MAGAZINE
ルーターマガジン
ぽこぽこ界隈のブランドを集計をしてみた

yugoyamamotoです。
「ぽこぽこ界隈」というSNS動画界隈があります。界隈といいますが実際にはそういう動画編集フォーマットです。動画あたりの商品紹介の密度という点ではすばらしい発明です。教養として把握しておくべきフォーマットでしょう。今回はぽこぽこ界隈をAIに分析させてみるという実験をしてみました。
ぽこぽこ界隈の特徴
- BGM: シャボン玉が弾けるような「ぽこぽこ」という効果音や、水が泡立つような音が使われるのが最大の特徴で、これが「ぽこぽこ界隈」の名前の由来です。
- 動画内容: 美容やファッション、ショッピングなど、華やかで「丁寧な暮らし」をテーマにしたVlog(動画ブログ)が中心です。具体的な例としては、美容院やネイルサロンに行った様子、デパートでの買い物、高級ブランド品の開封、美容医療の施術風景などが挙げられます。
- 投稿者のスタイル: 投稿者自身の顔は映さず、後頭部や手元、持ち物など、映り込む範囲を限定していることが多いです。
主なターゲット層は若い女性となっています。TikTokで「# ポコポコ界隈」で検索して出てくる動画の中には100万再生を超える動画も多数存在し、一定の人気を得ています。
そこで今回は Gemini API を用いて、ポコポコ界隈のインフルエンサーがアップロードした動画の中から紹介されたブランドをリストアップし、ランキングを作成していきます。
以下のインフルエンサーを対象にサンプリングしました。
- あやかちゃん (323.8Kフォロワー、153投稿 2023-06-05~2025-09-15)
- rina (192.1Kフォロワ、104投稿 2021-08-28~2025-08-16 )
- Onnya (115.9Kフォロワー、135投稿 2024-02-06~2025-10-02)
いずれも多くのフォロワーとエンゲージを獲得しているアカウントとなっております。これらの投稿の成分を分析することで認知の流れを把握することができるかもしれません。
ぽこぽこ界隈のブランドを集計してみた
今回はシンプルにそれぞれのブランドが何回動画に登場したかをカウントしてみました。DIORとスターバックスがほぼダブルスコアをつけ他を圧倒しています。また、全体的に、コスメ・ファッション・カフェ系ブランドが多く、ユーザー層のライフスタイルや興味が反映されたランキングになっています。
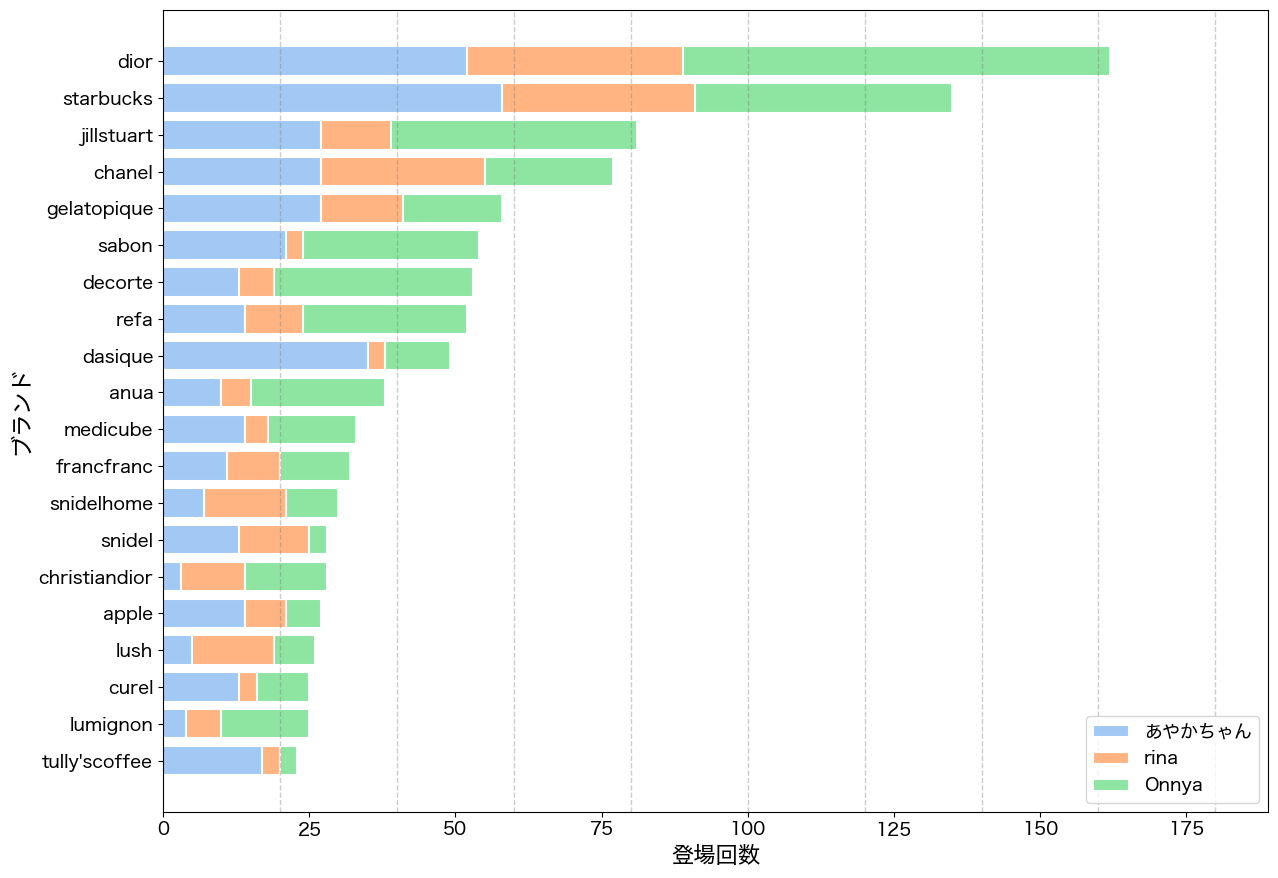
#PRをつけた投稿であっても、どの商品が案件なのかはもはや分かりません。特定のブランドが特定のアカウントに大量に露出しているというわけででもないのでいよいよ案件が絞れません。データとしては下位のランクまで収集できておりますので、素データにご興味がある方はお問い合わせください。
次に、それぞれのユーザーが1回の動画で幾つのブランドを紹介しているのかをみてみます。
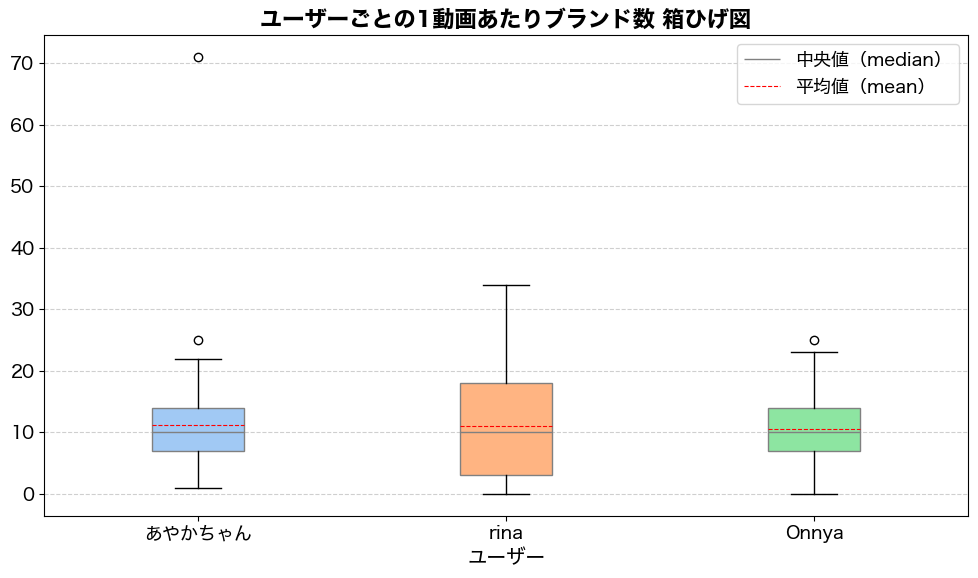
中央値が3人ともほぼ同じく10ブランドです。一分の動画で6秒に一回のペースです。rinaさんは暦が長いこともあってコンテンツのフォーマットにばらつきがありそうです。71ブランド紹介されているという異常値のような投稿がありますが、以下のように本当にブランドだらけの投稿です。 https://www.tiktok.com/@lw9om/video/7312038795539434760 Geminiで抽出した上限が71ブランドというだけで本気でさがせばもっとありそうです。
以降技術面での解説をします。
動画からブランドを抽出する方法
今回はREST APIを使用します。環境変数にAPIキーを登録しておけばドキュメントのコードのコピペで動作し、さらにシェルのヒストリーに履歴が残るのでREST APIのサンプルが学習面では使いやすいです。
以下が今回用いたコードの全文です。
VIDEO_PATH=$1
MIME_TYPE=$(file -b --mime-type "${VIDEO_PATH}")
NUM_BYTES=$(wc -c < "${VIDEO_PATH}")
DISPLAY_NAME=VIDEO
tmp_header_file=upload-header.tmp
echo "Starting file upload..." >&2
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D ${tmp_header_file} \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
echo "Uploading video data..." >&2
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${VIDEO_PATH}" 2> /dev/null > file_info.json
name=$(jq -r ".file.name" file_info.json)
file_uri=$(jq -r ".file.uri" file_info.json)
state=$(jq -r ".file.state" file_info.json)
echo "File upload initiated. File name: ${name}, uri: ${file_uri}" >&2
while [ "$state" != "ACTIVE" ]; do
echo "File is still processing. Current state: $state. Checking again in 5 seconds..." >&2
sleep 5
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" 2> /dev/null > file_info.json
state=$(jq -r ".state" file_info.json)
done
echo "File uploaded successfully. File URI: ${file_uri}" >&2
prompt="この動画で紹介されている商品のブランド名をリストアップしてください。"
echo "Generating content from video..." >&2
json_payload=$(cat <<EOF
{
"contents": [{
"parts":[
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": "${file_uri}"}},
{"text": "$prompt"}
]
}],
"generationConfig": {
"temperature": 0,
"responseMimeType": "application/json",
"responseSchema": {
"type": "OBJECT",
"properties": {
"brandList": {
"type": "ARRAY",
"items": { "type": "STRING" }
}
},
"required": ["brandList"]
}
},
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
}
EOF
)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d "${json_payload}" 2> /dev/null > response.json
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name?key=$GEMINI_API_KEY > /dev/null 2>&1
echo $(jq -r ".candidates[].content.parts[].text" response.json)基本的な流れとしては
- upload
- generateContent
の繰り返しになります。ではコードを一つ一つみていきましょう。
ファイルのアップロード
VIDEO_PATH="input.mp4"
MIME_TYPE=$(file -b --mime-type "${VIDEO_PATH}")
NUM_BYTES=$(wc -c < "${VIDEO_PATH}")
DISPLAY_NAME=VIDEO
tmp_header_file=upload-header.tmp
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D ${tmp_header_file} \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${VIDEO_PATH}" 2> /dev/null > file_info.jsonファイルのアップロードには Files API を使用します。Files APIは合計20GB以下のファイルを48時間保持してくれます。また、アップロード後48時間経つと自動でファイルは削除されます。
アップロードされたファイルの確認
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" 2> /dev/null > file_info.jsonファイルをアップロードしたら、そのファイルに関する情報を上記のコマンドで取得できます。レスポンスのjsonは以下のような形式になっています。
{
"name": "files/ad0dl4esoqfo",
"displayName": "VIDEO",
"mimeType": "video/mp4",
"sizeBytes": "26530956",
"createTime": "2025-09-24T09:03:41.487901Z",
"updateTime": "2025-09-24T09:03:41.487901Z",
"expirationTime": "2025-09-26T09:03:41.229743283Z",
"sha256Hash": "NmU1YWEyNDA5NDY2OWEwYzJlMDJlMzY4NmRiMzZiYTJiNTFlZmIwMTI3NTcwYmJlNDExOTU5YzM0YTA0ZmIzOA==",
"uri": "https://generativelanguage.googleapis.com/v1beta/files/ad0dl4esoqfo",
"state": "PROCESSING",
"source": "UPLOADED"
}このjsonをみると"state": "PROCESSING"となっていますが、ACTIVEになるまでこの動画を入力とした処理を実行できません。なのでそれまで待つ処理を追加しましょう。
動画を入力とした処理の実行
ここまでで動画のアップロードが終了したので、次はアップロードした動画を入力とした処理を行いましょう。Gemini APIでは 構造化出力 の機能を利用して、出力の形式をJSON Schemaで指定することができます。まずは今回のコードの該当部分を提示します。
json_payload=$(cat <<EOF
{
"contents": [{
"parts":[
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": "${file_uri}"}},
{"text": "$prompt"}
]
}],
"generationConfig": {
"temperature": 0,
"responseMimeType": "application/json",
"responseSchema": {
"type": "OBJECT",
"properties": {
"brandList": {
"type": "ARRAY",
"items": { "type": "STRING" }
}
},
"required": ["brandList"]
}
},
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
}
EOF
)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d "${json_payload}" 2> /dev/null > response.jsonjson_payloadの responseSchema で出力の形式を指定しています。また、safetySettingsで不適切な内容の不適切な出力をどこまで許容するかを設定することができます。
response.jsonは以下のようになります。 candidates->content->parts->text に指定した形式のjsonがあることが確認できます。
{
"candidates": [
{
"content": {
"parts": [
{
"text": "{\"brandList\": [\"BIJOU CLINIC\", \"UNA de RINGOL\", \"sien headspa\", \"SABON\", \"DIOR PRESTIGE\", \"ROSIER\", \"HOTEL FIZZY\", \"TWG\", \"MONIN\", \"Starbucks\"]}"
}
],
"role": "model"
},
"finishReason": "STOP",
"index": 0
}
],
"usageMetadata": {
"promptTokenCount": 18007,
"candidatesTokenCount": 59,
"totalTokenCount": 18294,
"promptTokensDetails": [
{
"modality": "TEXT",
"tokenCount": 12
},
{
"modality": "VIDEO",
"tokenCount": 16043
},
{
"modality": "AUDIO",
"tokenCount": 1952
}
],
"thoughtsTokenCount": 228
},
"modelVersion": "gemini-2.5-flash",
"responseId": "hTvXaNqEGaqBmtkPyq75-Ag"
}ファイルの削除
ファイルをアップロードしてから48時間後に自動的に削除されるとはいえ、連続で処理を行いたい場合は制限である20GBを超えてしまう可能性があるので都度削除をしておくのが安全でしょう。
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name?key=$GEMINI_API_KEY > /dev/null 2>&1動画とトークン数、精度の関係を調べる
次に入力の動画に対して、トークン数と精度がどのように変化するかを調べてみます。ベースの動画には60秒程度の長さのポコポコ界隈の動画をもちいて、
- 動画を加工せずに処理をする
- フレームを½に間引いてから処理をする
- 動画を2倍速にして処理をする
の3通りの方法でそれぞれ10回処理を行い平均を取ることで、トークンの消費量といくつのブランドを出力できるのかを検証していきます。モデルは2.5-flashです。
動画とトークン数、精度の関係を調べる
次に入力の動画に対して、トークン数と精度がどのように変化するかを調べてみます。ベースの動画には60秒程度の長さのポコポコ界隈の動画をもちいて、
- 動画を加工せずに処理をする
- フレームを½に間引いてから処理をする
- 動画を2倍速にして処理をする
の3通りの方法でそれぞれ10回処理を行い平均を取ることで、トークンの消費量といくつのブランドを出力できるのかを検証していきます。モデルは2.5-flashです。
早速結果です。
| トークン消費量 | 抜き出せたブランド数 | |
|---|---|---|
| 加工なし | 20723.4 | 16.5 |
| ½に間引き | 21396.8 | 15.6 |
| 2倍速 | 11374.1 | 11.3 |
間引きした動画と2倍速にした動画では精度に差が出ないのではないかと予想していたのですが、2倍速の場合のみ精度が低下したという結果となりました。どちらもフレーム1枚1枚をみると同じデータだと思うのですが、フレームレートが違いが精度に影響しています。
トークンの消費量は動画の長さに比例するようです。2倍速に加工する場合、精度の低下に対して消費されるトークンの節約量が大きいので、場合によっては2倍速に加工してから処理を行うのも悪くない選択肢になると思います。
モデルの選択
まずはモデルの値段表です。
| モデル | 価格(100万トークンあたり) |
|---|---|
| Gemini 2.0 Flash | $0.10 |
| Gemini 2.5 Flash-Lite | $0.10 |
| Gemini 2.5 Flash | $0.30 |
| Gemini 2.5 Pro | $1.25(20万トークン以下の場合) $2.50(20万トークンより大きい場合) |
次にモデルの精度です。先ほどと同じ動画に対してそれぞれのモデルで処理を行ってみました。
| モデル | トークン消費量(金額) | 抜き出せたブランド数 |
|---|---|---|
| Gemini 2.0 Flash | 19313.5(¥0.28) | 14.5 |
| Gemini 2.5 Flash-Lite | 20152(¥0.30) | 10 |
| Gemini 2.5 Flash | 20723.4(¥0.93) | 15.6 |
| Gemini 2.5 Pro | 21365.2(¥3.89) | 17.8 |
今回のタスクでは2.0-Flashがかなり善戦しているなといった印象です。2.5-Proは多少精度が高いようですが、金額とのバランスを考えると完全にオーバースペックだと思います。
いずれにせよ、かなりの精度でしかも安価に処理を行うことができており、技術の進歩を感じた次第です。
生成AIをメタデータ抽出の目的で使う
今回はGemini APIを用いてTikTokの動画で紹介されたブランドを集計してみました。ポコポコ界隈の動画はテンポが速いので、人の目で見ても判別の難しい商品も多数あったのですが、Geminiは高精度でそのブランドを判別してくれました。
このように、生成AIは創作用途での活用が注目されがちですが、要約のタスクも高い精度でこなすことができます。また、出力形式をJSONスキーマで指定することができるのでAIからの出力を用いて分析をすることが容易になるのも嬉しいポイントです。
生成AIのAPIはcurlコマンドで呼ぶ
生成AIを使ったサンプルコードの多くはPythonで記述されていますが、今回はcurlコマンドのみでサンプルを作っています。何もモジュールをインストールせずとも使えるという点でポータビリティーが高いです。URLも剥き出しなのでどのモデルを使ってるかも容易に把握できます。大きなファイルを扱うケースも多いため、できるだけバイトストリームをパイプをつないで処理をしたいという意図もあります。
CONTACT
お問い合わせ・ご依頼はこちらから