MAGAZINE
ルーターマガジン
JupyterLab with JupyterHub 自前サーバ環境構築の手引き

ルータのkanazawaです。
みなさまは、社内に溜まったデータの分析に何を使用されているでしょうか? 最近では、全てリソースをAWSやGCPといった、クラウドサービス上に置いておき、分析までクラウドで完結させている場合も多いのかなと思います。
弊社でも、AWS athena や Google Colaboratoryといったサービスを使用していましたが、リクエスト単位で課金されたり、セッションが切れると途中で実行が切れてしまったりと何かと不自由することが多くなってきたため、心機一転、社内データ分析用マシンを用意することにしました。
今回は、社内共用マシン所に、Jupyterの分析環境を構築する手順をご紹介しようと思います。
想定ユースケース
- 複数人で同じJupyterLabサーバを使用する
- データをラップトップに落とさずにサーバ上に置いたまま分析したい
- プロジェクトごとの依存モジュールを独立させたい
環境
このインストール手順は、以下の環境で試しています。
- OS Ubuntu 20.04.4 LTS
- CPU 11th Gen Intel(R) Core(TM) i7-11700 @ 2.50GHz (8コア/16スレッド)
- RAM 32GB
インストール方法
ここでは基本的に公式のThe Littlest JupyterHub (TLJH)に従って、 自前サーバにJupyterHubをインストールします。
1. JupyterHubを入れる
ここは公式のQuickStart に従い必要なものをイントールします。
重要なこととして、以下の手順はsudo権限を持つユーザに対して行うのが良いです。JupyterHubはログインユーザ毎のJupyter serverプロセスをforkするため、sudo権限があったほうが後々苦しまなくて済みます。
python3 -m pip install jupyterhub
npm install -g configurable-http-proxy
python3 -m pip install jupyterlab notebook # needed if running the notebook servers in the same environment- JupyterHub
- JupyterLab
- Http-Proxy
2. 設定ファイルのテンプレート作成
インストールが完了したら、ひとまず作業ディレクトリで、JupyterHubの設定ファイルを生成します。
jupyterhub --generate-configを実行することで、カレントディレクトリにjupyterhub_config.pyというファイルができるので、以降の手順ではこのファイルをテンプレートに設定を上書きしていきます。
3. ユーザ認証の設定
今回は、デフォルトで設定されているPAM認証を使用します。これは、Linuxのログインユーザ情報をそのまま認証情報にする仕組みです。 これを使うことで、Linuxユーザのユーザ名+パスワードでJupyterHubへのログインが可能になります。
2. 設定ファイルのテンプレート作成で作成したjupyterhub_config.pyに対して、
最初のAdminユーザがログインできるように以下を設定します。
c.Authenticator.admin_users = set(["Adminユーザ名"])
c.Authenticator.allowed_users = set(["Adminユーザ名"])Authenticatorのページに他の選択肢も有るため、 認証方法を変更したい場合は参考にして下さい。(Google認証も使用できるようです。)
4. Spawnerを設定
ユーザのJupyterHubへのログインが成功すると、spawnerという仕組みによってユーザごとのJupyterLab (or notebook) serverが立ち上がる仕組みになっています。 このユーザ毎のJupyter serverの起動・監視・停止を行う仕組みがSpawnerです。
jupyter Wiki Spawnerのページから利用可能なSpawnerの実装の一覧が確認できます。 ここでは、SystemdSpawnerを使用します。SystemdSpawnerを使うことで、ユーザごとのJupyterプロセスがsystemdを通じて起動するため、 Linuxサーバになれた方なら簡単にプロセスを管理することが可能です。(特にログ周りが嬉しい。)
SytemdSpawnerはpipではいるので、以下を実行します。
pip install jupyterhub-systemdspawnerまた、2. 設定ファイルのテンプレート作成で作成したjupyterhub_config.pyに対して、以下の設定をすることで
SystemdSpawnerを使用するようになります。
c.JupyterHub.spawner_class = 'systemdspawner.SystemdSpawner'5. ユーザごとのプロセスとしてJupyterLabを立ち上げる設定
JupyterHubはデフォルトでは、ユーザ毎のプロセスとしてJupyter notebookを起動するようになっているので、以下の設定で、JupyterLabが立ち上がるように変更します。 また、ついでにログインユーザのホームディレクトリがログイン時のデフォルトのディレクトリとなるように修正しておきます。
c.Spawner.default_url = '/lab' # JupyterLabを立ち上げる
c.Spawner.notebook_dir = '~/jupyter_projects' # ログイン時のデフォルトディレクトリをホームディレクトリにする6. JupyterHubにログインできることを確認
以上の設定ができれば、コンソール上で次のコマンドでJupterHubにログインできることを確かめてみます。
jupyterhub -f "PATH to jupyterhub_config.py"-fオプションで設定ファイルを渡すことができるので、2. 設定ファイルのテンプレート作成で作成したjupyterhub_config.pyのパスを書きます。
上手く起動すると、
[I 2022-04-13 19:16:07.467 JupyterHub app:3154] JupyterHub is now running at http://:8000というログが吐かれるはずなので表示されたポートにブラウザからアクセスしてみます。(何も設定していなければ、デフォルトはポート8000です。)
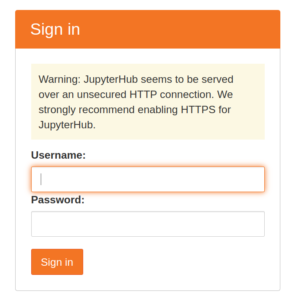
このような画面が出るはずなので、Linuxユーザのユーザ名・パスワードでログインできれば成功です。
7. JupyterHubをSystemdに登録
このままでは、JupyterHubを立ち上げたシェルを閉じるとJupyterHubが終了してしまうので、永続化のためにsytemdに登録して管理します。
サンプルとして、/etc/jupyterhubをjupyterhubの作業用ディレクトリとするsytemdのunitファイル(systemdの登録ファイル)は以下の通りです。
[Unit]
Description=Jupyterhub
[Service]
User=root
ExecStart=(PATH to jupyterhub) -f /etc/jupyterhub/jupyterhub_config.py
WorkingDirectory=/etc/jupyterhub
Restart=always # 死んだら常に再起動
[Install]
WantedBy=multi-user.targetこれを/etc/systemd/system/jupyterhub.serviceとして保存し以下を実行すると、jupyterhubがsytemdに登録され自動で起動・管理されます。
sudo systemctl daemon-reload # 新しく作成したunitファイルを読み込む
sudo systemctl start jupyterhub.service # jupyterhub のサービスを起動
sudo systemctl enable jupyterhub.service # boot 時にjupyterhub が自動で立ち上がるように設定ここまで設定すれば、JupyterHubでマルチユーザJupyterLabを動かす最低限の環境の完成です。
プロジェクトごとのJupyter Kernelの設定
更に、プロジェクトごとで使用するライブラリの管理を行った上で、JupyterLabを使用したいため、以下の設定をします。(特にライブラリのバージョンが混在することが問題とならない場合は、行なう必要はありません。)
この記事では、pyenvとPoetryのインスールは既に出来ているものとします。 インストール方法は別記事「Pythonパッケージ管理ツールPoetryのご紹介」も参考にしてみて下さい。
以下の設定は、「複数のPoetry管理のプロジェクトをJupyterで使う」のQiita記事をJupyterHub版に焼き直したものです。
1. プロジェクトツリー構成
今回は例として、以下のようなディレクトリツリーに対して、JupyterHubの設定を行います。
~/
└ jupyter_projects/
├ project1/
│ ├ .venv
│ ├ notebook/
│ ├ pyproject.toml
│ └ ⋮
├ project2/
│ └ ⋮
└ ⋮
まず、ユーザディレクトリ直下にjupyter_projectsという名のディレクトリを作成し、JupyterLab上の作業は全てこのディレクトリ配下で行うものとします。
またproject1とproject2がそれぞれ、独立の分析ブロジェクトに対応していて、それぞれの.venv以下に各プロジェクトで使用するipykernel (JupyterLabが使用するカーネル)や各ライブラリがインストールされます。
2. JupyterLab のプロジェクトのルートパスを設定
各ユーザがJupyterLabプロセスを立ち上げたときに、最初に起動するルートパスが~/jupyter_projectsとなるように設定します。
c.Spawner.notebook_dir = '~/jupyter_projects'3. プロジェクト毎のJupyter Kernelを自動読み込みする設定
各ユーザがJupyterLabプロセスを立ち上げたときに、そのユーザの管理している全てのブロジェクトそれぞれのカーネルを自動で読み込むように設定します。
これには、c.Spawner.pre_spawn_hookという、JupyterHubがユーザ毎のJupyterプロセスをspawnする前に共通で呼び出す処理を設定することで実現します。
import os
import subprocess
def update_kernel(spawner):
username = spawner.user.name
projects_dir = f"/home/{username}/jupyter_projects"
kernels_dir = f"/home/{username}/.local/share/jupyter/kernels"
if not (os.path.exists(projects_dir) and os.path.exists(kernels_dir)):
return
projects = [ x for x in os.listdir(projects_dir) if os.path.isdir(f"{projects_dir}/{x}") and (x[0] != '.') ]
kernels = [ x for x in os.listdir(kernels_dir) if os.path.isdir(f"{kernels_dir}/{x}") and (x[0] != '.')]
# delete all installed kernels
for kernel in kernels:
subprocess.call(["rm", "-rf", f"{kernels_dir}/{kernel}"])
# install all kernels
for project in projects:
subprocess.call(["sudo", "-u", username, f"{projects_dir}/{project}/.venv/bin/python", "-m", "ipykernel", "install", "--user", "--name", project])
c.Spawner.pre_spawn_hook = update_kernel
このように設定することで、各ユーザがJupyterLabを立ち上げるたびに自動でプロジェクトディレクトリを走査して、プロジェクトごとのカーネルを読み込んでくれるようになります。 例えば、下の図のように、project1 と project2 用のNotebookカーネルが用意されていることが分かります。
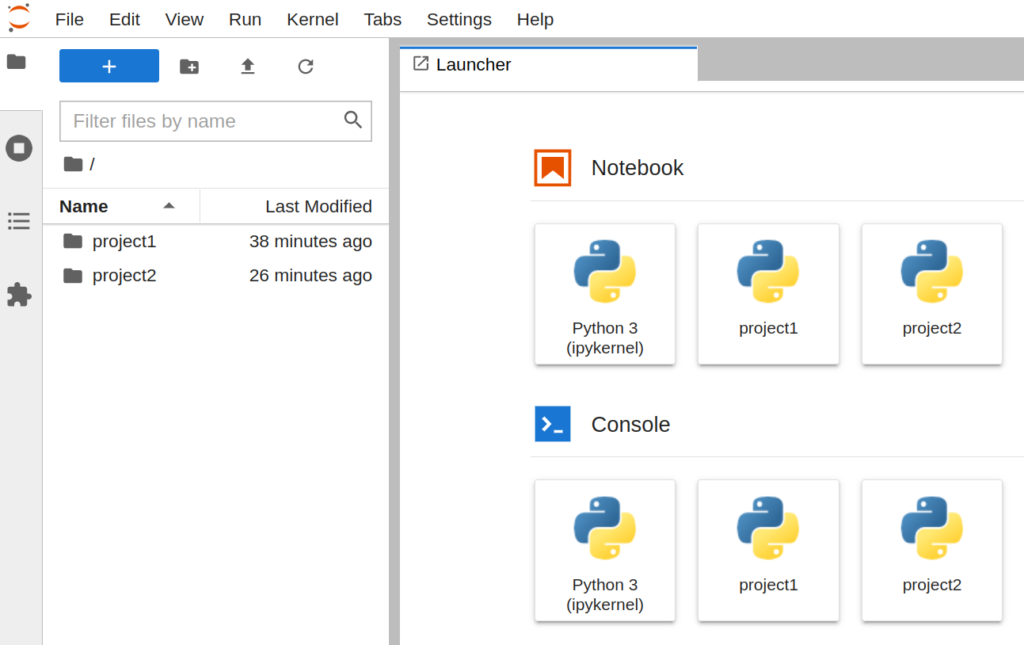
4. 新しいjupyterプロジェクトを作る手順
JupyterLabのユーザが、自分のworkingディレクトリに新しいプロジェクトを作成したい場合は、次のコマンドから新しいプロジェクトを参加します。
まず、poetryが仮想環境をプロジェクトディレクトリに作成する用になっているかを次で確認します。もしvirtualenvs.in-projectがfalseならばtrueにします。
poetry config --list
poetry config virtualenvs.in-project true # プロジェクトディレクトリに.venvを作成このとき、次のコマンドでnew_projectという名前のプロジェクトをpoetry経由で作成することができます。最後のコマンドはjupyterカーネルを動かすために
最低限必要なライブラリなので必ず入れる必要が有ります。
cd ~/jupyter_projects
poetry new --src new_project
cd new_project
poetry add -D ipykernel # jupyter kernelをインストール
さいごに
次回は、データ分析編を公開しますので、乞うご期待ください...!
参考URL
CONTACT
お問い合わせ・ご依頼はこちらから