MAGAZINE
ルーターマガジン
クローリング時にセル結合されたtableを綺麗にパースする(Table to Array)

こんにちは。学生エンジニアのTsuboiです。
Webクローリング/スクレイピングをする際、しばしばセル結合されたtableをパースする必要が出てきます。
今回は、セル結合されているtableを綺麗にHTMLからArrayに変換するRubyコードをご紹介したいと思います。
セル結合されたtableをパースしたい
以下のようにセル結合されたtableをパースすることを考えます。
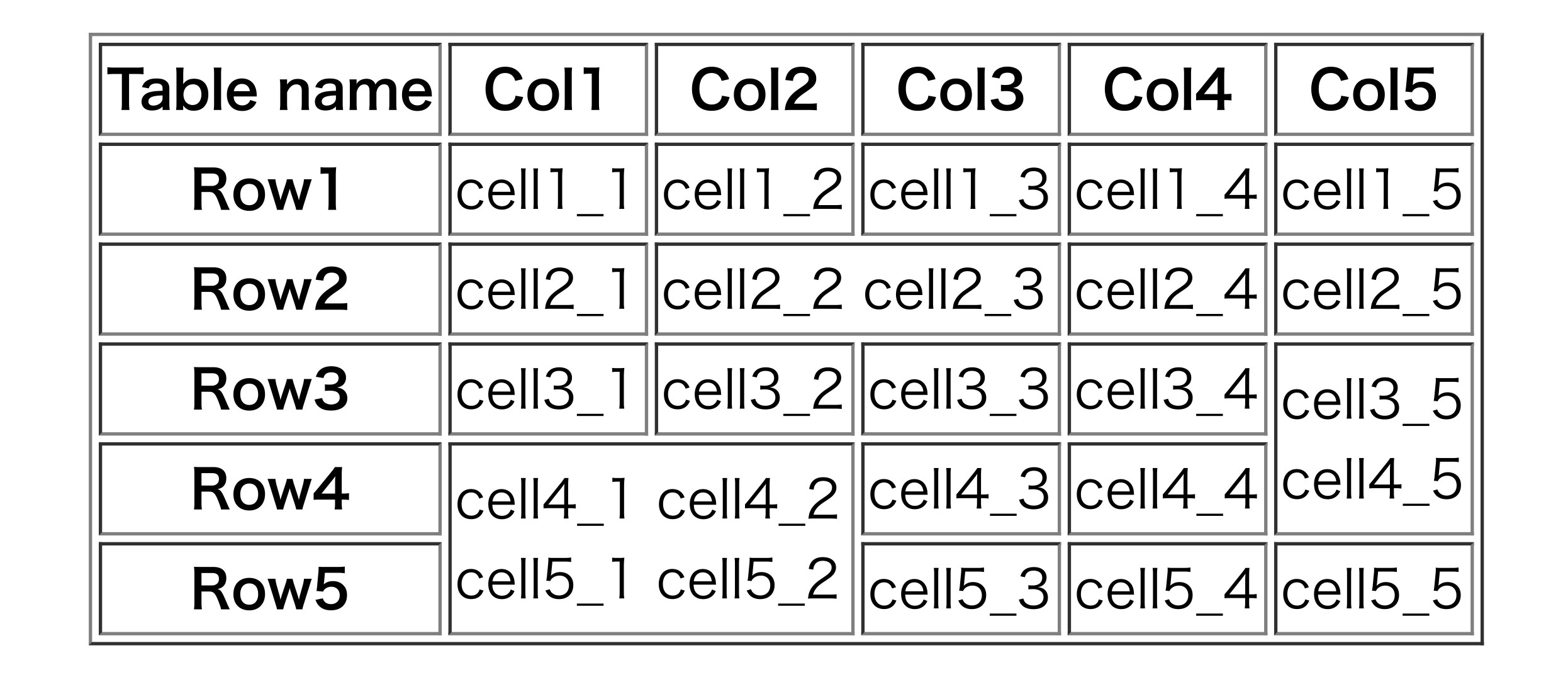
ただし、このままArrayに変換しようとすると...
[["Table name", "Col1", "Col2", "Col3", "Col4", "Col5"], ["Row1", "cell1_1", "cell1_2", "cell1_3", "cell1_4", "cell1_5"], ["Row2", "cell2_1", "cell2_2 cell2_3", "cell2_4", "cell2_5"], ["Row3", "cell3_1", "cell3_2", "cell3_3", "cell3_4", "cell3_5
cell4_5"], ["Row4", "cell4_1 cell4_2
cell5_1 cell5_2", "cell4_3", "cell4_4"], ["Row5", "cell5_3", "cell5_4", "cell5_5"]]
このようにセル結合を考慮しないで変換されてしまいます。これでは元のtableを再現できません。
以下のように変換することを目標とします。
[["Table name", "Col1", "Col2", "Col3", "Col4", "Col5"], ["Row1", "cell1_1", "cell1_2", "cell1_3", "cell1_4", "cell1_5"], ["Row2", "cell2_1", "cell2_2 cell2_3", "cell2_2 cell2_3", "cell2_4", "cell2_5"], ["Row3", "cell3_1", "cell3_2", "cell3_3", "cell3_4", "cell3_5
cell4_5"], ["Row4", "cell4_1 cell4_2
cell5_1 cell5_2", "cell4_1 cell4_2
cell5_1 cell5_2", "cell4_3", "cell4_4", "cell3_5
cell4_5"], ["Row5", "cell4_1 cell4_2
cell5_1 cell5_2", "cell4_1 cell4_2
cell5_1 cell5_2", "cell5_3", "cell5_4", "cell5_5"]]
colspanとrowspan
tableの中のセルはHTMLではtd要素で表され、セル結合はcolspanとrowspanという属性で表されます。
例として上のcell2_2,cell2_3とcell3_5,cell4_5をHTMLで見てみると...
<td colspan=2>cell2_2 cell2_3</td>
<td rowspan=2>cell3_5<br>cell4_5</td>
このように横に結合する際はcolspanを、縦に結合する際はrowspanを結合の長さだけ指定します。
ロジックの概要
今回のコードロジックの概要は下図の通りです。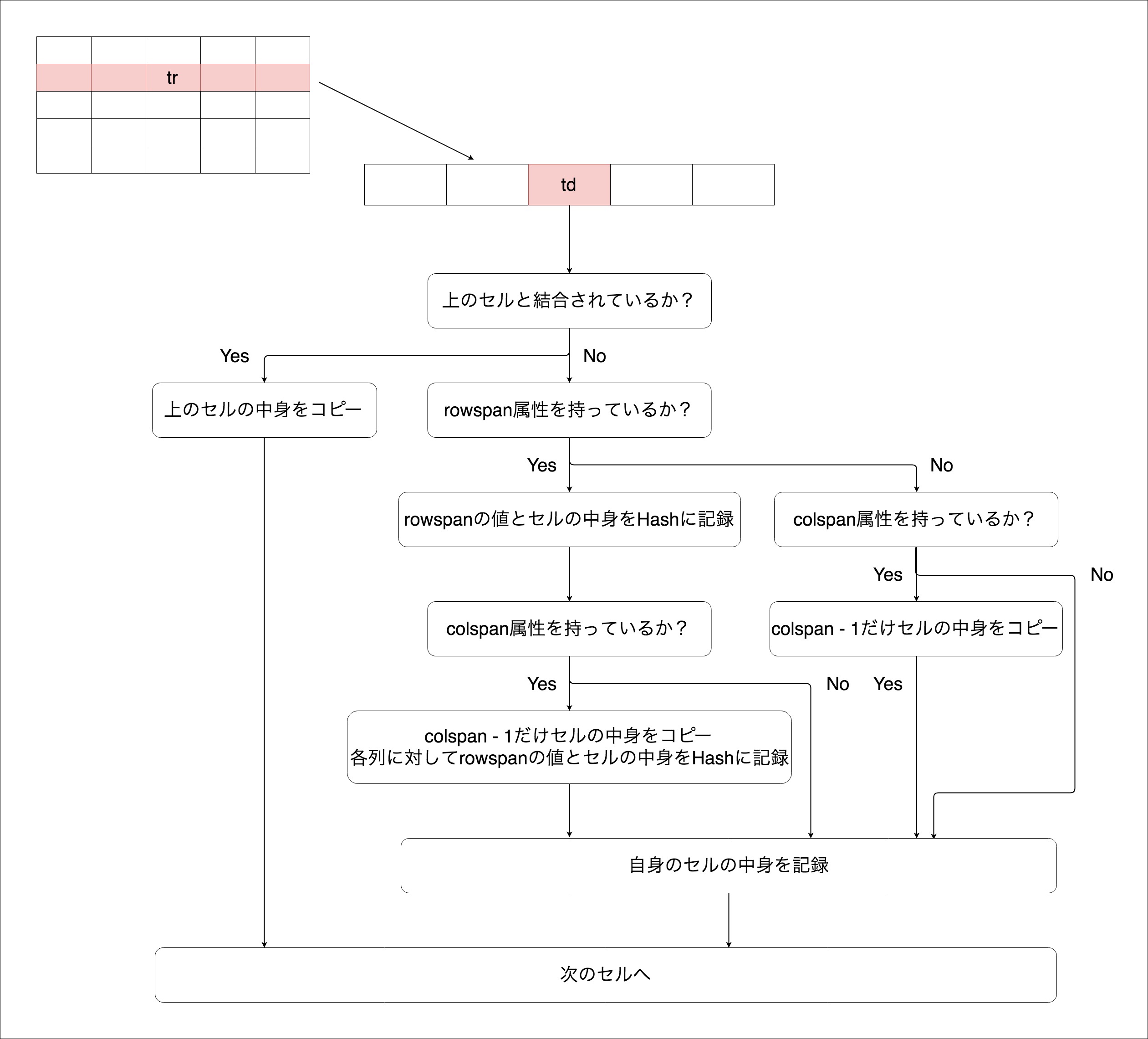
rowspanへの対応
talbeは行を表すtr要素で構成されるため、rowspanを考慮するためには一工夫必要になります。
$rowspan_count = {}
def record(rowspan_value)
$rowspan_count[$html_in_row.length] = {"remaining_rowspan" => rowspan_value - 1, "content" => $cell_node.inner_html}
end
rowspanを記録するグローバルなHashを定義し、 rowspan属性をもつセルに対しては、このHashにrowspanの値とセルの中身を記録します。Hashのキーは列のインデックスです。
def copy_rowspan_content
$html_in_row << $rowspan_count[$html_in_row.length]["content"]
$rowspan_count[$html_in_row.length - 1]["remaining_rowspan"] -= 1
if $rowspan_count[$html_in_row.length - 1]["remaining_rowspan"] == 0
$rowspan_count.delete($html_in_row.length - 1)
end
end
上のセルと結合されている場合は上のセルの中身をコピーし、下のセルと結合されていない場合はHashのキーを削除します。
colspanへの対応
上述の通り、tableは行を表すtr要素で構成されるため、colspanへの対応はさほど難しくありません。
(colspan.value.to_i - 1).times do
$html_in_row << $cell_node.inner_html
end
このようにcolspan - 1の数だけ余分にセルの中身を記録すれば済みます。
コード全容
以下に今回のコードの全容を示します。HTML解析にはNokogiriを用いています。
require "nokogiri"
require "pp"
# input: HTML String
# output: HTML String の二次元配列
def copy_rowspan_content
$html_in_row << $rowspan_count[$html_in_row.length]["content"]
$rowspan_count[$html_in_row.length - 1]["remaining_rowspan"] -= 1
if $rowspan_count[$html_in_row.length - 1]["remaining_rowspan"] == 0
$rowspan_count.delete($html_in_row.length - 1)
end
end
def record(rowspan_value)
$rowspan_count[$html_in_row.length] = {"remaining_rowspan" => rowspan_value - 1, "content" => $cell_node.inner_html}
end
def record_rowspan(rowspan_value, colspan)
if rowspan_value > 1
record(rowspan_value)
unless colspan.nil?
(colspan.value.to_i - 1).times do
$html_in_row << $cell_node.inner_html
record(rowspan_value)
end
end
end
end
def row_to_array(row)
node_index = 0
cell_nodeset = row.css("th,td")
$html_in_row = []
until (cell_nodeset.nil? or node_index >= cell_nodeset.length) and $rowspan_count[$html_in_row.length].nil?
unless $rowspan_count[$html_in_row.length].nil?
copy_rowspan_content
else
$cell_node = cell_nodeset[node_index]
rowspan = $cell_node.attribute("rowspan")
colspan = $cell_node.attribute("colspan")
if not rowspan.nil?
record_rowspan(rowspan.value.to_i, colspan)
elsif not colspan.nil?
(colspan.value.to_i - 1).times do
$html_in_row << $cell_node.inner_html
end
end
$html_in_row << $cell_node.inner_html
node_index += 1
end
end
return $html_in_row
end
def table_to_array(table)
begin
doc = Nokogiri::HTML.parse(table)
rescue => e
puts "parse error"
end
$rowspan_count = {}
html_in_table = []
row_nodeset = doc.css("tr")
row_nodeset.each do |row|
html_in_table << row_to_array(row)
end
return html_in_table
end
if __FILE__ == $0
table_sample = DATA.read
pp table_to_array(table_sample)
end
__END__
<table>
<tr>
<th>Table name</th>
<th>Col1</th>
<th>Col2</th>
<th>Col3</th>
<th>Col4</th>
<th>Col5</th>
</tr>
<tr>
<th>Row1</th>
<td>cell1_1</td>
<td>cell1_2</td>
<td>cell1_3</td>
<td>cell1_4</td>
<td>cell1_5</td>
</tr>
<tr>
<th>Row2</th>
<td>cell2_1</td>
<td colspan=2>cell2_2 cell2_3</td>
<td>cell2_4</td>
<td>cell2_5</td>
</tr>
<tr>
<th>Row3</th>
<td>cell3_1</td>
<td>cell3_2</td>
<td>cell3_3</td>
<td>cell3_4</td>
<td rowspan=2>cell3_5<br>cell4_5</td>
</tr>
<tr>
<th>Row4</th>
<td colspan=2 rowspan=2>cell4_1 cell4_2<br>cell5_1 cell5_2</td>
<td>cell4_3</td>
<td>cell4_4</td>
</tr>
<tr>
<th>Row5</th>
<td>cell5_3</td>
<td>cell5_4</td>
<td>cell5_5</td>
</tr>
</table>
このようにルーターではWebクローリングを便利に・確実に・迅速に行うべく、日夜データ構造と戦っております。皆様もぜひお試し下さい。
CONTACT
お問い合わせ・ご依頼はこちらから