MAGAZINE
ルーターマガジン
ruby正規表現での空白文字の扱い
こんにちは!
ルーターに入社し約半年になるTakahashiです。
今回は、クローリングの際に取得した文字列をrubyで解析する際の事例について書きます。テーマは「空白文字」です。
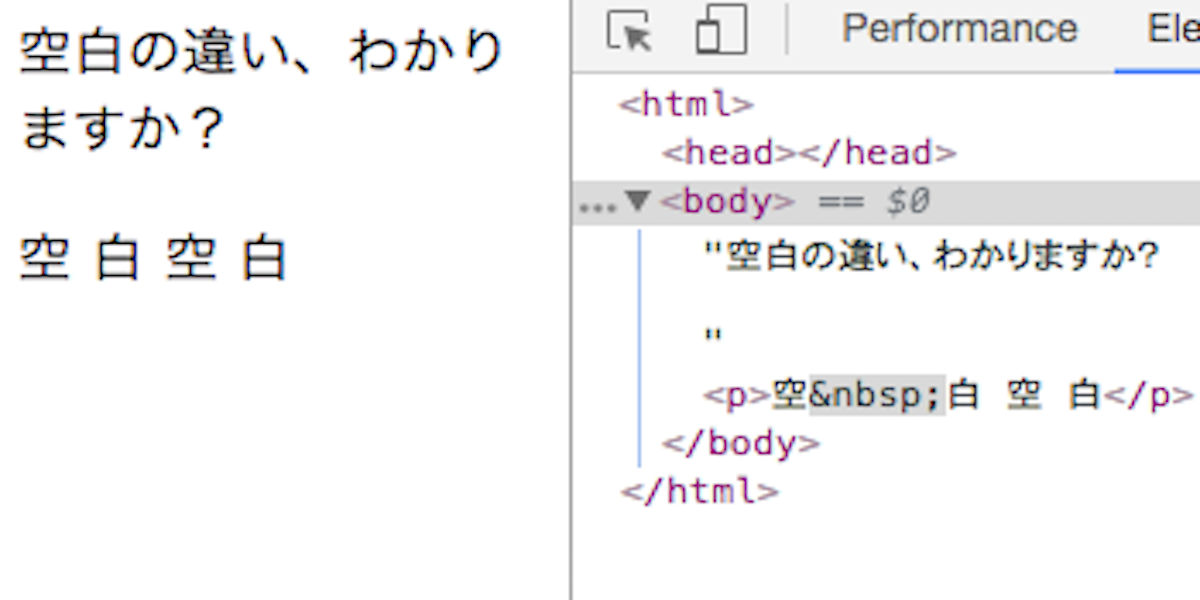
早速ですが次の実行結果に違和感はありませんか?
(コマンドラインで手軽にrubyコマンドを実行できるirbを使用しています。)
"空 白 空 白".split("\s")
=> ["空 白", "空", "白"]
同じスペースに見えますが、空白文字のメタ文字\sにマッチするものとしないものがあるようです。
空白について見る前に、まずはコードで使用しているsplitメソッドについて見ていきましょう。
splitメソッド
文字列を引数の区切り文字で分割して配列化するメソッドです。
https://docs.ruby-lang.org/ja/latest/method/String/i/split.html
引数には正規表現を使用できます。
クローラーで取得した、スペース区切りになった性名の文字列を分割したい場合などによく使うメソッドです。rubyでスクレイピングをするなら必須と言えるメソッドでしょう。
なぜこうなったか
"空 白 空 白".split("\s")
=> ["空 白", "空", "白"]
2個目と3個目のスペースは、通常の半角スペースです。
問題の1個目のスペースは、「ノンブレーキングスペース(non-breaking space)」と言い、半角スペースとは似て非なるものです。「ノーブレークスペース」とも呼ばれるようです。
\sのようなrubyの正規表現の略記法は、ascii文字コードにしか対応していませんが、「ノンブレーキングスペース」はasciiコード対象外であることが、今回の事例の原因だったようです。
ノンブレーキングスペース
ノンブレーキングスペースは改行したくない場合に使用されるスペースです。
英語などの単語間にスペースがある言語では、スペースがある場所ではどこでも改行可能とみなされます。
ノンブレーキングスペースはこのスペースでの改行を禁止するという用途があるようです。
例えば、(rooter inc)の間にノンブレーキングスペースを置き、rooterとincの間で改行されないようにする、といった使い方をされるようです。
では、ノンブレーキングスペースをを正規表現でどうマッチさせるか、みていきましょう。
解決法1 文字コード番号を正規表現で指定する
text.split(/[\u00A0\s]/)
=> ["空", "白", "空", "白"]
正規表現の[]は、[]の中に含まれる一文字という意味があります。
この場合は、
\u00A0
\s
のいずれかにマッチする文字になります。
\sは先ほど見た、ascii文字コード範囲内の空白です。
\u00A0ですが、00A0が、ノンブレーキングスペースを表すunicode文字です。\uに続けてunicode文字を指定することにより、正規表現でunicode文字を指定できます。
ノンブレーキングスペースに限らず、様々な事例に使えそうです。
解決法2 POSIX文字クラスを利用する
"空 白 空 白".split(/[[:space:]]/)
=> ["空", "白", "空", "白"]
POSIX文字クラス[:space:]では、ノンブレーキングスペースに限らず、全角スペースのようなasciiコード対象外の空白にもマッチします。
注意点としては、[]の文字クラスの中でしか使用できません。
見た目はかなり特殊ですが、空白をまとめてマッチさせたい場合に便利な記法です。
まとめ
文字列中の空白は、何もないように見えますが、「空白が存在する」のですね。 マッチさせたい空白の文字コードを見極めて、適切な正規表現を使用したいです。 空白をまとめて削除したい場合等にPOSIX文字クラスを使ってみてはいかがでしょうか。
CONTACT
お問い合わせ・ご依頼はこちらから