MAGAZINE
ルーターマガジン
Ruby
[入門編] Nokogiriで画像URLを抽出し、画像ファイルをローカルにダウンロードする
2021.06.04

はじめに
はじめまして、学生エンジニアのshimizuです。
このブログではNokogiriのcssメソッドを使ってWebサイト内の画像を特定し、ダウンロードします。
今回は米国証券取引委員会 (U.S. Securities and Exchange Commission)のウェブサイトを例として、掲載記事の見出し画像をダウンロードします。
なお、この 米国証券取引委員会 (U.S. Securities and Exchange Commission)はサイトへのアクセスについて以下のように掲示しています。
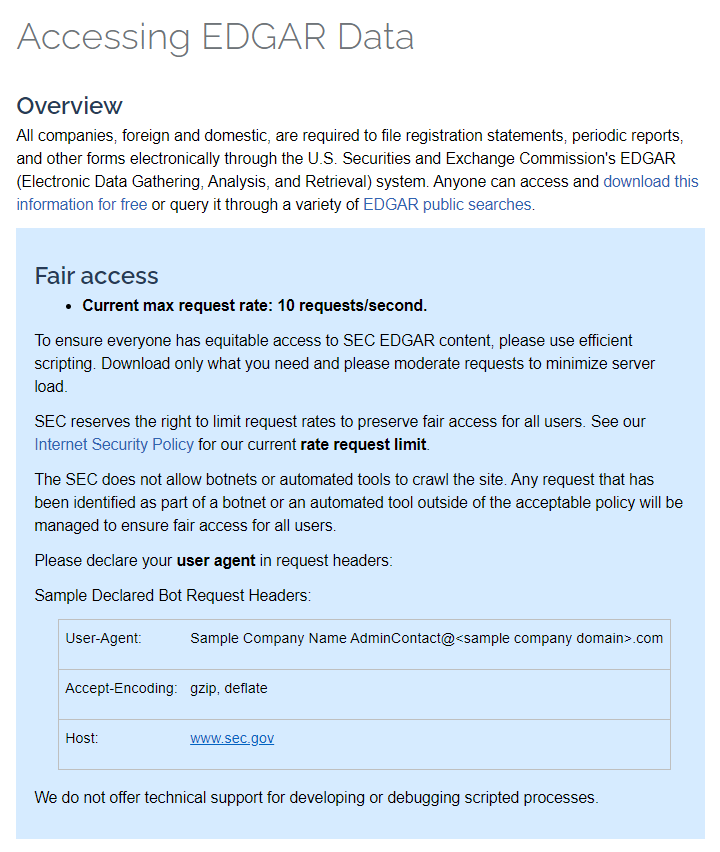
ここでは、サイト内からの必要な情報のダウンロードを許可すること、最大で1秒間に10回のリクエスト送信を許容することなどが書かれています。
スクレイピングをする際は、Webサーバ側への負荷を最小限に調整するなど、迷惑になることのないように十分に注意しましよう。
プログラム
準備として、ダウンロードした画像を保存するフォルダを作成しておきましょう。以下では'./download_imgs/'としています。それでは以下にプログラムを記載します。
require 'open-uri'
require 'nokogiri'
sec_url = 'https://www.sec.gov/'
download_key = './download_imgs/' # ダウンロード画像を入れるディレクトリ
# urlを開き、Nokogiriでパース
sleep 1
html = URI.open(sec_url).read
doc = Nokogiri::HTML.parse(html)
# 目的画像のリンクを取得し、配列target_img_urlsに入れる
target_img_urls = []
doc.css('.featured-graphic img').each do |node|
target_img_urls << sec_url + node.attribute('src').value.to_s
end
# 画像のリンクを開き、ダウンロードする
target_img_urls.each.with_index(1) do |url, index|
File.open(download_key + index.to_s + '.jpg', 'wb') do |img| # 拡張子は'.jpg'または'.png'にする
sleep 1
img.write(URI.open(url).read) # 画像をダウンロード
end
puts "#{index}枚目の画像をダウンロードしました."
end
puts 'ダウンロードが完了しました.'このプログラムは3つの機能に分けられます。
- 対象のサイトURLを開き、HTMLをNokogiriでパースする
- Nokogiriのcssメソッドも使って画像のURLを取得する
- 取得した画像URLから、画像をダウンロードする
今回スクレイピングするサイトでは、画像の特定を
doc.css('.featured-graphic img')で行っています。
実行結果
プログラムを実行すると、画像がダウンロードされていきます。
1枚目の画像をダウンロードしました.
2枚目の画像をダウンロードしました.
3枚目の画像をダウンロードしました.
4枚目の画像をダウンロードしました.
5枚目の画像をダウンロードしました.
6枚目の画像をダウンロードしました.
7枚目の画像をダウンロードしました.
ダウンロードが完了しました.
無事ダウンロードできました。よかった。
さいごに
このプログラムを利用して別の画像を指定してダウンロードする場合は、cssセレクタを変更します。対象に応じたタグや属性を指定すれば、割と応用が効くのではないでしょうか。
スクレイピングの入門的な処理ですが、ぜひこのブログを参考までに。
CONTACT
お問い合わせ・ご依頼はこちらから