MAGAZINE
ルーターマガジン
Rubyでhtmlを整形したり、不要なタグを削除する

こんにちは。koyakuです。
今回は、rubyを使ってhtmlを整形したり不要なタグを削除して、html内のテキストを取得する方法をご紹介します。メモ程度の分量を取得したい場合は、コピー & ペーストで全く問題ないかと思いますが、データベースに保存したい時や、定期的にその作業が発生する場合は、手動ではなくプログラムにお願いした方が便利、かつ正確かと思います。
下準備
今回は、以前koyakunが作成した社会人からエンジニア転向して、ルーターのエンジニア新人研修で学んだことという記事の内容を取得したいと思います。
まず、都合の良い場所に、html_parseというディレクトリを作成し、移動します。
mkdir html_parse
cd html_parse
先ほどの記事のhtmlを取得します。今回はcurlコマンドを使用します。
curl https://rooter.jp/rooter/what_i_learned_after_working/ > blog.html
下記のように、htmlを取得することができたでしょうか?
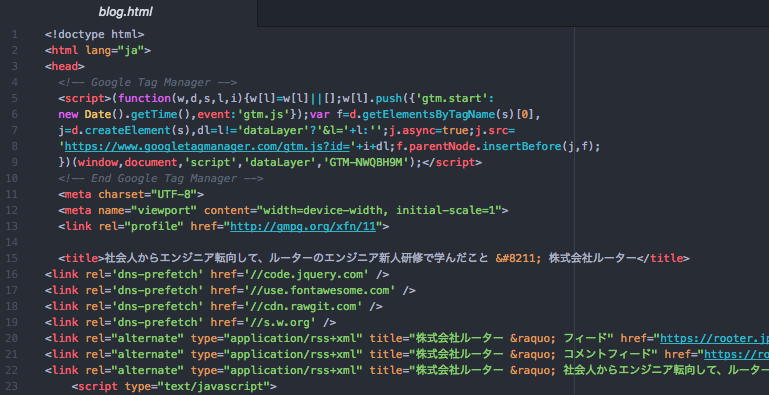
それでは実際に整形していきましょう。
Nokogiriを使う
先に、Nokogiriの詳細な使い方を確認されたい方は、こちらをご確認ください。
Nokogiriを使って、bodyタグ内の文章を、nokogiri.txtに抜き出します。改行を含むと内容を確認しづらくなりますので、改行は除いてあげます。
まずは、Nokogiriをinstallします。
gem install nokogiri
bodyタグ内のテキストを取得します。
require 'nokogiri'
html = File.read("./blog.html")
doc = Nokogiri::HTML.parse(html, nil, 'utf-8')
body = doc.at_css("body")
blog_text = body.text.gsub(/(\r\n|\r|\n|\f|\t)/, "")
File.open("./nokogiri.txt","w") do |f|
f.write(blog_text)
end
以下のようにコンテンツを取得できたでしょうか。
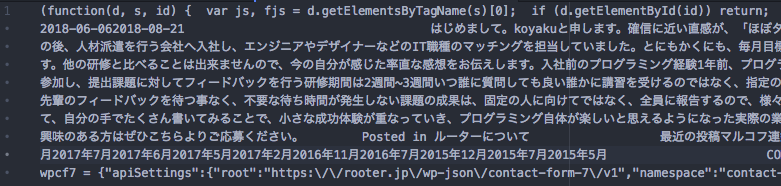
内容を確認すると、コードのような文字も含まれています。
実際に取得したhtmlと、Chromeの開発者ツールを使って実際のコードを確認してみると、scriptタグのテキストも合わせて取得してしまっていますので、不要なタグは削除しましょう。
require 'nokogiri'
html = File.read("./blog.html")
doc = Nokogiri::HTML.parse(html, nil, 'utf-8')
body = doc.at_css("body")
body.search("script").each(&:remove)
blog_text = body.text.gsub(/(\r\n|\r|\n|\f|\t)/, "")
File.open("./nokogiri.txt","w") do |f|
f.write(blog_text)
end
下記のようなテキストが取得できます。scriptタグ内のテキストを削除する事が出来ました。

修正したコードでは、Nokogiriのsearchメソッドで、削除したいタグを検索し、見つかったもの全てを削除しています。
Sanitizeを使う
Sanitizeは、取得を許可するタグや属性を指定できる便利なGemです。
こちらを使って、同様にテキストを取得します。
まず、Sanitizeをインストールします
gem install sanitize
今回は、以下の4つのhtmlタグのみ取得を許可することとします。(みなさんがご使用の際には、タグ名を変更すれば好きなタグを許可することができます。)
br center font hr
先ほどと同じ要領で、sanitize.txtに取得結果を出力します
require 'sanitize'
html = File.read("./blog.html")
content = Sanitize.clean(html, :elements => %w{br center font hr})
blog_text = content.gsub(/(\r\n|\r|\n|\f|\t)/, "")
File.open("./sanitize.txt","w") do |f|
f.write(blog_text)
end
下記のように取得ができましたでしょうか。
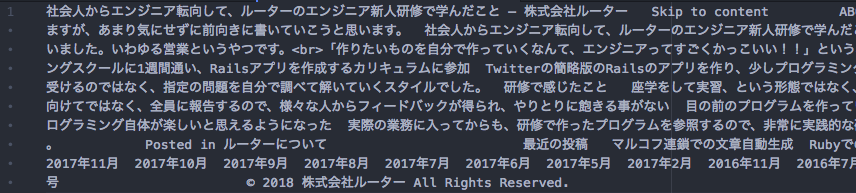
すっきりとテキストを取得出来ました。
ただ、Nokogiriにも言えることなのですが、特定のタグを削除・回避することになりますので、必要なコンテンツまで削除してしまう可能性があります。
そのため、タグの選択は過不足がないように行なうことが前提ですので、お気をつけください。
htmlを整形する方法を2つ紹介させて頂きましたが、Sanitizeでは、Nokogiriのように要素(ノード)を指定して取得することができないため、bodyの中身のみに使用するという事ができません。そのため、必要に応じてNokogiriなどの他メソッドと組み合わせるという方法も可能です。
この他にも、htmlをパースするGemやメソッドは様々存在します。全てを網羅する事は厳しいかもしれませんが、よく使うものは、自分自身でメソッドを作ってストックしておくと、いざという時に便利かと思いますので、皆様もお試しください。
CONTACT
お問い合わせ・ご依頼はこちらから