MAGAZINE
ルーターマガジン
クローリングする際に調整したいHTTPリクエストパラメータ
こんにちは! アルバイトのkondoです。
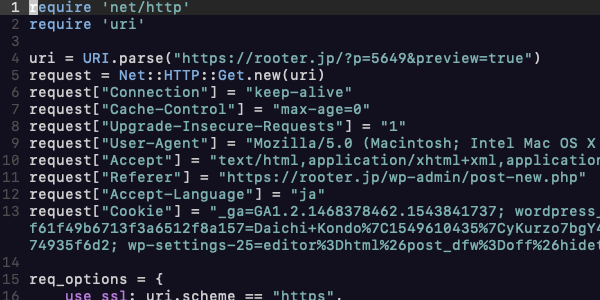
ルーターではクローリングの際にSeleniumやMechanizeを使うことが多いですが、httpリクエストを直接投げてデータを集めることもあります。
今回は、クローリング時に調整することの多いリクエストパラメータを紹介します。
また、実際にブラウザ上で行われているリクエストをruby上で再現するには、curl-to-rubyを使うと便利です。
マッハでクローラーを構築する(curl to ruby)
URL
URLを変えるといっても「パス」と「クエリパラメータ」の2種類があります。
パス
URLのパスとはURLの以下の所です。
https://rooter.jp/infra-ops/introduction-to-tmux
パスが日付順(2019/02/06)のようになっている場合や、
地名が入っている場合(東京都/千代田区)は、
コード上でこれらの値を少しずつ変えてあげるだけでOKだったりします。
クエリパラメータ
クエリパラメータとはこの下線の箇所です。
https://qiita.com/search?q=ruby
URLのパスに続いて?を置き、その後に変数=値の形で指定します。%エンコーディング
URLを変える際に注意しなければならないのは、パスやクエリパラメータに日本語文字を入れる場合は、エンコーディングをしたものを入れることです。
アルファベット以外の文字を入れる場合は、%エンコーディングという方式で文字をエンコードします。
RubyではURIクラスの以下のメソッドで変換できます。
URI.encode_www_form_component('クローリング') #=> E3%82%AF%E3%83%AD%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0
ブラウザでは日本語文字もデコード後の読める文字で表示されていますが、Rubyコード上ではエンコードした文字を使いましょう。
ヘッダ
基本的にはcURL-to-rubyでできたコードそのままで大丈夫ですが、一部注意するヘッダがあります。
User-Agent
このヘッダでは、リクエストを送ったブラウザや機器などの情報が入っています。
パソコン(Mac)のChromeから送った場合は以下のようになり、
["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"M
スマホのChromeから送ったときはこのようになります。
["User-Agent"] = "Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36"
サイトによってはこのヘッダを判断して返すリソースを変えてくることがありますので、複数人での開発ではこのヘッダを統一すると安心です。
If-Modified-Since
If-Modified-Sinceヘッダは具体的にはこのように指定します。
["If-Modified-Since"] = "Mon, 21 Jan 2019 10:25:25 GMT"
これは、
「2019年1月21日の10:25以降にサイトの情報が更新されていたらリソースを返してね。更新されていないならブラウザのキャッシュを使うから何も返さなくていいよ」
という意味です。これにより本来は無駄な通信が抑えられるのですが、クロールの際にはキャッシュは無いので指定すべきではありません。
ブラウザでページを更新した2度目以降のリクエストで現れてしまうので、もしこのヘッダがあったなら消してあげましょう。キャッシュの利用を指定するヘッダは他にもあるので、調べてみてください。
Cookie
ログイン状態などを保存しているCookieですが、curl-to-rubyで得たCookieの期限はしばらくすると切れてしまいます。ですので、ログインはSeleniumやMechanizeで行い、そこからCookieを受け取り、Cookieヘッダに入れてhttpリクエストを直接送る、という方法があります。(httpリクエスト直送りだけでログインを行うのは大変です)
MechanizeやSeleniumからCookieを取得する方法は以下の記事に詳しく書いてあるので参考にしてみてください。
Mechanize : mechanizeによるクローリング/スクレイピング入門
Selenium : Selenium x Chromeのクローラー自動操縦開発を効率化するツールpraniumを作りました
おわりに
httpリクエストはメモリの使用量も少なくお手軽ですが、これだけで複雑なことをしようとするとかなり面倒になります。
手段を適切に見極めて、時にはそれらを混ぜつつ上手くクロールできたら嬉しいですね。
CONTACT
お問い合わせ・ご依頼はこちらから