MAGAZINE
ルーターマガジン
chrome_remoteのRuntime.evaluateを用い、ブラウザ上でJavaScriptを評価してテキストを取得する
皆さん、こんにちは。エンジニアのHatanoです。
ブラウザ自動操縦でHTMLから特定のテキストを取得する際、クロールしたHTMLに対しNokogiriなどを使ってRubyで扱えるようにパースを行い、そこからCSSセレクタやXPathを用いて処理する方法が一般的です。
しかし、この方法だと、HTML全体を確認する必要が無い場面でも「Rubyで変数にHTML全体を代入 → nokogiri等で全体をパース → 確認したいテキストの抽出」の流れを行うこととなり、メモリのオーバーヘッドが大きくなってしまいます。
今回は、自動操縦したGoogle Chrome上のHTMLに対し、chrome_remoteのメソッドを用いて、「ブラウザ側でテキストを抽出 → 抽出されたテキストをRubyで取得」の流れでテキストを取得する方法について紹介します。
環境・実行条件
- Ubuntu 22.04.5 LTS
- Google Chrome 138.0.7204.168
- Ruby 3.1.3p185
- chrome_remote 0.3.0
コードの実行前に、Google Chromeをdebugging-portを9222に指定した上で起動しておく必要があります。
なお、取得を行う場面において、取得元として弊社サイトのトップページを用いています。この記事では、最初のh2タグのテキストの取得を目的とします。
CSSセレクタを用いたパース
CSSセレクタによるパースを行う場合、Runtime.evaluateメソッドを用いて次のように行います。
require 'chrome_remote'
browser = ChromeRemote.client(port:9222)
browser.send_cmd("Page.enable")
# rooterのページへ遷移
rooter_url = 'https://rooter.jp/'
browser.send_cmd('Page.navigate', url: rooter_url)
sleep 3
# CSSセレクタによるパース
css_h2 = browser.send_cmd('Runtime.evaluate', expression: 'document.querySelector("h2").textContent')
puts css_h2
puts css_h2.dig('result', 'value')実行結果
{"result"=>{"type"=>"string", "value"=>"データの海をわたろう!"}}
データの海をわたろう!ここではChromeRemoteのsend_cmdメソッドを利用し、Chrome Devtools Protocol(CDP)の各メソッドを実行させています。
CDPのRuntime.evaluateメソッドは与えたJavaScriptを評価した値を取得します。
これにより、document.querySelector("h2").textContentの返り値である最初のh2タグのテキストを取得することが出来ました。
XPathを用いたパース
XPathによるパースを行う場合も、CSSセレクタの場合と同様にRuntime.evaluateメソッドを用いて次のように行います。
require 'chrome_remote'
browser = ChromeRemote.client(port:9222)
browser.send_cmd("Page.enable")
rooter_url = 'https://rooter.jp/'
browser.send_cmd('Page.navigate', url: rooter_url)
sleep 3
# XPathによるパース
XPath_h2 = browser.send_cmd('Runtime.evaluate', expression: "document.evaluate(
'(//h2)[1]',
document,
null,
XPathResult.STRING_TYPE,
null)['stringValue']"
)
puts XPath_h2
puts XPath_h2.dig('result', 'value')実行結果
{"result"=>{"type"=>"string", "value"=>"データの海をわたろう!"}}
データの海をわたろう!流れは先程と同じですが、XPathを使ってテキストを取得する段階でdocument.evaluateメソッドを用いています。
これにて、CSSセレクタ, XPathのそれぞれを用いて指定したテキストを取得することが出来ました。
XPathを用いる場合の注意点
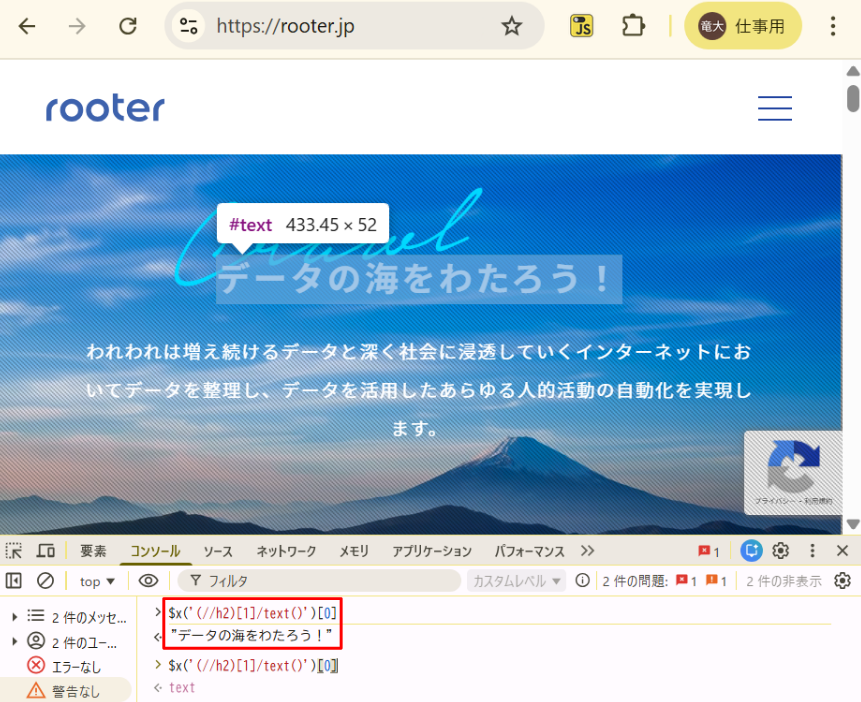
ChromeのDevToolsのコンソールタブでは、$xメソッドを用いた以下のコードにより、最初のh2タグのテキストを取得することが出来ます。
$x('(//h2)[1]/text()')[0]実行結果
しかし、これをRuntime.evaluateの引数としても、値を取得することは出来ません。
require 'chrome_remote'
browser = ChromeRemote.client(port:9222)
browser.send_cmd("Page.enable")
rooter_url = 'https://rooter.jp/'
browser.send_cmd('Page.navigate', url: rooter_url)
sleep 3
# xpathによる取得
xpath_h2 = browser.send_cmd('Runtime.evaluate', expression: "$x('(//h2)[1]/text()')[0]")
puts xpath_h2
puts xpath_h2.dig('result', 'value')実行結果
{"result"=>{"type"=>"object", "subtype"=>"error", "className"=>"ReferenceError", "description"=>"ReferenceError: $x is not defined\n at <anonymous>:1:1", "objectId"=>"-1292888766349649932.32.1"}, "exceptionDetails"=>{"exceptionId"=>344, "text"=>"Uncaught", "lineNumber"=>0, "columnNumber"=>0, "scriptId"=>"1101", "exception"=>{"type"=>"object", "subtype"=>"error", "className"=>"ReferenceError", "description"=>"ReferenceError: $x is not defined\n at <anonymous>:1:1", "objectId"=>"-1292888766349649932.32.2"}}}これは、$xメソッドがブラウザのDevTools以外では定義されていない事が原因です。 このため、XPathで特定の要素を取得できるかDevToolsでテストする場合には$xメソッドが有効ですが、実際にHTMLをパースする際は$xメソッドではなくdocument.evaluateメソッドを使う必要があります。
おわりに
HTMLをJavascriptでパースした結果を直接取得出来ると、ruby側でHTMLをテキストにパースする手間が省けて便利です。
是非一度試してみてください。
CONTACT
お問い合わせ・ご依頼はこちらから