MAGAZINE
ルーターマガジン
複数サーバー処理のRPAで処理の重複を防ぐ

こんにちは。株式会社ルーターのエンジニアTakahashiです。
弊社はサイトコントローラーを始めとしたRPAを得意としております。今回はRPAを行うサーバーの負荷分散に関する実装についてです。
RPAの実装
弊社では、APIとクローラーを組み合わせるパターンの実装が多いです。APIでリクエストを受け取り、クローラーが実際の操作を行う、という分担です。APIはジョブのリクエストを受け取ったら、すぐに操作を行わず、DBに未実行のジョブとして保存します。
なぜリクエストをそのままクローラーにつながないかというと、クローリング負荷のコントロールが難しくなってしまうからです。
確かに即応性は下がりますが、DBが緩衝となり、ジョブの確実な実行を担保しています。
ジョブとステータス
RPAの操作はデータベースのジョブテーブルに保存したジョブの単位でクローラーが実行します。
では、ジョブの実行部をrubyのActiveRecordを使用して書いてみます。(ルーターではrubyをよく使います)
| ステータス | 状態 |
|---|---|
| 0 | 未着手 |
| 1 | クロール中 |
| 2 | クロール正常終了 |
# jobsテーブルからステータスが0のジョブを取得しています
Job.where(status: 0).each do |crawl_job|
# クロールをはじめるのでstatusを1にします
crawl_job.update(status: 1)
# クロールを行う部分です
exec_crawl(crawl_job)
# クロールが終わったのでstatusを2にします
crawl_job.update(status: 2)
sleep 1
end
クローリングサーバー負荷分散
ここまで、一台のクローリングサーバーを運用する前提で書いていましたが、それでは処理が間に合わない場合も考えられます。
弊社では、そのような処理に時間がかかり、かつリクエスト数の多いRPAも扱っております。
このとき、処理の重複に注意する必要があります。
処理が重複してしまうコード
金銭を扱う等、デリケートな操作を含む場合、複数サーバーが同じジョブを実行することは確実に防ぐ必要があります。
では、先程の実装を複数サーバーで動かした場合、処理の重複を防ぐことはできるのでしょうか。シミュレーションしてみます。
まず、jobsテーブルに仮想のジョブを100個createします。(activerecordのrequire・db接続設定等をcommonで行なっていますが、割愛します)
require "./common"
Job.delete_all
100.times do
Job.create(
status: 0,
count:0
)
end
以下はRPAクローラー実行部の想定です。クロールの実行の代わりにレコードのcountカラムの値をインクリメントしています。
このcountの値が1より大きい場合、処理が重複していることになります。
require "./common"
server = ARGV[0]
def main(server)
Job.where(status: 0).each do |crawl_job|
# クロールをはじめるのでstatusを1にします
crawl_job.update(status: 1)
# クロールを行う部分です。
crawl_job.reload
crawl_job.increment(:count)
crawl_job.save
# クロールが終わったのでstatusを2にします
crawl_job.update(status: 2,server:server)
sleep 1
end
end
while Job.where(server:nil,status:0).order("updated_at ASC").first
main(server)
end
以下のmulti_process.shでは、1プロセスを1サーバーにみたてて、update_countup.rbを複数プロセスで実行しています。
(コマンドライン引数の数字をupdate_countup.rbではserverとして扱っています。)
bundle exec ruby update_countup.rb 1 &
bundle exec ruby update_countup.rb 2 &
bundle exec ruby update_countup.rb 3 &
bundle exec ruby update_countup.rb 4 &
bundle exec ruby update_countup.rb 5 &
実行結果は・・・
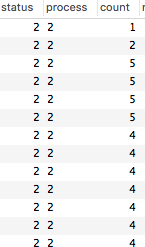
countが4とか5だったりします。かなり処理が重複していることがわかります。
以下の部分で、where(status: 0)でステータス0のジョブを全件取得してしまうので当然と言えば当然ですが。
Job.where(status: 0).each do |crawl_job|
処理の重複を防ぐコード
では、これを防ぐ実装を見てみます。(実行部・multi_process.shは先程と同様です)
require "./common"
# 生AQLを実行するため
@con = ActiveRecord::Base.connection
server = ARGV[0]
def update_sql(server,table_name)
<<~EOF
UPDATE `#{table_name}` SET `process` = #{server}, `status` = 1 WHERE `status` = 0 AND `process` is NULL LIMIT 1 ;
EOF
end
def main(server)
# SQLを直接実行。1レコードのみステータスを1にし、自身のserverをセットします。
@con.execute(update_sql(server,Job.table_name))
# ステータスが1のレコードを1件だけ取得します
crawl_job = Job.where(process:server,status:1).order("updated_at ASC").first
if crawl_job
# クロールを行う部分です。
crawl_job.reload
crawl_job.increment(:count)
crawl_job.save
# クロールが終わったのでstatusを2にします
crawl_job.update(status:2)
end
end
while Job.where(process:nil,status:0).order("updated_at ASC").first
main(server)
end
実行結果は・・countが全て1なので、重複が防げています。
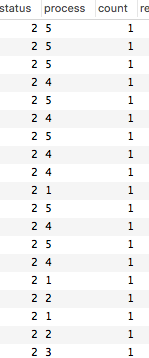
実装のポイント
status1にUPDATEする時にserver(自身のサーバー番号)をセットします。
クロールするジョブは、↑により、自身のサーバー番号がセットされたジョブのみとしました。
ジョブのステータスを1にする際に生のSQLでSELECTを行わずに[LIMIT 1]でUPDATEすることにより、selectとupdateのタイムラグを排除しています。
3.に関して補足
以下のようにactiverecordでwhereとupdateをメソッドチェインすることを考えましょう。
Job.where(process:nil,status:0).first.update(process:"local",status:1)
発行されるSQLは以下です。
DEBUG -- : Job Load (0.6ms) SELECT `jobs`.* FROM `jobs` WHERE `jobs`.`process` IS NULL AND `jobs`.`status` = 0 ORDER BY `jobs`.`id` ASC LIMIT 1
DEBUG -- : (0.3ms) BEGIN
DEBUG -- : Job Update (0.6ms) UPDATE `jobs` SET `process` = 'local', `status` = 1, `updated_at` = '2018-10-17 10:25:38' WHERE `jobs`.`id` = 88362
DEBUG -- : (1.4ms) COMMIT
Activerecordを使用した記述は1行であるために、発行されるSQLも1文と思いがちですが、実際のところ、
select/updateがそれぞれ発行されています。このタイムラグも処理の重複の原因になりますので、3.によってSELECTを発行せずにUPDATEを直接発行しています。
まとめ
以上のように、ActiverecordのようなORマッパーは、dbと完全に同期しているわけではありませんので、特にデリケートな処理を並列で行う際には注意しましょう。
また、開発時には、ORマッパーによって発行されるSQLを把握しましょう。Activerecordでは、以下の記述によって発行されるSQLが標準出力されます。
ActiveRecord::Base.logger = Logger.new(STDOUT)
RPA に関してプロジェクトをお考えでしたらぜひご相談ください。
CONTACT
お問い合わせ・ご依頼はこちらから