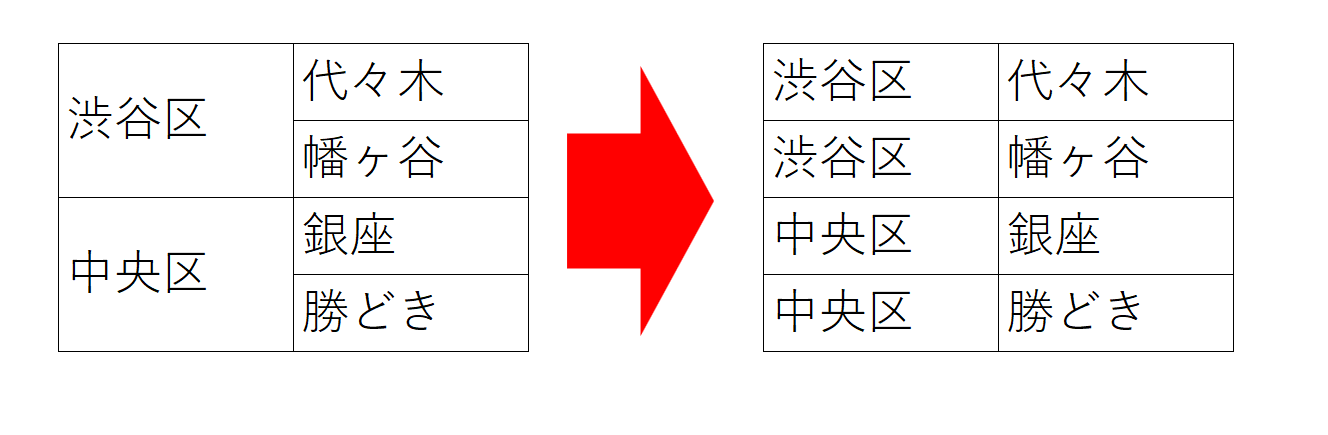
Nokogiriのtextメソッドは子孫要素まで結合されて困る RubyのNokogiriでHTMLをスクレイピングするとほぼ必ず使うメソッド「text」は、子孫要素全てのテキストを結合して取得する仕様となっています。そ […]
お問い合わせ・ご依頼はこちらから