MAGAZINE
ルーターマガジン
PDFに埋め込まれたテーブルを、画像処理でパースする

はじめに
こんにちは。アルバイトの近藤です。
突然ですが、HTMLからテーブルをパースしたいとき、どうしますか?
そうです、HTMLパーサーを使いましょう。
RubyならNokogiriが、PythonならBeautifulSoupが有名です。
cssセレクタでtableタグを指定して、列ごと行ごとにループを回せばパースできます。
ではPDFからテーブルをパースしたいときは...?
今回は、PDFファイル内にあるテーブルを、画像処理を駆使してパースする方法を紹介します。
概要
Popplerというライブラリがあり、pdftohtmlというコマンドを提供しています。
このコマンドを使うと、PDFをHTMLに変換できます。
ですがこのコマンド、PDF内に表があってもテーブルタグは出力してくれません。 表のテキストはpタグとして、表の罫線は背景画像として出力されてしまいます。
この画像として出力された罫線から表の部分を取得し、pタグで出力されたテキストと照らし合わせ、PDFからテーブルを抽出するのが今回紹介する方法です。
処理の中身がメインの説明です。コードは最後に貼ってあります。
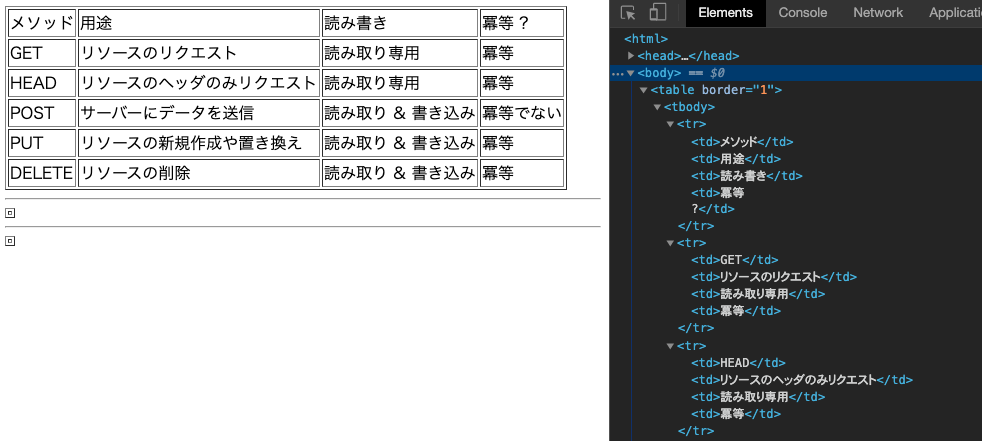
完成結果
完成結果から先にお見せします。
このようなPDFがあったときに...

このようにテーブルを取得できます
使うもの
画像処理をするのでOpenCV?を使います。
OpenCVを使うので言語はPython?です。
HTMLのパースにはBeautifulSoup?を使います。
処理の流れ
各処理の細かい説明に入る前に、大まかに処理の流れを説明します。
╂ コーナーの検出
テーブルを判定するにあたって、罫線が交差している箇所(= コーナー)を知りたいです。Harrisコーナー検出という方法を使い、画像内のコーナーを検出します。
□ セルの検出
コーナーが取れたら、次はテーブルのセルを取りたいです。コーナーが4つ、長方形の線上にあるとき、それはきっとセルです。コーナーをまとめてセルにする処理をします。
⌸ テーブル構造の検出
取れたセルには行・列の関係がまだありません。セルたちがどの行、どの列にあるかを判定します。
✎ テキストとの照らし合わせ
セルの行と列がわかったならば、それらはもうほとんどテーブルです。最後に、HTMLとして出力されたテキストと、取ったテーブルを座標の情報から照らし合わせれば完成です。
PDFをHTMLに変換
テーブルを抽出する前に、まずはPDFをHTMLに変換します。 テーブルが入ったPDFファイルを適当に用意したら、pdftohtmlコマンドに渡してあげます。
$ pdftohtml -c table.pdf
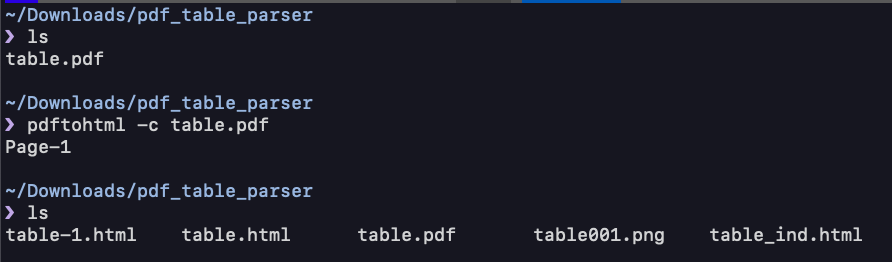
table-1.htmlのようなHTMLとtable001.pngのような画像ファイルが、PDFの枚数分出力されていると思います。
テーブルの罫線が背景画像として出力されています。
↑table001.png
これらのファイルを元に、テーブルをパースしていきます。
╂ コーナーの検出
コーナーの検出には、ハリスのコーナー検出という方法があります。OpenCVが提供しているcv2.cornerHarrisというメソッドを使うと、この方法で画像からコーナーを検出してくれます。
ですが、pdftohtmlで出力された背景画像をそのまま使うのではノイズが多いです。コーナーを検出する前に前処理をします。
テーブルには次のような特徴があります。
- 罫線の色は黒
- 罫線になりうる線は垂直か水平な線のみ
これを元に、次のような処理をします
- 画像をグレースケール化して、ある程度以上黒いものだけを黒く、それ以外は白くするように二値化
- モルフォロジー変換という処理をし、垂直・水平な線のみ抽出
ノイズを減らせました。これをハリスのコーナー検出メソッドに渡し、検出してくれたコーナーに色を付けます、ここでは赤色に塗りました?。これで画像の処理は終わりです。
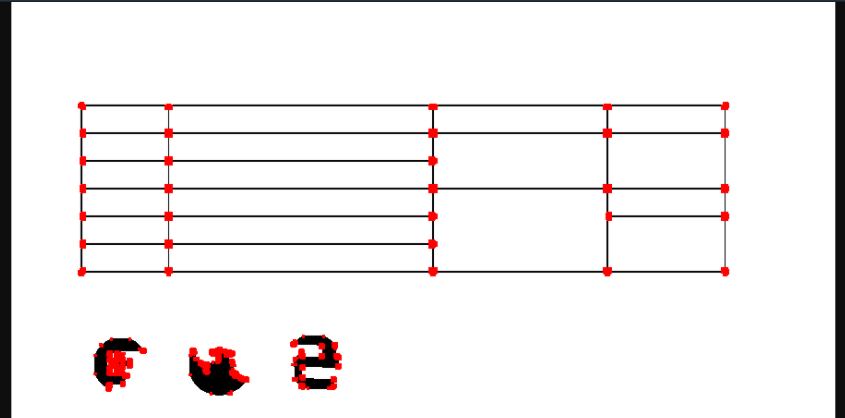
画像のピクセルを直接触るのは扱いにくいです。セル検出をする前に、隣接しているコーナーのピクセルはまとめてあげて、扱いやすくしておいて下さい。
□ セルの検出
次に、コーナーを4つ合わせてセルとして扱えるようにします。
コーナー4つがセルになる条件を考えてみると、次のような条件が思いつきます。
- コーナー4つをつなげると、垂直かつ水平な長方形になる
- コーナーからコーナーの間には、罫線が引かれている
これらを満たせばセルっぽいです。 コーナー検出で作った、
- コーナーに色付けされた画像
- 垂直・水平な罫線だけになった画像
の2つの画像を使って、セルを検出していきます。
各コーナーごとに処理をします。
- コーナーの右を見て、下に伸びているこの形(
┐,┬,┼)のコーナーを探します。 - コーナーの下を見て、右に伸びているこの形(
└,├,┼)のコーナーを探します。 - 探した右と下のコーナーの座標を足して、対角を見てみます。
- そこもコーナーならばこの4コーナーはセルです。
各コーナーにこのような処理をすることで、セルを検出することが出来ました。実装はちょっと大変です。
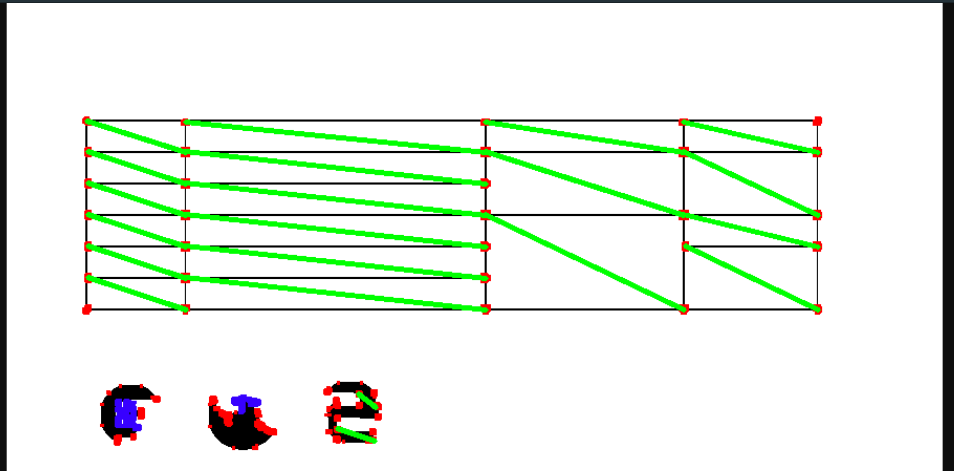
⌸ テーブル構造の検出
複数のセルをテーブルの二次元構造に落とし込みます。
まずは同じテーブル同士でセルをまとめます。隣接しているセルをまとめましょう。
次に、できたテーブルの列数・行数を判定します。
テーブル内の各コーナーのy座標が何種類あるか数えれば、(その数-1)が行数です。 同様に列数もわかります。
次に各セルがどの行・列にあるのかを調べます。セル結合も考慮すると、次のような処理になります。
(列数 * 列数 * 行数 * 行数)の4重ループを回します。それぞれ、(セルの左端のx座標, 右端のx座標, 上端のy座標, 下端のy座標)です。その4座標に重なるセルがあった時、そのセルの行のindex、列のindexがわかりました。
4重ループ。力技ですが、セルを二次元構造にパースできました。
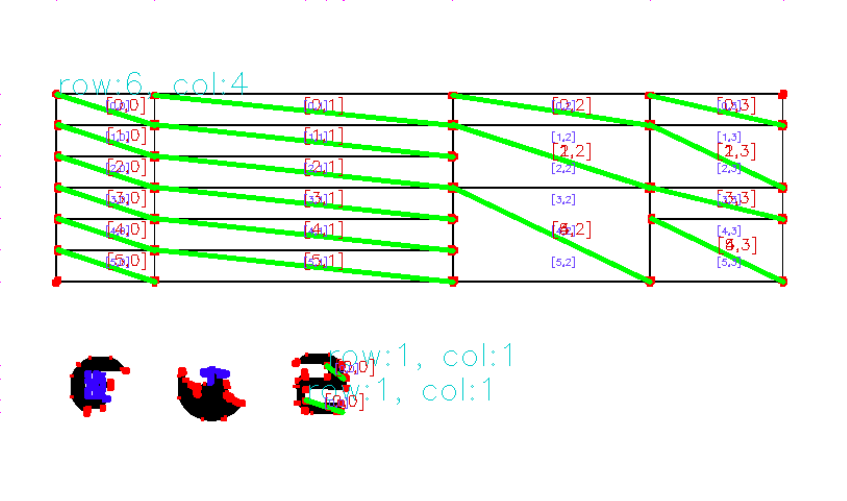
ロゴの部分もテーブル判定されてしまっていますが、列数行数が小さいテーブルは誤検知ということで無視してあげるとよいです。
✎ テキストとの照らし合わせ
いよいよテキストとの照合処理です。
pdftohtmlコマンドの出力結果のhtmlには、タグごとにx,y座標が埋め込まれています。
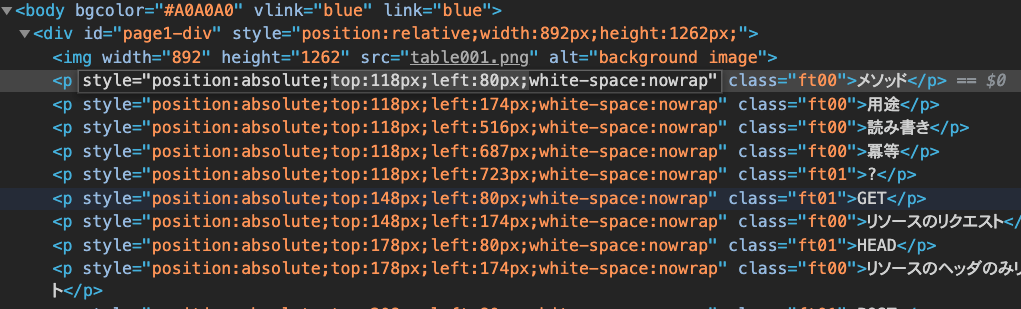
セルの内側にあるhtmlタグを探して、パースしたテーブルと紐付けます。
最後に、セル結合されたテキストは、結合解除後の全セルに配分したいです。今の状態だと、例えば3行2列のセル結合に6行の文章が書かれていた時、紐付けたときに文章が2行ごとに分断されてしまいます。セル結合がされていたならば、結合されたセルのテキストをすべて連結されて紐付けるようにしましょう。
以上で処理は終わりです。jsonやhtmlに出力して、パースしたコンテンツを活用しましょう!
おわりに
欲しいデータに限ってPDFで書かれている、そんな世の中です。この記事がお役に立てば嬉しいです。
参考
- Harrisコーナー検出 — OpenCV-Python Tutorials 1 documentation
- A table detection, cell recognition and text extraction algorithm to convert tables in images to excel files
コード
最後に、コードの全体像を載せておきます。 画像処理と構造検出中心のParserクラス(parser.py)と、HTMLとのテキスト一致をするTextMatcherクラス(text_matcher.py)に分け、それらをpdftotable.pyから呼び出しています。
普段Rubyをメインで書いているのですが、Pythonも新鮮でした。
# pdftotable.py
import sys
import re
import os
import time
import itertools
import json
import subprocess
import tempfile
import codecs
from pathlib import Path, PurePath
from itertools import *
from statistics import mean
from functools import reduce
from argparse import ArgumentParser
import numpy as np
import cv2
from parser import Parser
from text_matcher import TextMatcher
class PDFtoHTMLError(Exception):
pass
argparser = ArgumentParser()
argparser.add_argument('file_name')
argparser.add_argument('--silent', action='store_true')
argparser.add_argument('--location', action='store_true')
argparser.add_argument('--image', action='store_true')
argparser.add_argument('--html', action='store_true')
argparser.add_argument('--page')
args = argparser.parse_args()
if args.page:
skip_pages = [ int(p) for p in args.page.split(',') ]
pdf_file_path = args.file_name
base_name = os.path.basename(pdf_file_path).split('.')[0]
if (base_dir := os.path.dirname(pdf_file_path)) == '':
base_dir = '.'
with tempfile.TemporaryDirectory() as tmp_dir_path:
tmp_pdf_path = tmp_dir_path + '/table.pdf'
cp_result = subprocess.run(['cp', pdf_file_path, tmp_pdf_path], stdout = subprocess.PIPE, stderr = subprocess.PIPE)
pdftohtml_result = subprocess.run(['pdftohtml', '-c', tmp_pdf_path], stdout = subprocess.PIPE, stderr = subprocess.PIPE)
if pdftohtml_result.returncode != 0:
raise PDFtoHTMLError(pdftohtml_result.stderr.decode())
html_paths = sorted( [str(p) for p in Path(tmp_dir_path).glob('table-*.html') if re.match(r".*table-\d+\.html$", str(p)) ], key=lambda p: int(re.findall(r"\d+(?=.html)", p)[0]) )
image_paths = sorted( [str(p) for p in Path(tmp_dir_path).glob('table*.png') if re.match(r".*table\d{3}\.png$", str(p)) ], key=lambda p: int(re.findall(r"\d+(?=.png)", p)[0]) )
for html_path, image_path in zip(html_paths, image_paths):
page_number = int(re.findall(r"\d+(?=.html)", html_path)[0])
if args.page and not (page_number in skip_pages):
continue
if not args.silent:
print(f"page: {str(page_number)}/{str(len(html_paths))}")
image = cv2.imread(image_path)
colored_line_image = Parser.color_line(image)
colored_corner_image = Parser.color_corner(colored_line_image)
grouped_corner_pixels = Parser.group_corner_pixels(colored_corner_image)
colored_corner_spot_image = Parser.color_only_small_corner(colored_corner_image, grouped_corner_pixels)
colored_emph_line_image = Parser.color_emphasized_line(colored_line_image)
corner_areas = Parser.format_corner_pixels(grouped_corner_pixels)
cells = Parser.extruct_cells(colored_corner_spot_image, colored_emph_line_image, corner_areas)
colored_diagonal_image = Parser.color_cells(colored_corner_spot_image, cells)
tables = Parser.merge_cells_to_tables(cells)
tables_with_size = [ Parser.guess_table_size(table) for table in tables ]
colored_table_size_image = Parser.color_table_size(colored_diagonal_image, tables_with_size)
formatted_tables = [ formatted_table for table in tables_with_size if (formatted_table := Parser.parse_table_to_array2d(table)) ]
output_image = Parser.color_2d_array(colored_table_size_image, formatted_tables)
with codecs.open(html_path, 'r', 'utf-8', 'ignore') as html_file:
html = html_file.read()
nodes = TextMatcher.parse_nodes(html)
text_combined_tables = [ TextMatcher.combine_text(table, nodes) for table in formatted_tables]
text_casted_tables = [ TextMatcher.cast_text(table, text_table) for table, text_table in zip(formatted_tables, text_combined_tables) ]
text_table_html = '<head><meta charset="UTF-8" /></head>' + "<hr>".join([ TextMatcher.create_table_document(text_casted_table) for text_casted_table in text_casted_tables ])
with open(f"{base_dir}/{base_name}_{page_number}.json", "w") as json_file:
json_file.write(json.dumps(text_casted_tables))
if args.location:
with open(f"{base_dir}/{base_name}_location_{page_number}.json", "w") as json_location_file:
json_location_file.write(json.dumps(formatted_tables))
if args.image:
cv2.imwrite(f"{base_dir}/{base_name}_image_{page_number}.png", output_image)
if args.html:
with open(f"{base_dir}/{base_name}_html_{page_number}.html", "w") as html_file:
html_file.write(text_table_html)
# parser.py
import sys
import numpy as np
import cv2
import re # 正規表現
import os
import time
import itertools
import json
from itertools import *
from statistics import mean
from functools import reduce
class Parser:
@classmethod
def color_line(cls, image):
"""
画像(何でも良い)を受け取り、白黒に二値化したのち、垂直・水平な線のみを抽出してそれを返す
"""
BLACK_WHITE_BINARY_THRESHOLD = 150 # 白黒への二値化処理の閾値(これよりも黒いと真っ黒になる)
VERTICAL_KERNEL_SIZE = 20 # 水平方向の線のみを抽出するときの、抽出する横線の長さの最小値
HORIZONAL_KERNEL_SIZE = 20 # 垂直方向の線のみを抽出するときの、抽出する縦線の長さの最小値
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_ret, bw_image = cv2.threshold(gray_image, BLACK_WHITE_BINARY_THRESHOLD, 255, cv2.THRESH_BINARY_INV) # (元画像, 白黒閾値, ...) -> 白か黒のみに二値化された画像
vertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, VERTICAL_KERNEL_SIZE))
vertical_lines_pre = cv2.erode(bw_image, vertical_kernel, iterations=1)
vertical_lines = cv2.dilate(vertical_lines_pre, vertical_kernel, iterations=1)
horizonal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (HORIZONAL_KERNEL_SIZE, 1))
horizontal_lines_pre = cv2.erode(bw_image, horizonal_kernel, iterations=1)
horizontal_lines = cv2.dilate(horizontal_lines_pre, horizonal_kernel, iterations=1)
merged_lines = cv2.addWeighted(vertical_lines, 0.5, horizontal_lines, 0.5, 0.0)
_ret, lined_image = cv2.threshold(merged_lines, 10, 255, cv2.THRESH_BINARY_INV) # 二値化した白黒をマージした画像を黒くしたいので、第2引数は1以上の小さい数字なら何でも良い
return lined_image
@classmethod
def color_corner(cls, image):
"""
画像(何でも良い)を受け取り、グレースケール化したのちコーナー検出をする
検出したコーナーに色を付けたグレースケール画像を返す
"""
HARRIS_BLOCK_SIZE = 5 # ハリスのコーナー検出で塗られるコーナーの大きさ
gray_image = image
gray_image_f32 = np.float32(gray_image) # uint8からfloat32に変換
converted_image_raw = cv2.cornerHarris(gray_image_f32, HARRIS_BLOCK_SIZE, 3, 0.04) # グレースケール画像が作られる
converted_image = cv2.dilate(converted_image_raw, None) # 白色領域を膨張
gray_image_bgr = cv2.cvtColor(gray_image, cv2.COLOR_GRAY2BGR) # カラーの灰色画像に変換
# 配列内の値(白黒度合い)の最大値 * 0.01 よりも大きい範囲
gray_image_bgr[converted_image > 0.01 * converted_image.max()] = [0, 0, 255]
return gray_image_bgr
@classmethod
def color_emphasized_line(cls, image):
"""
白黒画像を受け取り、黒い領域を膨張させたものを返す
"""
EMPHASIZE_LEVEL = 5 # 膨張処理の回数
lined_image_emph = cv2.erode(image, None, iterations=EMPHASIZE_LEVEL)
return lined_image_emph
@classmethod
def group_corner_pixels(cls, corner_colored_image):
"""
コーナーに赤く(0,0,255)色付けされた画像を受け取り、隣接したコーナーの画素をグループ化したものを返す
具体的には3次元配列を返す(グループ複数 > グループ > x,y座標)
"""
height = len(corner_colored_image)
width = len(corner_colored_image[0])
image = [ [ { 'corner':False, 'used':False } for w in range(width) ] for h in range(height) ]
for y, x in itertools.product(range(height), range(width)):
blue, green, red = corner_colored_image[y][x]
is_corner = (blue == 0 and green == 0 and red == 255)
image[y][x]['corner'] = is_corner
corner_areas = []
for y, x in itertools.product(range(height), range(width)):
if (not image[y][x]['corner']) or image[y][x]['used']:
continue
stack = [ [y,x] ]
area = []
image[y][x]['used'] = True
while len(stack) != 0:
point = stack.pop()
h, w = point
area.append(point)
for hh, ww in [ [h+1,w], [h-1,w], [h,w+1], [h,w-1] ]:
if hh < 0 or height <= hh or ww < 0 or width <= ww:
continue
if image[hh][ww]['corner'] and not image[hh][ww]['used']:
image[hh][ww]['used'] = True
stack.append([hh,ww])
corner_areas.append(area)
return corner_areas
@classmethod
def color_only_small_corner(cls, image, corner_areas):
"""
画像(中身は何でも良い)とグループ化されたコーナーを受け取り、
その画像について、サイズが大きいグループに入っている座標の画素を青く塗ったものを返す
"""
CORNER_SIZE_LIMIT = 300 # 画素がこのサイズ以上のコーナーを除外する
output_image = image.copy()
corner_spot_areas = filter(lambda a: len(a) > CORNER_SIZE_LIMIT, corner_areas)
for area in corner_spot_areas:
for pixel in area:
y = pixel[0]
x = pixel[1]
output_image[y][x] = [255, 0, 0] # 広すぎるコーナーは文字の可能性が高いので除外(青く色づけ)
return output_image
@classmethod
def format_corner_pixels(cls, grouped_corner_pixels):
"""
グループ化されたコーナーを受け取り、そのグループのx,y座標平均と画素数を計算し、辞書の配列に整形して返す
"""
corner_areas = []
for corner_pixels in grouped_corner_pixels:
x = int(mean(map(lambda a: a[0], corner_pixels)))
y = int(mean(map(lambda a: a[1], corner_pixels)))
length = len(corner_pixels)
corner_areas.append( { 'x': x, 'y': y, 'length ': length } )
return corner_areas
@classmethod
def extruct_cells(cls, corner_image, line_image, corner_areas):
"""
(コーナーが赤く色付けされた画像, 罫線が黒く色付けされた画像, 整形済みのグループ化されたコーナー)を受け取る
罫線で繋がっているコーナー4個を、セル1個としてまとめ、それを返す
具体的には x,y,w,h がキーの辞書の配列を返す
"""
POSITION_CORRECTION = 5 # 下(右)に移動してコーナーに触れたときに、もう少し下(右)に移動する補正ピクセル数
LINE_CHECK_SIZE = 10 # 下(右)に移動してコーナーに触れたときに、その右(下)に罫線があるか判定するときにどれくらい右(下)を見るか
cells = []
for area in corner_areas:
mean_y = area['x']
mean_x = area['y']
nearest_bottom_corner_y = None
nearest_right_corner_x = None
not_found = False # 画像外に一度でも行ったらセルは無く、IndexErrorが起きてしまうので、そのフラグ
# 下直近のコーナーを探す
pos_y = mean_y
pos_x = mean_x
while (corner_image[pos_y][pos_x] == [0, 0, 255]).all():
pos_y += 1 # 自身の赤い点から下へ抜ける
if pos_y >= len(line_image):
not_found = True
break
while (not not_found) and (line_image[pos_y][pos_x] == [0, 0, 0]).all():
pos_y += 1 # テーブルの黒い線上の間、下へ動く
if pos_y + POSITION_CORRECTION >= len(line_image) or pos_x + LINE_CHECK_SIZE >= len(line_image[0]):
not_found = True
break
# 別のコーナーに当たったら、少し右を見て、右が罫線上ならば位置を取得(余裕を持たせるため少し位置を足す)
if (corner_image[pos_y][pos_x] == [0, 0, 255]).all() and (line_image[pos_y + POSITION_CORRECTION][pos_x + LINE_CHECK_SIZE] == [0, 0, 0]).all():
nearest_bottom_corner_y = pos_y + POSITION_CORRECTION
break
# 右直近のコーナーを探す
pos_y = mean_y
pos_x = mean_x
while (not not_found) and (corner_image[pos_y][pos_x] == [0, 0, 255]).all():
pos_x += 1 # 自身の赤い点から右へ抜ける
if pos_x >= len(line_image[0]):
not_found = True
break
while (not not_found) and (line_image[pos_y][pos_x] == [0, 0, 0]).all():
pos_x += 1 # テーブルの黒い線上の間、右へ動く
if pos_x + POSITION_CORRECTION >= len(line_image[0]) or pos_y + LINE_CHECK_SIZE >= len(line_image):
not_found = True
break
# 別のコーナーに当たったら、少し下を見て、下が罫線上ならば位置を取得(余裕を持たせるため少し位置を足す)
if (corner_image[pos_y][pos_x] == [0, 0, 255]).all() and (line_image[pos_y + LINE_CHECK_SIZE][pos_x + POSITION_CORRECTION] == [0, 0, 0]).all():
nearest_right_corner_x = pos_x + POSITION_CORRECTION
break
# 右or下に直近のコーナーが無いならそのコーナーはセルにはならない
if not_found or nearest_bottom_corner_y is None or nearest_right_corner_x is None:
continue
if (corner_image[nearest_bottom_corner_y][nearest_right_corner_x] == [0, 0, 255]).all():
# 右下もコーナーならこの4コーナーで1セル
cell = {'x': mean_x, 'y': mean_y, 'w': nearest_right_corner_x - mean_x, 'h': nearest_bottom_corner_y - mean_y }
cells.append(cell)
return cells
@classmethod
def color_cells(cls, image, cells):
"""
画像(何でも良い)とセルの配列を受け取り、セルの対角線を緑色に塗った画像を返す
"""
colored_diagonal_image = image.copy()
for cell in cells:
cv2.line(colored_diagonal_image, (cell['x'], cell['y']), (cell['x'] + cell['w'], cell['y'] + cell['h']), (0, 255, 0), 3)
return colored_diagonal_image
@classmethod
def merge_cells_to_tables(cls, raw_cells):
"""
セルの配列を受け取り、隣接したセルでグループ化したものをテーブル1個としてまとめ、まとめられたテーブルの配列を返す
"""
tables = []
cells = [ { **cell, 'used': False } for cell in raw_cells ]
for start_cell in cells:
if start_cell['used']:
continue
table = []
stack = [start_cell]
start_cell['used'] = True
while len(stack) != 0:
cell = stack.pop()
table.append( { 'x': cell['x'], 'y': cell['y'], 'w': cell['w'], 'h': cell['h'] } )
def is_unused_and_neighbor(target_cell): # filterのための一時関数
distance_x = abs((cell['x'] + cell['w']/2) - (target_cell['x'] + target_cell['w']/2))
half_w_sum = cell['w']/2 + target_cell['w']/2
is_overlap_x = distance_x < half_w_sum
distance_y = abs((cell['y'] + cell['h']/2) - (target_cell['y'] + target_cell['h']/2))
half_h_sum = cell['h']/2 + target_cell['h']/2
is_overlap_y = distance_y < half_h_sum
return is_overlap_x and is_overlap_y and not target_cell['used']
unused_and_neighbor_cells = filter(is_unused_and_neighbor, cells)
for unused_and_neighbor_cell in unused_and_neighbor_cells:
stack.append(unused_and_neighbor_cell)
unused_and_neighbor_cell['used'] = True
tables.append(table)
return tables
@classmethod
def guess_table_size(cls, cells):
"""
セルの配列(=テーブル)を受け取る
テーブルの行と列の位置と数を計算してそれを返す
"""
ACCEPTABLE_NEIGHBOUR_RANGE = 5 # 隣あう行(列)の座標の許容画素数. 例えば2を指定すると2画素分の行の位置のギャップは無視して同一行とみなしてくれる
row_lines = []
col_lines = []
height = max(map(lambda r: r['y'] + r['h'], cells)) + ACCEPTABLE_NEIGHBOUR_RANGE * 10
width = max(map(lambda r: r['x'] + r['w'], cells)) + ACCEPTABLE_NEIGHBOUR_RANGE * 10
blank = np.zeros((height, width)) + 255
for cell in cells:
xl = cell['x']
blank[10][(xl - ACCEPTABLE_NEIGHBOUR_RANGE):(xl + ACCEPTABLE_NEIGHBOUR_RANGE)] = 0
xr = cell['x'] + cell['w']
blank[10][(xr - ACCEPTABLE_NEIGHBOUR_RANGE):(xr + ACCEPTABLE_NEIGHBOUR_RANGE)] = 0
yt = cell['y']
yb = cell['y'] + cell['h']
for y in range(yt - ACCEPTABLE_NEIGHBOUR_RANGE, yt + ACCEPTABLE_NEIGHBOUR_RANGE):
blank[y][10] = 0
for y in range(yb - ACCEPTABLE_NEIGHBOUR_RANGE, yb + ACCEPTABLE_NEIGHBOUR_RANGE):
blank[y][10] = 0
# 列情報の検出
col_cnt = 0
pos_x = 0
vertical_line_begin = 0
vertical_line_end = 0
while pos_x < width - 1:
pos_x += 1
if blank[10][pos_x] == 0:
col_cnt += 1 # 黒に当たったら列1つ分
vertical_line_begin = pos_x
while blank[10][pos_x] == 0:
pos_x += 1 # 当たった列を抜ける
vertical_line_end = pos_x
col_lines.append((vertical_line_begin + vertical_line_end) // 2)
if col_cnt > 0:
col_cnt -= 1
# 行情報の検出
row_cnt = 0
pos_y = 0
horizonal_line_begin = 0
horizonal_line_end = 0
while pos_y < height - 1:
pos_y += 1
if blank[pos_y][10] == 0:
row_cnt += 1 # 黒に当たったら行1つ分
horizonal_line_begin = pos_y
while blank[pos_y][10] == 0:
pos_y += 1 # 当たった行を抜ける
horizonal_line_end = pos_y
row_lines.append((horizonal_line_begin + horizonal_line_end) // 2)
if row_cnt > 0:
row_cnt -= 1 # 罫線N本でN-1行なので
return { 'cells': cells, 'col_cnt': col_cnt, 'row_cnt': row_cnt, 'row_lines': row_lines, 'col_lines': col_lines }
@classmethod
def color_table_size(cls, image, tables_with_size):
"""
画像(何でも良い)と行列情報付与済みのテーブルを受け取り、
テーブルの行数、列数、それらの位置を書き込んだ画像を返す
"""
output_image = image.copy()
for table_with_size in tables_with_size:
cells = table_with_size['cells']
first_cell = cells[0]
cv2.putText(output_image, "row:{}, col:{}".format(table_with_size['row_cnt'], table_with_size['col_cnt']), (first_cell['x'], first_cell['y']), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (200, 200, 0))
for row_line in table_with_size['row_lines']:
cv2.line(output_image, (10, row_line), (20, row_line), (255, 0, 255), 3)
for col_line in table_with_size['col_lines']:
cv2.line(output_image, (col_line, 10), (col_line, 20), (255, 0, 255), 3)
return output_image
@classmethod
def parse_table_to_array2d(cls, table):
"""
テーブルを受け取り、2次元配列に変換して返す
行と列の座標の情報から、セルの2次元配列におけるインデックスを推定している
"""
ACCEPTABLE_NEIGHBOUR_RANGE = 10 # 線の座標とセルの座標の、重なりを判定するときの許容ピクセル数
cells = table['cells']
row_cnt = table['row_cnt']
col_cnt = table['col_cnt']
if row_cnt == 0 or col_cnt == 0:
return None
row_lines = table['row_lines']
col_lines = table['col_lines']
array_2d = [ [ None for _ in range(col_cnt) ] for _ in range(row_cnt) ]
for rowi12, coli12 in itertools.product( itertools.product(range(row_cnt + 1), range(row_cnt + 1)), itertools.product(range(col_cnt + 1), range(col_cnt + 1)) ) :
rowi1 = rowi12[0]
rowi2 = rowi12[1]
coli1 = coli12[0]
coli2 = coli12[1]
if rowi1 >= rowi2 or coli1 >= coli2:
continue
line_top = row_lines[rowi1]
line_bottom = row_lines[rowi2]
line_left = col_lines[coli1]
line_right = col_lines[coli2]
def is_covered(cell): # cellの四隅が[up,down,right,left]に入っていたらTrue
cell_top = cell['y']
cell_bottom = cell['y'] + cell['h']
cell_left = cell['x']
cell_right = cell['x'] + cell['w']
return abs(line_top - cell_top) < ACCEPTABLE_NEIGHBOUR_RANGE and abs(line_bottom - cell_bottom) < ACCEPTABLE_NEIGHBOUR_RANGE and abs(line_left - cell_left) < ACCEPTABLE_NEIGHBOUR_RANGE and abs(line_right - cell_right) < ACCEPTABLE_NEIGHBOUR_RANGE
covered_cells = [*filter(is_covered, cells)]
if len(covered_cells) > 0:
for rowi, coli in itertools.product( range(rowi1, rowi2), range(coli1, coli2) ):
unit_top = row_lines[rowi]
unit_bottom = row_lines[rowi + 1]
unit_left = col_lines[coli]
unit_right = col_lines[coli + 1]
unit_covered_cell = { 'x': unit_left, 'y': unit_top, 'w': unit_right - unit_left, 'h': unit_bottom - unit_top }
cell = { 'merged_position': covered_cells[0], 'unit_position': unit_covered_cell }
array_2d[rowi][coli] = cell
return array_2d
@classmethod
def color_2d_array(cls, image, array_2ds):
"""
画像(何でも良い)と2次元配列化したテーブルを受け取る
全セルについて自身の2次元配列におけるインデックスを画像に書き込み、その画像を返す
"""
output_image = image.copy()
for array_2d in array_2ds:
for rowi, coli in itertools.product(range(len(array_2d)), range(len(array_2d[0]))):
cell = array_2d[rowi][coli]
if cell is None:
continue
merged_position = cell['merged_position']
unit_position = cell['unit_position']
cv2.putText(output_image, "[{},{}]".format(rowi, coli), (merged_position['x'] + merged_position['w']//2, merged_position['y'] + merged_position['h']//2), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 200))
cv2.putText(output_image, "[{},{}]".format(rowi, coli), (unit_position['x'] + unit_position['w']//2, unit_position['y'] + unit_position['h']//2), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (255, 100, 100))
return output_image
# text_matcher.py
import sys
import numpy as np
import cv2
import re # 正規表現
import os
import time
import itertools
import json
from itertools import *
from statistics import mean
from functools import reduce
from bs4 import BeautifulSoup as bs
class TextMatcher:
@classmethod
def parse_nodes(cls, html):
"""
htmlを受け取り、pタグのx,y座標とテキストをリストにして返す
"""
doc = bs(html, "html.parser")
def format_node(node):
y = int(re.findall(r'(?<=top:)-?\d+(?=px)', node["style"])[0])
x = int(re.findall(r'(?<=left:)-?\d+(?=px)', node["style"])[0])
return { 'text': node.text, 'y': y, 'x': x }
return [ format_node(n) for n in doc.select("p[style]") ]
@classmethod
def combine_text(cls, table, nodes):
"""
引数のテーブルと同じ大きさの、html内テキストとセルを照らし合わせたテーブルを返す
要素が文字列の二次元配列を返す
"""
text_table = [ [ '' for _ in range(len(table[0])) ] for _ in range(len(table)) ]
for rowi, coli in itertools.product(range(len(table)), range(len(table[0]))):
cell = table[rowi][coli]
if cell is None:
continue
def is_inner_cell(node):
return cell['unit_position']['x'] <= node['x'] < cell['unit_position']['x'] + cell['unit_position']['w'] and cell['unit_position']['y'] <= node['y'] < cell['unit_position']['y'] + cell['unit_position']['h']
for inner_cell in filter(is_inner_cell, nodes):
text_table[rowi][coli] += inner_cell['text'] + "\n"
text_table[rowi][coli] = text_table[rowi][coli].rstrip()
return text_table
@classmethod
def cast_text(cls, table, text_table):
"""
結合されたセルのテキストを、一旦マージし、それを結合されたセルに再配分したテーブルを返す
要素が文字列の二次元配列を返す
"""
merged_table = [ [ '' for _ in range(len(table[0])) ] for _ in range(len(table)) ]
for rowi, coli in itertools.product(range(len(table)), range(len(table[0]))):
cell = table[rowi][coli]
text = text_table[rowi][coli]
if cell is None:
continue
merged_texts = [text]
for ri, ci in itertools.product(range(len(table)), range(len(table[0]))):
target_cell = table[ri][ci]
if (target_cell is None) or (ri == rowi and ci == coli):
continue
if target_cell['merged_position']['x'] == cell['merged_position']['x'] and target_cell['merged_position']['y'] == cell['merged_position']['y'] and target_cell['merged_position']['w'] == cell['merged_position']['w'] and target_cell['merged_position']['h'] == cell['merged_position']['h']:
merged_texts.append(text_table[ri][ci])
for merged_text in merged_texts:
merged_table[rowi][coli] += merged_text
return merged_table
@classmethod
def create_table_document(cls, text_casted_table):
"""
テーブルの確認のためのhtmlのtableタグを作る
"""
html = '<table border="1">'
for rowi in range(len(text_casted_table)):
html += '<tr>'
for coli in range(len(text_casted_table[0])):
html += '<td>'
html += text_casted_table[rowi][coli]
html += '</td>'
html += '</tr>'
html += '</table>'
return html
$ python3 pdftotable.py --help
usage: pdftotable.py [-h] [--silent] [--location] [--image] [--html] [--page PAGE] file_name
positional arguments:
file_name pdfファイルのパスを指定
optional arguments:
-h, --help show this help message and exit
--silent 進捗具合を標準出力に出さない
--location セルの座標が書き込まれたjsonファイルも出力
--image テーブル検出結果が書き込まれたpngファイルも出力. デバッグや確認用
--html テーブルパース結果をhtmlに出力. デバッグや確認用
--page PAGE 指定したページのみパースする. 複数ページ指定するときは , で区切る
CONTACT
お問い合わせ・ご依頼はこちらから