MAGAZINE
ルーターマガジン
PDFをデータベース化するコツ
PDFをスクレイピングしたいニーズは結構ある
山本ゆうごです。
PDFをスクレイピングしたいというご相談をうけることがあります。 構造化されたテーブルデータにスクレイピングするご相談もあれば、単に全文検索したいというニーズのケースも両方あります。
今回は単にPDFを検索するのための加工技術をご紹介します。
まずはPoppler
PDFを読み取るのに便利なツールがPopplerです。複数のコマンドがありますが、以下のツールを私は多用しています。
- pdftohtml (PDFをHTMLに変換)
- pdftotext (PDFをプレーンテキストに変換)
- pdfinfo (PDFの情報をみるだけ)
- pdftoppm (PDFをラスタイメージの画像に変換)
- pdftosvg (PDFをSVGに変換してパワポに貼りやすい形式に)
今回の検索用途では、pdftohtmlとpdftotextを使います。
日本郵政の統合報告書を検証対象にしてみる
日本郵政の統合報告書がありますので、これをサンプルに使います。 財務系のPDFであればほぼフォーマットが決まっているのですが、統合報告書のようなフリーフォーマットの文書は会社ごとに比較が難しいため、横断検索しがいがあります。
以下のサイトからダウンロードしてみます。
https://www.japanpost.jp/ir/library/disclosure/2023/pdf/int_all_01.pdf
全部で162ページあります。popplerを使ってテキスト抽出してみましょう。
まずはpdftotext
以下のようにプレーンテキストに変換します。
pdftotext int_all_01.pdfこれでプレーンテキストに変換されます。pdfと同じ階層に.txtファイルが生成されます。
ページ数も多いですが、先頭ページから最後のページまで変換できています。 単にデータベースのカラムとして突っ込むだけならこれでもある程度の用は足ります。
ただし、このような問題もでます。 ページ内にある「ツメ(小口のメニュー)」「フッター」なども全て取得してしまいます。
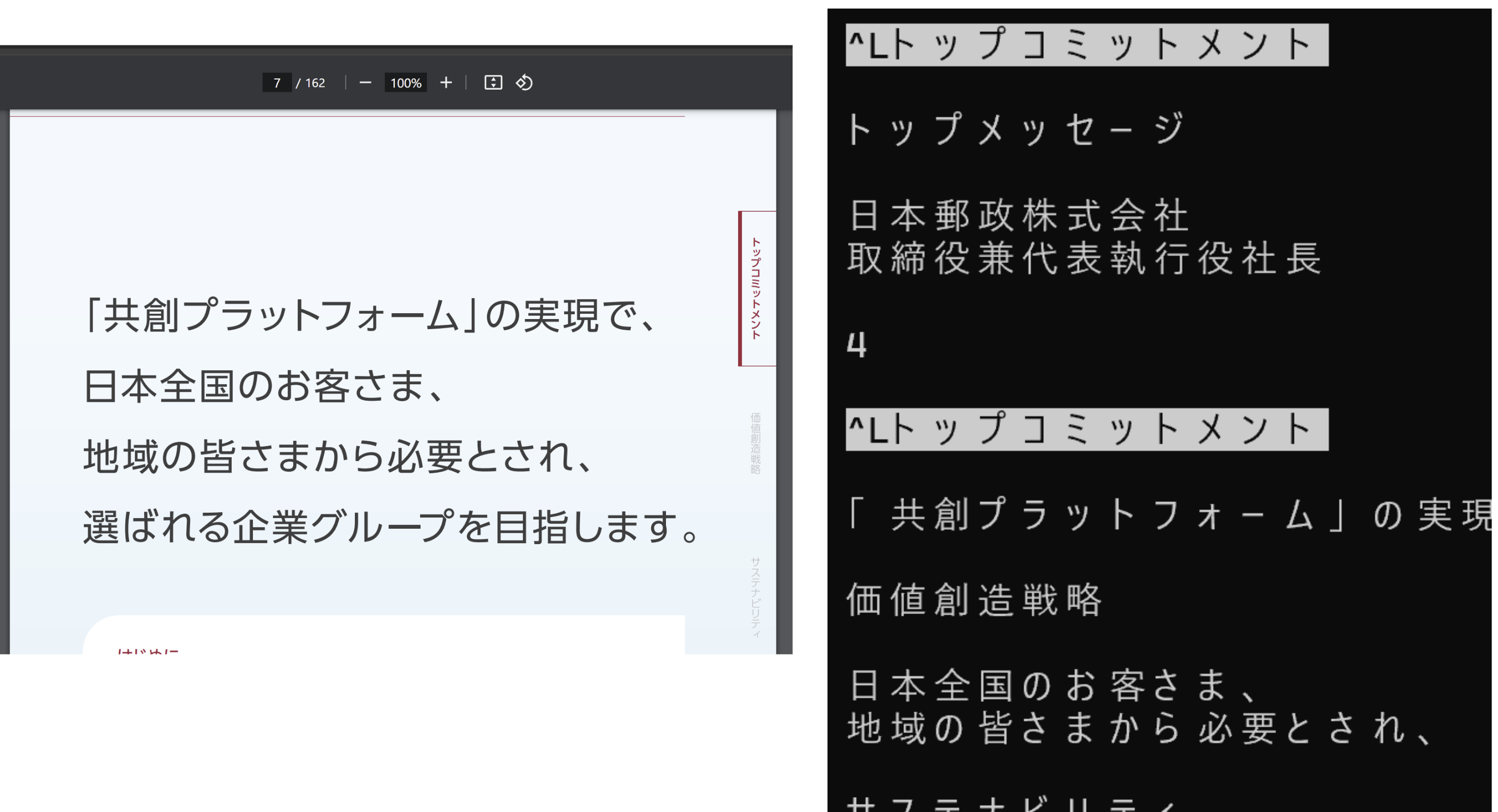
これはノイズです。特にツメやフッターは見出しと同様の文言が入るため、重要なテキストが入ります。
このような「ヘッダー/フッター/ツメ」を削除するためには、ページごとに比較をして同じ位置に同じものが入るものは削除すればいいということになりますが、プレーンテキストに変換してしまうと取り除くのは難しいです。
次はpdftohtml
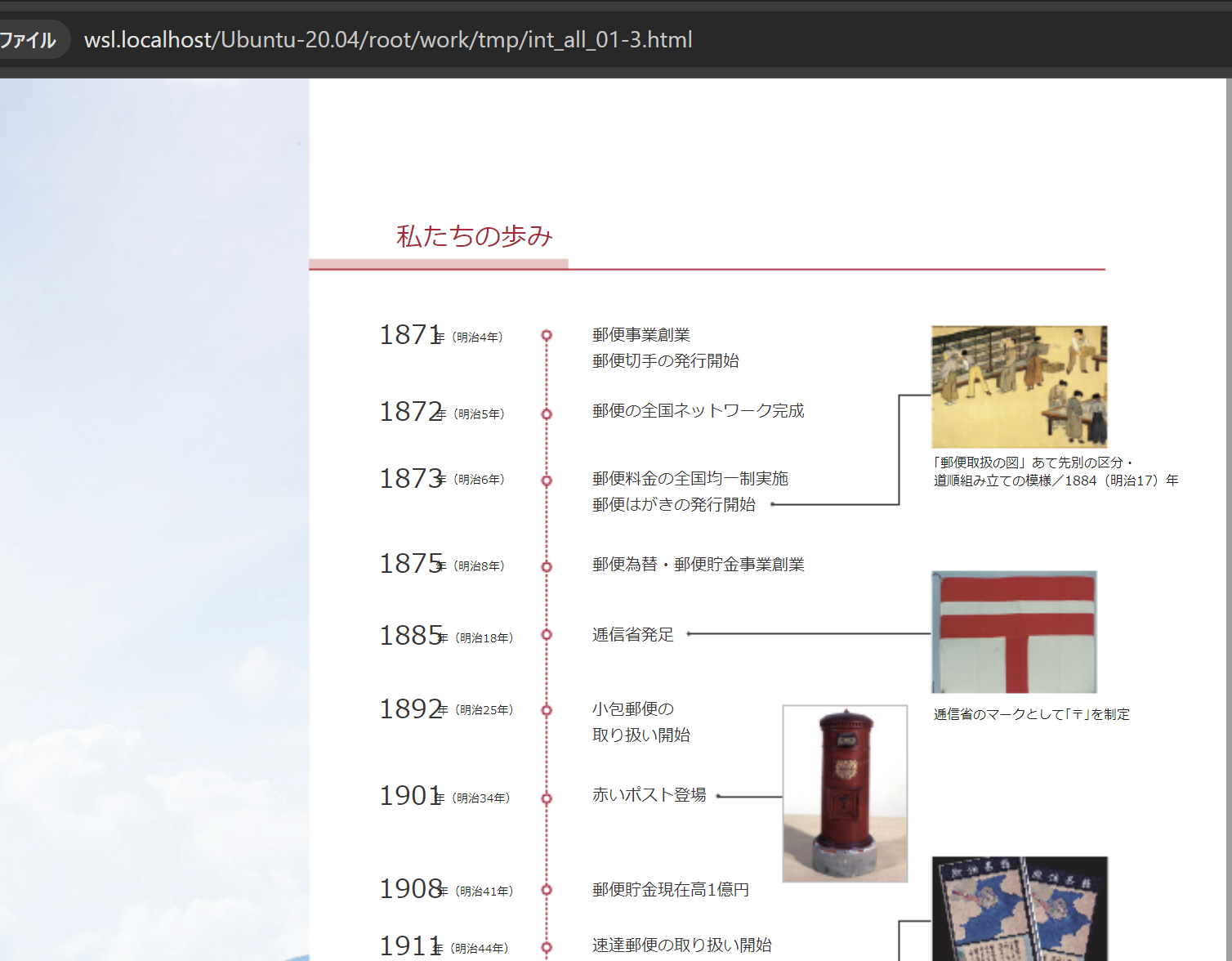
pdftohtmlはPDFをほぼみたまま再現してくれます。 先程のメニューも位置情報を保持したまま、HTMLにしてくれます。
pdftohtml -c int_all_01.pdfPDFの1ページをhtml1ファイルに変換してくれます。
レイアウトの再現性も高いです。
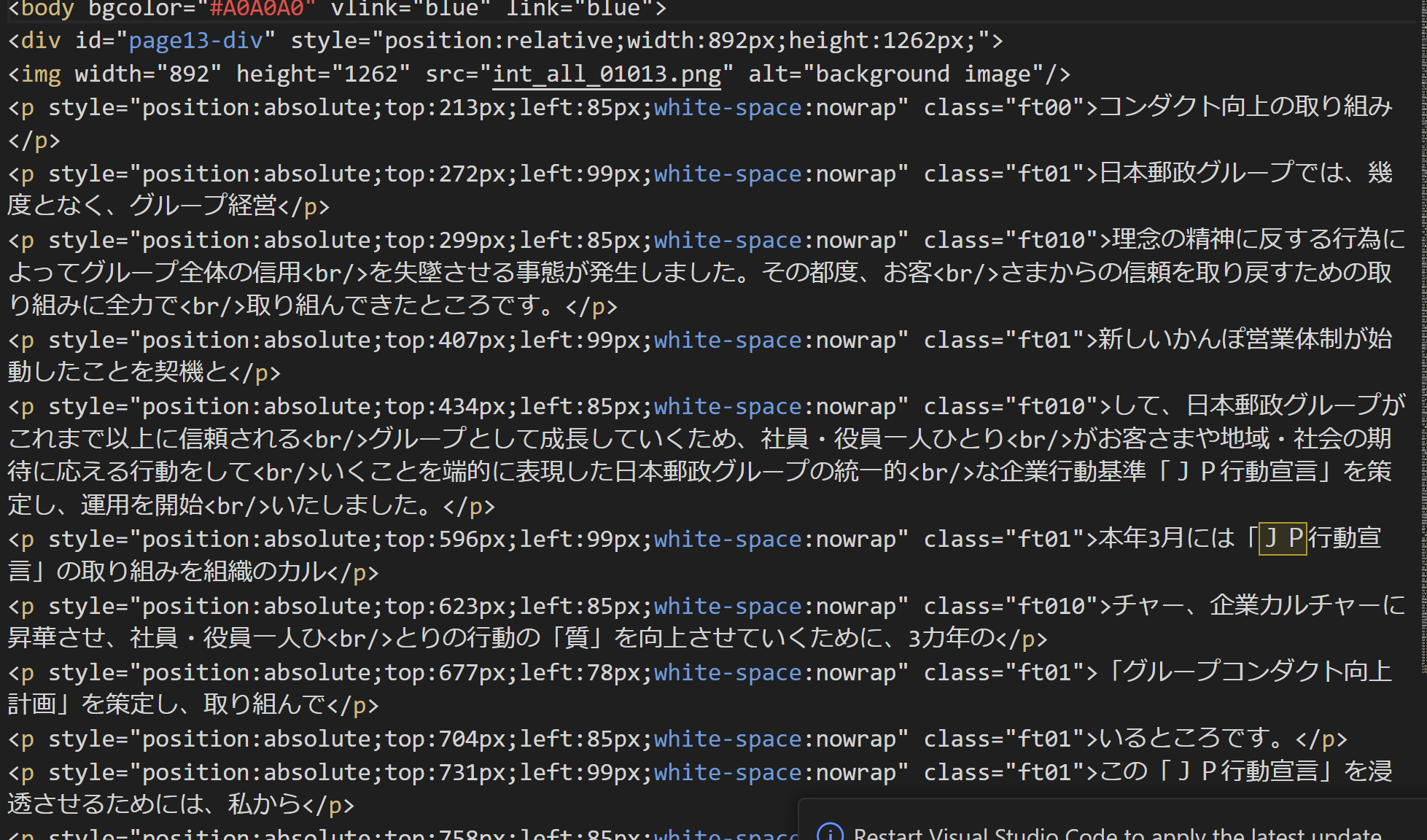
HTMLの中身は、絶対位置指定+クラス定義によるフォント指定というシンプルなHTMLです。
次は見出しか否かを判断
HTMLの場合、SEOを考慮して見出しタグの中に重要な単語を入れるケースがあります。見出しで記述している方が本文に登場することよりも重要度が高いはずです。pdftohtmlをした結果でも文字のフォントサイズはわかりますので、「◯pt以上の文字は見出し扱い」として見出しフィールドに入れるということが可能です。
フォントサイズを取得するには、window.getComputedStyle(element).fontSize を使うことでフォントサイズが取得可能になります。
以下サンプルJavaScriptです。
{
let iterator = document.evaluate('//text()', document, null, XPathResult.ANY_TYPE, null)
let textNode = iterator.iterateNext()
let textNodes = []
while (textNode) {
var parentStyle = window.getComputedStyle(textNode.parentNode, null)
var fontSize = parentStyle.getPropertyValue('font-size')
let top = parentStyle.getPropertyValue('top')
let left = parentStyle.getPropertyValue('left')
if (textNode.nodeValue != "\n"){
textNodes.push({top:top, left:left, fontSize: fontSize, nodeValue: textNode.nodeValue})
}
textNode = iterator.iterateNext()
}
console.log(textNodes)
}コンソールでの実行結果です。 見出しだけフォントサイズが大きいので区別可能です。
デバッグのしやすさを考えると、一旦はすべてのテキストノードをバラして、
- PDFファイル名
- ページ数
- x座標
- y座標
- テキスト
- フォントサイズ
を中間データとして持っておくといいでしょう。データベースに入れることで、フォントサイズでフィルタリングもできますし、ページをまたがって繰り返し登場する同じスタイル、コンテンツのノードも集計関数一発で取り出せます。
テーブル化してしまえば、あとはSQLだけで近いテキストノードを段落扱いすることも可能です。
まとめ
一時期は全てのドキュメントをXMLで表現することで、ヒューマンリーダブルとマシンリーダブルを共存させようという動きもありましたが、実際にはxmlを直接見れるIEも廃止されましたし、XHTMLも非推奨となりました。最低限のヒューマンリーダブルドキュメントとしてPDFが生き残りました。究極のヒューマンリーダブルドキュメントのPDFをマシンリーダブルにすることで、機械が人間に歩み寄る形でデータ共有ができるようになります。
がんばろう!
CONTACT
お問い合わせ・ご依頼はこちらから