MAGAZINE
ルーターマガジン
NokogiriでHTMLを対象に深さ優先探索
こんにちは。エンジニアのAraoです。今回は、NokogiriでHTMLをパースするときに、深さ優先探索を実施する方法を紹介します。
何故深さ優先探索か
Webスクレイピングの際に、対象となるHTMLがどのような形式か事前に分かっていれば、対象HTMLのどの部分を見れば取得したい情報が得られるかも分かるため、その部分を取得するようなコードを書けばOKです。しかし、対象となるHTMLがどのような形式か事前に分からない場合、取得したい情報がどの部分にどのように書かれているか、推測しながら情報の取得を行うようなコードを書く必要があります。
HTMLは木構造と呼ばれるデータ構造を持っていると考えることができるため、HTMLの全探索方法として、深さ優先探索を行うことにしました。
木構造とは
木構造 (データ構造) - Wikipediaグラフ構造の中でも、ノードとノードの間に親子関係を持つようなものを木構造と呼ぶ、と理解しておけば、この記事のレベルでは問題ありません。名前の通り木に例えているので、親を持たないノードを根、子を持たないノードを葉と呼んだりします。HTMLの場合、タグAの内側にタグBやテキスト1があると、タグAの子はタグBとテキスト1、逆にタグBの親はタグA、テキスト1の親はタグA、と考えることができます。
深さ優先探索とは
深さ優先探索 - Wikipediaグラフを探索するためのアルゴリズムのひとつです。ある特定のノード(木構造の場合は根)からスタートして、そこから探索できるところまで探索し、行き止まり(木構造の場合は葉)に到達したら、引き返しながら未探索のノードを探し、未探索のノードに対してまた探索できるところまで探索する、という操作を繰り返すアルゴリズムです。目標のノードがある場合、そのノードが見つかった時点で探索を終了しますが、全探索を行う場合は目標のノードを設定せずに、全てのノードを探索します。再帰を使えば簡単に実装できるので、アルゴリズムの入門としてもよく使われます。
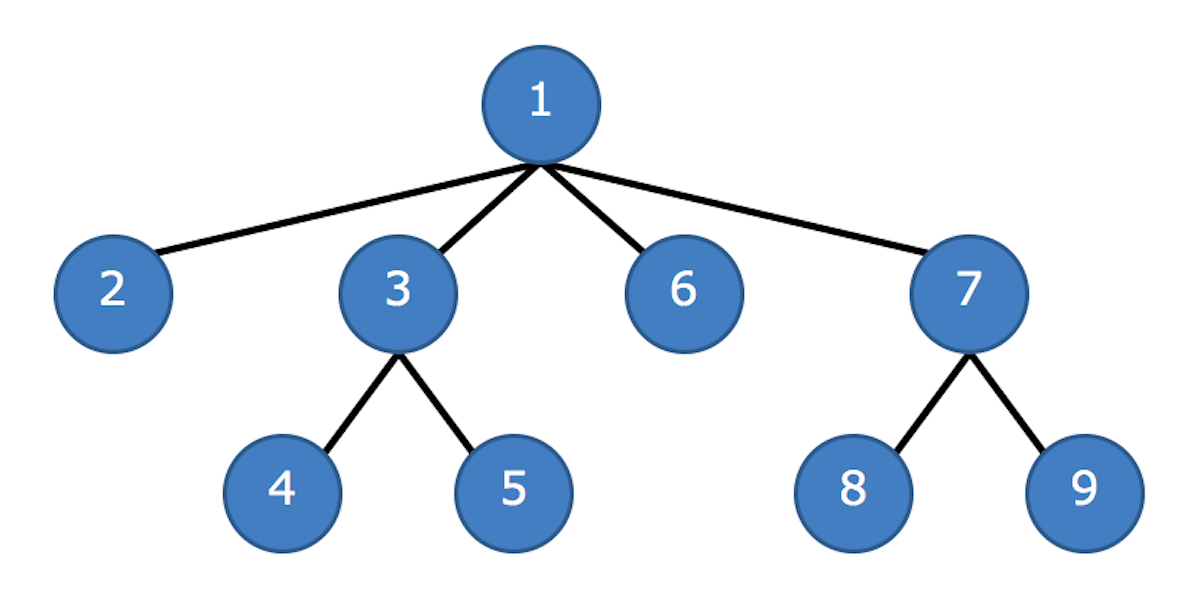
以下の図は、木構造を深さ優先探索で全探索したときの探索順を示したものです。
サンプルHTML
この記事で対象とするHTMLは、以下のようなHTML、sample_tree.htmlです。
<html>
<body>
<h1>深さ優先探索</h1>
<ul>
<li>箇条書きA</li>
<li>箇条書きB</li>
</ul>
<hr>
<div>本文</div>
</body>
</html>
bodyタグを根として深さ優先探索で全探索を行うと、探索順は次のようになることが期待されます。
bodyタグ h1タグ テキスト「深さ優先探索」 ulタグ liタグ テキスト「箇条書きA」 liタグ テキスト「箇条書きB」 hrタグ divタグ テキスト「本文」
Nokogiri標準の全探索メソッド「traverse」
Method: Nokogiri::XML::Node#traverseNokogiriには、あるノードを根として再帰的に全探索を行うtraverseというメソッドが用意されています。これを使って対象のHTMLを全探索してみましょう。
require 'nokogiri'
def print_node(node)
if node.text? then
unless node.to_s.strip.empty? then
puts node.to_s
end
else
puts node.name
end
end
html = open('sample_tree.html').read
doc = Nokogiri::HTML.parse(html)
body = doc.at_css('body')
body.traverse{|node|
print_node(node)
}
print_nodeは、Nokogiriのノードについて、そのノードがテキストノードであればそのテキストを、そうでなければタグ名を出力するメソッドです。Nokogiriでは、HTMLを見やすくするための改行もテキストノードとして扱ってしまうため、空白文字のみのテキストノードは無視するようになっています。
このコードを実行してみると、出力は以下のようになります。
$ ruby traverse.rb 深さ優先探索 h1 箇条書きA li 箇条書きB li ul hr 本文 div body
期待していた順番と異なります。あるノードの子孫ノード全ての探索が完了してから、あるノードの処理を行っているように見えます。
期待している順番で処理を行うために、深さ優先探索を行うdfsというメソッドを自前で実装しました。
require 'nokogiri'
def dfs(node_with_flag)
node_with_flag[1] = true
print_node(node_with_flag[0])
children = node_with_flag[0].children
children_with_flag = children.map{|child|
[child, false]
}
children_with_flag.each{|child_with_flag|
unless child_with_flag[1] then
dfs(child_with_flag)
end
}
end
html = open('sample_tree.html').read
doc = Nokogiri::HTML.parse(html)
body = doc.at_css('body')
body_with_flag = [body, false]
dfs(body_with_flag)
dfsメソッドの引数は、ノードと訪問済みフラグをセットにした配列です。print_nodeメソッドは、ここには書いていませんが、traverseのときと同じです。
このコードを実行すると、出力は以下のようになります。
$ ruby dfs.rb body h1 深さ優先探索 ul li 箇条書きA li 箇条書きB hr div 本文
期待していた順番で処理が行われました。
まとめ
HTMLを対象に、深さ優先探索で全探索を行う方法を紹介しました。目標のノードがある場合や、順番はどうあれ全探索したい場合は、Nokogiriに用意されているtraverseメソッドで十分ですが、期待通りの順番で全探索を行うために、自前で深さ優先探索を実装する必要がありました。
HTMLに限らず、木構造を持つデータ構造は多いので、応用範囲はかなり広いと思います。身近なところに木構造がないか、ちょっと探してみても面白いかもしれません。もし興味のある方は、深さ優先探索とは異なる探索アルゴリズム、幅優先探索についても調べてみてください。
CONTACT
お問い合わせ・ご依頼はこちらから