MAGAZINE
ルーターマガジン
クローリング/スクレイピング
PDFファイルに生データを添付する方法
2025.03.21

データサイエンティスト泣かせのPDF
自治体や官公庁の多くはPDFで情報を公開しています。ところがPDFはほぼ印刷データに近いかたちで構造化データにはなっていません。エクセルやWordで無理やりPDFを開けばある程度は構造化データにはできますが、不完全です。
とはいえWordやExcelの生データを配布するというのもアプリが絞られすぎています。ブラウザの中で見れてしまうというPDFの利便性は「ポータブル」を名乗るだけの利便性はあります。CSVも同様で決め手となるビューワがあるわけではありません。
ということで、折衷案として「見る人はPDF、生データをほしい人は見れる」という「生データつきPDF」が作れない調べてみました。
以下Pythonのpikepdfというモジュールを使った添付ファイルを加えるサンプルソースです。 エクセルファイルとそれをPDFにした2つのファイル(内容としては同じ)を一つのファイルに纏めています。
import pikepdf
from pikepdf import AttachedFileSpec
from pathlib import Path
# PDFを開く
pdf = pikepdf.Pdf.open("sample.pdf")
# ファイルを添付
fs = AttachedFileSpec.from_filepath(pdf, Path('sample.xlsx'))
pdf.attachments['sample.xlsx'] = fs
# 保存
pdf.save("output.pdf")Acrobatで開くと添付ファイルとしてエクセルがみられます。
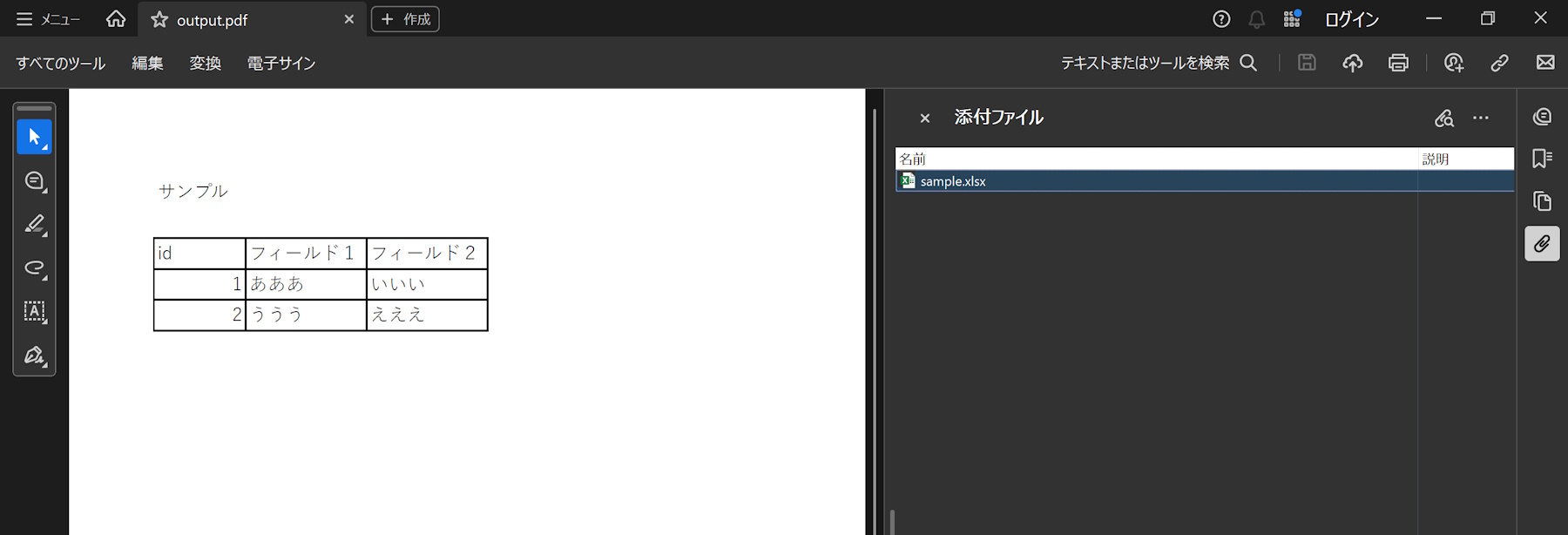
これ実用になる?
答え:いまいち
以下の理由で「やってみたけどいまいち」です。
- Chromeなどのブラウザで開いても添付ファイルがあるかどうかがわかりにくい
- Adobe Readerで開けば分かるけど、Adobe Readerの利用者が今は少ない
- pikepdfというライブラリでできることは分かったが、めちゃくちゃ事例が少ない。作ってる人も見てる人も少ない
- わざわざ一つのファイルにしなくても「元ファイルはこちら」として複数ファイルを管理すればいい
最終的には力技でPDFをパース
結局弊社では、PDFしか公開されてない場合でも自力でPDFを解析して、罫線の位置などを参考に元情報を作り出すということをしております。セル結合っぽい形で罫線が描かれている場合にも「多分両方のセルに情報がはいっていそう」ということを判断しながらデータ化しています。
CONTACT
お問い合わせ・ご依頼はこちらから