MAGAZINE
ルーターマガジン
RubyでHTTP GET/POSTリクエストする方法
はじめまして、ルーターのAraoです。先日のSakaeの後を受け、2記事目を書かせていただきます。
今回は、RubyでHTTP GET/POSTリクエストする方法について
- そもそもHTTPって何なの?
- GET/POSTリクエストとは?
- RubyでGET/POSTリクエストする様々な方法
の順に、簡単に解説していこうと思います。
そもそもHTTPって何なの?
HTTPとは
例によってWikipedia先生に頼ってみましょう。
Hypertext Transfer Protocol(ハイパーテキスト・トランスファー・プロトコル、略称 HTTP)とは、HTMLなどのコンテンツの送受信に用いられる通信プロトコルである。主としてWorld Wide Webにおいて、WebブラウザとWebサーバとの間での転送に用いられる。
出典:Hypertext Transfer Protocol - Wikipedia
とのことです。プロトコルは日本語だと議定書などと訳される単語なので、「僕たちはこういうルールでコンテンツの送受信を行うよ」、という取り決めがHTTPだと思ってもらえれば問題ありません。
おそらくこの記事を読んでいる皆さんのほとんどは、Webブラウザでこのページを開いて読んでいることと思います。その際にHTTPのことを意識した方はほとんどいないんじゃないでしょうか。それぐらい身近で、無意識のうちに使われているのが、このHTTPです。
HTTP、Webサーバの特徴
HTTPとWebサーバについて詳しく解説しようとすると日が暮れてしまうので、今回の記事に関連する特徴だけ紹介します。
先ほど、HTTPは主にWebブラウザとWebサーバとの間での転送に用いられるとありました。WebブラウザからWebサーバに向けて投げられる、「このコンテンツが欲しい」、「こういう操作をしたい」などといった、HTTPに従ったリクエストのことを、HTTPリクエストと呼びます。このとき、Webサーバは、Webブラウザの状態を保持する機能を持ちません。つまりどういうことかと言うと、「私は会員サイトにログインしているよ」などといった状態を、ページ遷移などのHTTPリクエストに含める必要があるということです。クライアントのログイン状態の管理には、よくCookieが使われます。そしてそのCookieなどの情報は、HTTPリクエストのヘッダーに含まれています。
逆に言えば、ヘッダーなども含めて全く同じHTTPリクエストをWebサーバに投げれば、それがブラウザからのリクエストであろうと、cURLからのリクエストであろうと、Rubyスクリプトからのリクエストであろうと、全く同じレスポンスがWebサーバから返ってくるということです。
GET/POSTリクエストとは?
先ほど紹介したHTTPリクエストは、いくつかのメソッドに分類されます。そのメソッドのうち、非常によく使われるものが、GETとPOSTです。実は他にも、PUTやDELETEなどといったメソッドがあるのですが、実際のところほとんど使われていません。そのため、ここではGETとPOSTについてのみ説明します。
GETリクエストとは、主にWebサーバから何らかのコンテンツを受け取りたいときに用いられるリクエストです。WebブラウザのアドレスバーにURLを入力し、Enterキーを叩くと、GETリクエストが実行され、Webサーバからhtmlを受け取ります。
POSTリクエストとは、主にWebサーバへ何らかの情報を送りたいときに用いられるリクエストです。会員サイトのログインフォームにログインIDとパスワードを入力して、ログインボタンを押すと、ログインIDとパスワードがWebサーバに送られます。もちろんこの場合でも、Webサーバからは何らかのコンテンツがレスポンスとして返ってきます。
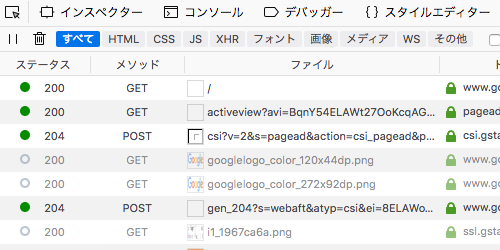
Webブラウザの開発ツールのネットワークタブを開くと、どのようなHTTPリクエストが実行されたか確認することができます。画像は、FirefoxでGoogleトップページを開いたときのものです。GETリクエストとPOSTリクエストがいくつも実行されていることがわかります。
RubyでGET/POSTリクエストする様々な方法
net/http
Ruby標準ライブラリに、net/httpというライブラリがあります。このライブラリは名前の通りHTTP通信をサポートするライブラリなので、これを利用することで、GETリクエストやPOSTリクエストを実行できます。
library net/http (Ruby 2.5.0)open-uri
同じくRuby標準ライブラリに、open-uriというライブラリがあります。このライブラリは、ファイルをオープンする際に使用するRuby標準のopenメソッドを拡張し、手軽にhttpアクセスを行えるようにするライブラリです。GETリクエストだけ実行できれば十分な、単純ななWebクローラーの場合は、net/httpよりもこちらの方が適しています。ちなみに内部的には、open-uriはnet/httpをラップしています。
library open-uri (Ruby 2.5.0)Mechanize
こちらは既に紹介した2つとは異なり、gemとして提供されているライブラリです。こちらもopen-uriと同様に、net/httpをラップしています。せっかくなので、Rubygemsに掲載されている、Mechanizeの概要を読んでみましょう。
The Mechanize library is used for automating interaction with websites. Mechanize automatically stores and sends cookies, follows redirects, and can follow links and submit forms. Form fields can be populated and submitted. Mechanize also keeps track of the sites that you have visited as a history.
出典:mechanize | RubyGems.org | your community gem host
ざっくりと和訳してみるとこんな感じでしょうか。
MechanizeはWebサイトとのやり取りの自動化に使われます。Mechanizeは、自動でcookieを管理し、リダイレクトのフォロー、リンクのフォロー、フォームの送信を行います。フォームフィールドにデータを入力し送信することができます。Mechanizeはアクセスしたサイトの履歴も保持します。
要約すると、Webブラウザが持つ様々な機能(cookieの管理、リダイレクトのフォロー、フォームにデータを入力して送信、履歴の管理)を行うことができる、ということです。cookieを勝手に管理してくれるのが非常に便利で、このおかげでログインが必要な会員サイト上の操作も、簡単に自動化できます。
どういうものかイメージしやすいように、Mechanizeを用いて、GETリクエスト、ログインフォームの入力と送信(POSTリクエスト)、フォーム送信とは別のPOSTリクエストを実行するサンプルスクリプトを掲載しておきます。もし会員サイト上の操作を自動化したいときは、こちらのサンプルスクリプトを参考に、自分だけのスクリプトを作ってみてください。
サンプルスクリプト中に登場するNokogiriやCSRFトークンの説明は、今回は割愛します。Nokogiriはhtmlをパースするのに用いるgemで、RubyでWebスクレイピングする場合のほぼ必須アイテムなので、後々紹介記事を書くかもしれません。また、MechanizeはNokogiriをラップしているため、Mechanizeを使うときはNokogiriをrequireする必要はありません。
require 'mechanize'
#### agent(ブラウザの代わり)の初期設定
agent = Mechanize.new
# Mechanizeクラスのオブジェクトを作成
agent.max_history = 2
# 保持する履歴の最大数。大きいとメモリを食いつぶし、0だとリファラー周りで不都合があるため、2あたりが妥当
agent.user_agent_alias = 'Mac Firefox'
# HTTPリクエストのヘッダーに、それっぽいUser-Agentを含めるように設定
#### GETリクエスト ログインページの取得
login_page = agent.get('https://www.example.jp/login/')
# ログインページのURLを指定
#### POSTリクエスト ログインフォームの入力と送信
login_form = login_page.form_with(name: 'loginForm')
# ログインフォームを特定して指定
login_form.userId = 'user_id'
# userIdという名前のフィールドに'user_id'と入力
login_form.password = 'password'
# passwordという名前のフィールドに'password'と入力
sleep 1
# 短時間に大量のリクエストを投げないようにするため、アクセス間隔の調整
my_page = login_form.submit
# ログインフォームを送信して、マイページを取得
#### フォーム送信とは別のPOSTリクエストの実行
my_doc = Nokogiri::HTML(my_page.body, nil, 'UTF-8')
# htmlのパース用
csrf_token = my_doc.at_css('meta[name="csrf-token"]').attr('content')
# 複数あるmetaタグのうち、CSRFトークンが含まれるものを特定してCSRFトークンを取得
request_body = {
'name' => 'miso-ramen',
'date' => '20180401',
'price' => '780'
}
# POSTリクエストのボディに設定したい情報をハッシュで用意する。実際にPOSTされるときは、Mechanizeの機能でJSONに変換される
request_header = {
'X-CSRF-Token' => csrf_token
}
# POSTリクエストのヘッダーに設定したい情報をハッシュで用意する。User-Agentは設定済み。cookieやリファラーはMechanizeの機能で自動で設定される
sleep 1
# アクセス間隔の調整
result_page = agent.post('https://www.example.jp/register/', request_body, request_header)
# 第一引数にPOST先URL、第二引数にリクエストボディ、第三引数にリクエストヘッダーを設定
こんな感じのスクリプトを書いてあげることで、会員サイトへログインし、POSTリクエストで何らかの情報を登録するという一連の操作を自動化することができます。
さいごに、RPAへの応用
RubyでHTTP GET/POSTリクエストする方法について、駆け足にはなってしまいましたが、一通り紹介してみました。前回の記事と合わせて、勘の良い方ならお気付きでしょうが、最後のサンプルスクリプトは人間がブラウザを操作して行う作業を自動化する、まさにRPAそのものだったりします。弊社では、このようなブラウザ操作を自動化するサービスも提供しているので、興味のある方は是非一度ご相談ください。
CONTACT
お問い合わせ・ご依頼はこちらから