MAGAZINE
ルーターマガジン
net/http でログインが必要なサイトの情報を取得する

こんにちは。koyakuです。
今まで弊社のブログでは、クローリング会社というポジションから、様々なスクレイピングやクローラーの方法をご紹介してきました。その中で、rubyを使ってログインが必要なサイトのスクレイピングを行うためには、主に以下のような方法があります。
- Mechanizeを使う
- Seleniumを使う
- open-uriを使う
- net/httpを使う
ログインをしなければいけないサイトのスクレイピングの場合、MechanizeやSeleniumを使用することが多いのですが、この記事では、net/httpを使ってログインが必要なサイトの情報を取得したいと思います。
今回は、Githubのログイン後のホーム画面内のRepositoriesの情報を、実際に取得したいと思います。
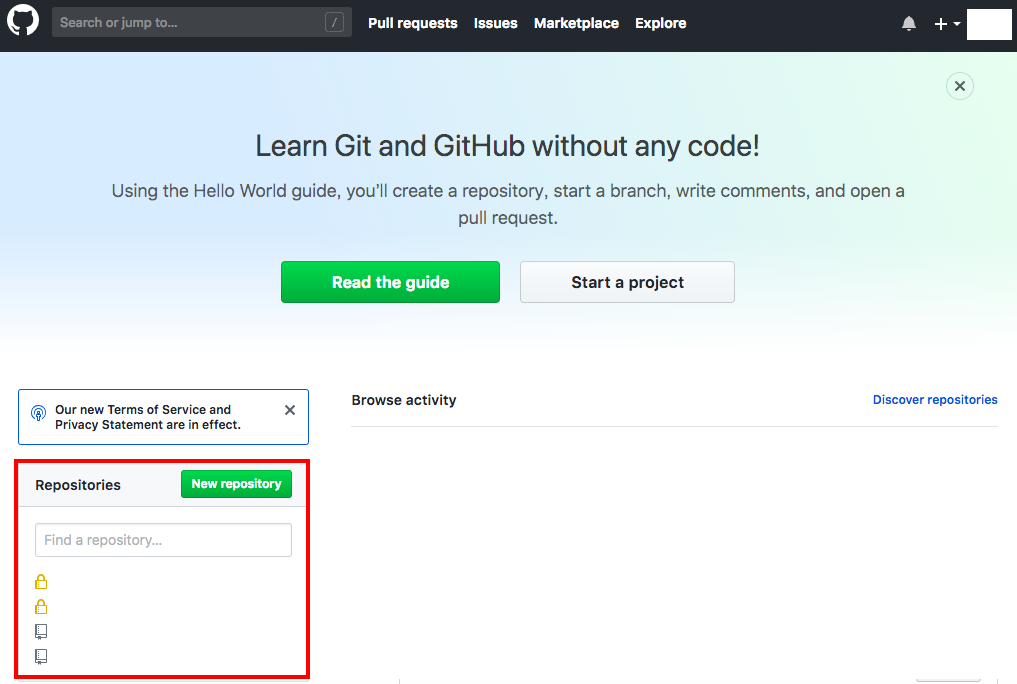
手順
- お持ちのパソコンでいつも通りGithubへログインをする
- 開発者ツールを使用し、ホーム画面の情報を取得している通信を見つける
- リクエストをnet/httpで再現する
お持ちのパソコンでいつも通りGithubへログインをする
ここは、何も気にせず、いつも通りログインしてください。
開発者ツールを使用し、ホーム画面の情報を取得している通信を見つける
開発者ツールのNetworkを使用し、取得している通信を見つけます。ログイン後、ホームボタンを押した際の通信を確認し、リクエスト情報を取得します。
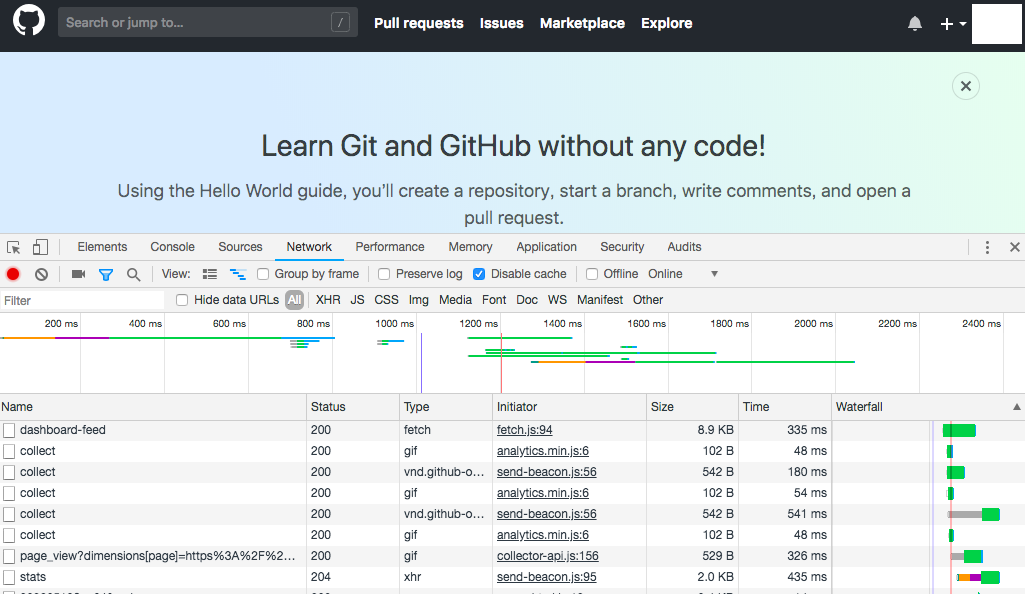
今回はメイン画面ですので、すぐに見つけられるかと思います。メイン画面だけではなく、特定の情報を取得したい場合は、開発者ツールの検索で、地道に探してみてください。
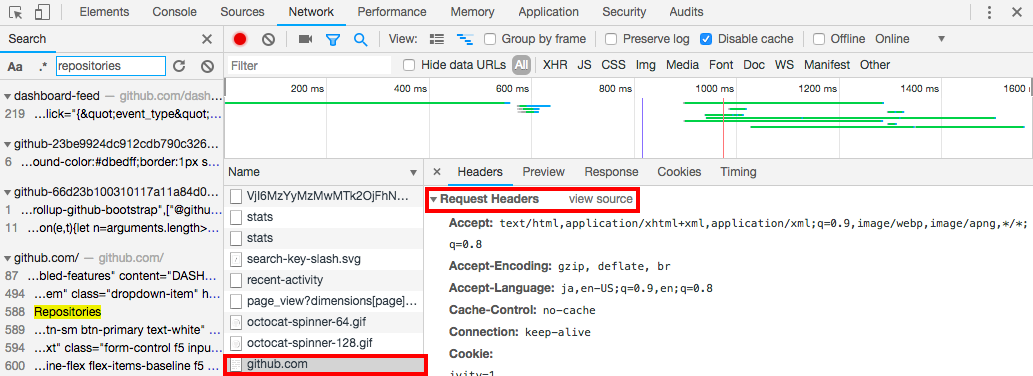
リクエストをnet/httpで再現する
1. 実行ファイル net_http.rbを任意のディレクトリに作成。取得結果を任意のnet_http.htmlファイルに保存する。
# 必要な機能の呼び出し
require 'net/http'
require 'uri'
# 対象のURLの指定
uri = URI.parse("https://github.com/")
# GETオブジェクトの作成
request = Net::HTTP::Get.new(uri)
# リクエスト情報の追加
request["Connection"] = "keep-alive"
request["Upgrade-Insecure-Requests"] = "1"
request["User-Agent"] = "ご自身のUser-Agentを入力してください"
request["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"
request["Referer"] = "https://github.com/"
request["Accept-Language"] = "ja,en-US;q=0.9,en;q=0.8"
request["Cookie"] = "ご自身のCookieを入力してください"
req_options = {
use_ssl: uri.scheme == "https",
}
# リクエストを送る
response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http|
http.request(request)
end
# 適当なファイルへ挿入
File.open("./net_http.html", "w") do |f|
f.write(response.body)
end
2. 実行
ruby net_http.rb
# 必要な機能の呼び出し
require 'net/http'
require 'uri'
# 対象のURLの指定
uri = URI.parse("https://github.com/")
# GETオブジェクトの作成
request = Net::HTTP::Get.new(uri)
# リクエスト情報の追加
request["Connection"] = "keep-alive"
request["Upgrade-Insecure-Requests"] = "1"
request["User-Agent"] = "ご自身のUser-Agentを入力してください"
request["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"
request["Referer"] = "https://github.com/"
request["Accept-Language"] = "ja,en-US;q=0.9,en;q=0.8"
request["Cookie"] = "ご自身のCookieを入力してください"
req_options = {
use_ssl: uri.scheme == "https",
}
# リクエストを送る
response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http|
http.request(request)
end
# 適当なファイルへ挿入
File.open("./net_http.html", "w") do |f|
f.write(response.body)
end
ruby net_http.rbリクエストの項目が多いように感じるかと思いますが、ポイントはCookieです。Cookieがリクエスト項目として付与されているため、ログインする事なく、ログイン後の画面情報を取得する事ができます。
ただ、皆様ご存知のように、Cookieは有効期限があります。スクレイピングこのようなスクレイピングを1度のみ行う場合は問題ありませんが、定期的に同じURL/通信の情報を取得したい場合は、忘れずにCookie更新した上で、プログラムを実行する必要があります。
Cookieを更新する際は、Mechanizeを使用して、更新プログラムを別途作成することをお勧めします。Mechanizeの入門についてはこちらをご確認ください。
結局Mechanize使うの?というご意見を頂きそうですが、Cookieの更新頻度は高くありませんので、メモリの使用は控えることはできるかと思います。
3. 実行結果を確認してみる。
net_http.htmlの中に、Repositoriesに関する情報が取得できていたら成功です。

非常にシンプルな通信で再現しましたが、HTTP通信の結果がJson形式で返ってくるものにも使用できますので、他のログインが必要なサイトでもぜひお試しください。
おまけ
net/httpを使用すると、curlコマンドを即座に再現することができます。
手動でコードを書いても良いのですが、rubyに関しては、curl-to-rubyという便利なサイトがあります。そちらを使うと即座にcurlコマンドをnet/httpに変換できます。
https://jhawthorn.github.io/curl-to-ruby/
CONTACT
お問い合わせ・ご依頼はこちらから