MAGAZINE
ルーターマガジン
クローリング/スクレイピング
UTF8の絵文字を削除する方法
2025.05.09
UTF8には3種類ある
UTF8と一言で言っても業務上は3つの分岐が発生します
- BOMなしUTF8
- 一般的なUTF8ですね
- BOMありUTF8
- 「CSV拡張子のファイルをダブルクリックしてエクセルで文字化けせずに開かせたい」ときのUTF8です
- 逆にそれ以外ではBOMは「見えないおまじない」は邪魔になるのでBOMつけておけば大丈夫とはなりません
- 3バイトまで縛りののUTF8処理系
- これが伏兵で厄介です
- 今回のテーマは3バイトまでのUTF8処理系に対応させる前処理をお話します
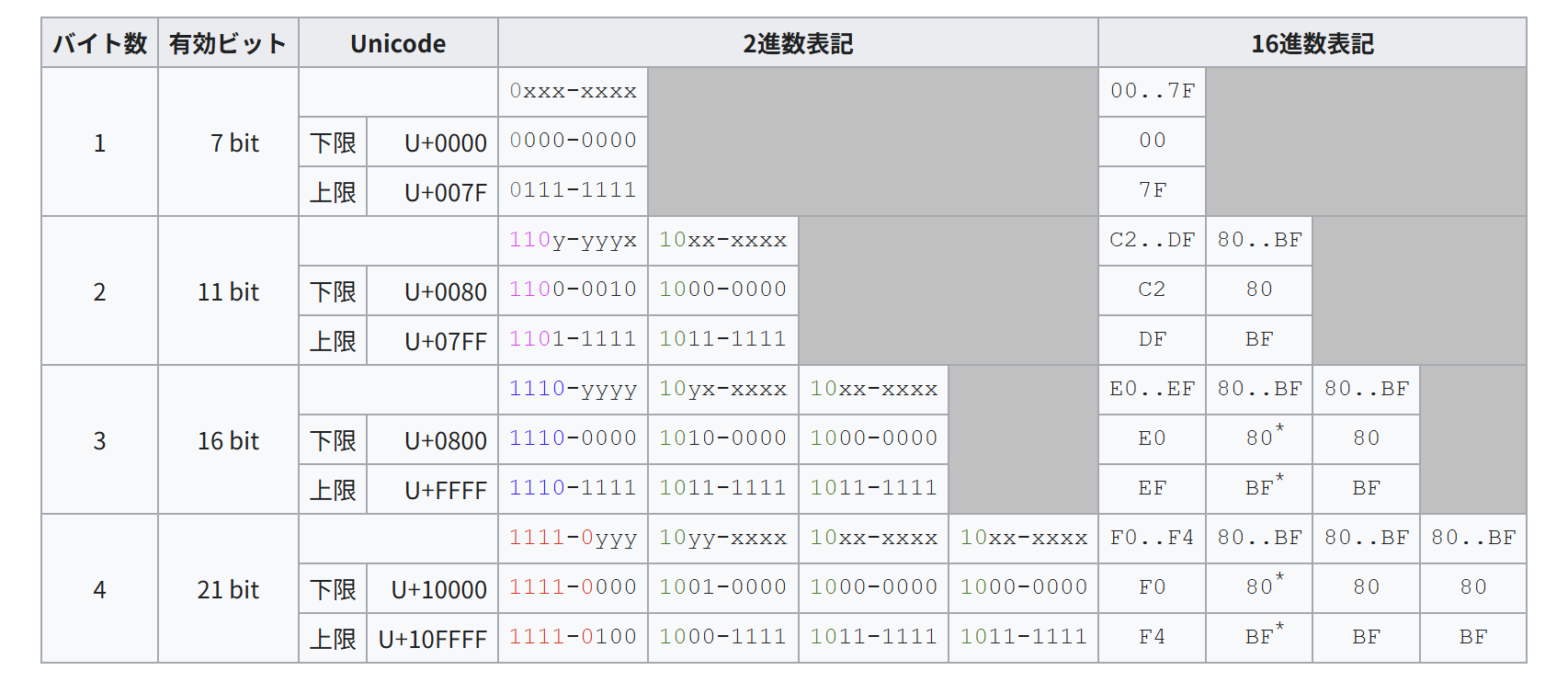
そもそもUTF8って何バイト?
最大4バイトです。対応するUNIOCODEの最大がU+10FFFFなのでそれ以上の対応がありません。
ただし大半は3バイトまでで収まるため、4バイトのUTF8が混じってくることは稀です。 そのため3バイトまでしか対応してない処理系であることに気づきにくいです。
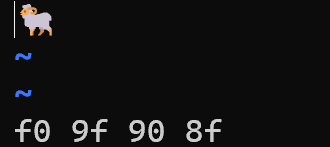
例えば羊「🐏」の絵文字をvimで確認してみると(g8をタイプするとutf8文字コードが見れます)4バイトです。
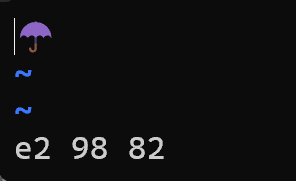
☔の絵文字は3バイトなので絵文字だからといって4バイトではありまえせん。
業務上は交じることは殆どありませんが、インターネット上のコンテンツをスクレイピングしていたりすると4バイト絵文字はたくさん混じってきます。
業務上は「絵文字が入ってくると処理がコケるのでなんとかして欲しい」という要望が来ますが「3バイトまでしか許容していない処理系なので4バイトのUTF8を削除してほしい」と翻訳して設計に落とします。
さらにUTF8ではなくUNICODEコードポイントとしてFFFFまでを許容すると解釈します。 大半のスクリプト言語はUTF8を文字列として解釈した際にはUNICODEコードポイントで指定できますので、「UNICODEコードポイントとしてFFFFを超える文字を削除」という正規表現で大丈夫です。
ということでこれが「絵文字が入ってくると処理がこけるのでなんとかしたい」のミニマムのコード例となります。
ruby
irb(main):001> "あ🐏☂".gsub(/[^\u0000-\uFFFF]/,'')
=> "あ☂"python
>>> re.sub("[^\u0000-\uFFFF]","","あ🐏☂")
'あ☂'本当は「処理できないから削除」ではなく別の文字にしたほうが良いのだとは思いますが、言葉として意味があるケースが殆どないため、削除で済ませるケースが多いです。
CONTACT
お問い合わせ・ご依頼はこちらから