MAGAZINE
ルーターマガジン
ActiveRecordを用いてinsertを行う方法を徹底比較【トランザクション・bulk_insert】

はじめに
こんにちは,学生アルバイトのYamamotoです.
今回は,RubyのActiveRecordに関するお話です.ActiveRecordは,一言で表すとRubyとSQLの架け橋のようなもので,これを用いることでMySQLデータベースの編集・参照などをRubyプログラム上から行うことができます.
もちろん,データベースへの書き込みもお手の物です.それも,書き込みの方法は複数あります.
「複数ある方法の中で,どれを使ったらより速く書き込むことができるのか?」
今回はこの疑問を解決すべく,複数の書き込み手法を比較し,どれが一番速いのかを検証していきたいと思います.
使用データと開発環境
国税庁が公開している法人番号リストの東京都データの中から,上位1万件を使用します.ダウンロードファイルの拡張子は.csvです.
開発環境や使用マシンはこちらになります.
- SQLサーバ: 10.5.9-MariaDB
- Ruby: 2.6.5
- OS: macOS Big Sur Ver.11.6
- チップ: Apple M1
- メモリ: 8GB
また,テーブル定義は以下の通りです.
CREATE TABLE `register_companies` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`corporate_number` bigint DEFAULT NULL,
`process` varchar(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`correct` tinyint(1) DEFAULT NULL,
`update_date` date DEFAULT NULL,
`change_date` date DEFAULT NULL,
`name` varchar(150) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`name_image_id` varchar(8) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`kind` varchar(3) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`prefecture_name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`city_name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`street_number` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`address_image_id` varchar(8) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`prefecture_code` varchar(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`city_code` varchar(3) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`post_code` varchar(7) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`address_outside` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`address_outside_image_id` varchar(8) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`close_date` date DEFAULT NULL,
`close_cause` varchar(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`successor_corporate_number` bigint DEFAULT NULL,
`change_cause` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`assignment_date` date DEFAULT NULL,
`latest` tinyint(1) DEFAULT NULL,
`en_name` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`en_prefecture_name` varchar(9) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`en_city_name` varchar(600) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`en_address_outside` varchar(600) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`furigana` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`hihyoji` tinyint(1) DEFAULT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;今回行った書き込み手法
今回は,以下の3つの手法を行いました.
- 1件1件の挿入ごとにトランザクションの開始と終了を挟む方法(autocommit)
- 全件の挿入が終わった後にトランザクションを終了する方法
- ActiveRecordのbulk_insertを用いる方法
これらの手法を,インデックスを張っている場合と張っていない場合でそれぞれ行い,RubyのTimeオブジェクトを用いて所要時間を計算します.
ここで,トランザクションとは「複数の処理のひとまとまり」を意味し,SQLでは"BEGIN"から"COMMIT"までの一連の処理を指します.トランザクション内部の処理に一つも問題がない場合のみ,そのトランザクションは実行されます.
各手法の概説
autocommit(1件1件の挿入ごとにトランザクションの開始と終了を挟む方法)
一般に,Activerecordを用いてデータベースに書き込む際には,テーブルのクラス名.create(レコード)が用いられます.プログラムで書くとこのようになります.
records = [{レコード1}, {レコード2}, {レコード3}, ...]
records.each do |record|
テーブルのクラス名.create(record)
endこのとき,ActiveRecordのログでは以下のように1件ごとに"BEGIN"と"COMMIT"が挟まれたような形になります.
BEGIN
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード1の値)
COMMIT
BEGIN
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード2の値)
COMMIT
BEGIN
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード3の値)
COMMIT
...全件commit(全件の挿入が終わった後にトランザクションを終了する方法)
以下のようにActiveRecord::Base.transactionで囲むことで,一括でコミットすることができます.
records = [{レコード1}, {レコード2}, {レコード3}, ...]
ActiveRecord::Base.transaction do
テーブルのクラス名.create(records)
endBEGIN
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード1の値)
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード2の値)
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード3の値)
...
COMMITbulk_insert(ActiveRecordのbulk_insertを用いる方法)
これまでに紹介した2つの手法はどちらも,INSERT INTO ○◯ VALUES (レコード1の値), INSERT INTO ○◯ VALUES (レコード2の値)のように,それぞれのレコードが別のINSERT文によって挿入されていました.bulk_insertは,それとは対照的に,全てのレコードを同じINSERT文で一括挿入してしまおう、というものです.プログラムのサンプルは以下のようになります.
records = [{レコード1}, {レコード2}, {レコード3}, ...]
ActiveRecord::Base.transaction do
テーブルのクラス名.insert_all(records)
endこのとき,ログでは以下のように,全件のレコードが同じINSERT文にまとめられています.
BEGIN
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード1の値), (レコード2の値), (レコード3の値), ...
COMMIT今回使用したbulk_insertのinsert_allメソッドは,主キーが重複しているものに関してはエラーを返さずにスキップするようになっています.逆に,スキップせずにエラーを返すようにするには,insert_all!メソッドを使用します.
(補足)デッドロックについて
先ほどご紹介した,全件commitやbulk_insertには,デッドロックが起こる危険性があります.デッドロックは,複数の処理を並列実行した際に,互いが競合することで処理が動かなくなる現象です.
いま,bulk_insertを行う2つのsqlを(ほぼ)同時に動かす場合を考えます.
sqlファイル1
BEGIN;
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード1の値), (レコード2の値), (レコード3の値), ...(レコード10000の値);
COMMIT;
BEGIN;
INSERT INTO `テーブル名` (テーブルのカラム名) VALUES (レコード10000の値), (レコード9999の値), (レコード9998の値), ..., (レコード1の値);
COMMIT;
この2つのsqlを,コマンド上でほぼ同時に実行すると,以下のようなエラーが起きます.
MariaDB [(DB名)]> source (sqlファイル2)
Query OK, 0 rows affected (0.000 sec)
ERROR 1213 (40001) at line 2 in file: '(sqlファイル2)': Deadlock found when trying to get lock; try restarting transaction
Query OK, 0 rows affected (0.003 sec)
このように,一つのtransactionを長くすることによってデッドロックのリスクは高まります.複数人が同時に一つのデータベースを操作する場合などにおいて,大きな問題となります.
サンプルプログラム
以上の処理を全てまとめたものがこちらになります.CSVファイルからレコードとなる配列を作成し,それぞれの手法を使用します.RubyのTimeオブジェクトで処理実行前と後の時刻を取得し,両者の差分を所要時間としています.
require 'csv'
require 'active_record'
ActiveRecord::Base.establish_connection(
adapter: 'mysql2',
database: 'register_company',
host: 'localhost',
username: 'root',
charset: 'utf8mb4',
encoding: 'utf8mb4',
collation: 'utf8mb4_general_ci',
password: ''
)
Time.zone_default = Time.find_zone! 'Tokyo'
ActiveRecord::Base.default_timezone = :local
class RegisterCompany < ActiveRecord::Base
self.table_name = 'register_companies'
end
# csvをレコードの形に変形
def csv_to_records(filename)
insert_records = []
CSV.foreach(filename) do |row|
insert_record = {
corporate_number: row[1],
process: row[2],
correct: row[3],
update_date: row[4],
change_date: row[5],
name: row[6],
name_image_id: row[7],
kind: row[8],
prefecture_name: row[9],
city_name: row[10],
street_number: row[11],
address_image_id: row[12],
prefecture_code: row[13],
city_code: row[14],
post_code: row[15],
address_outside: row[16],
address_outside_image_id: row[17],
close_date: row[18],
close_cause: row[19],
successor_corporate_number: row[20],
change_cause: row[21],
assignment_date: row[22],
latest: row[23],
en_name: row[24],
en_prefecture_name: row[25],
en_city_name: row[26],
en_address_outside: row[27],
furigana: row[28],
hihyoji: row[29]
}
insert_records << insert_record
end
insert_records
end
# 更新のたびにcommitを行う
def auto_commit(records)
start_time = Time.now
records.each do |record|
RegisterCompany.create(record)
end
"autocommit: #{Time.now - start_time}s"
end
# 一括でinsertしてからcommit
def transaction(records)
start_time = Time.now
ActiveRecord::Base.transaction do
RegisterCompany.create(records)
end
"transaction: #{Time.now - start_time}s"
end
# bulk_insert
def bulk_insert(records)
start_time = Time.now
ActiveRecord::Base.transaction do
RegisterCompany.insert_all(records)
end
"bulk_insert: #{Time.now - start_time}s"
end
def main(records)
auto_commit_time = auto_commit(records)
transaction_time = transaction(records)
bulk_insert_time = bulk_insert(records)
"#{auto_commit_time}\n#{transaction_time}\n#{bulk_insert_time}"
end
if __FILE__ == $0
insert_records = csv_to_records('13_tokyo_10000_20211130.csv')
puts main(insert_records)
end実行結果
インデックスなし
結果は以下の通りです.
| autocommit | 全件commit | bulk_insert |
| 24.68 [s] | 15.03 [s] | 2.93 [s] |
処理時間の内訳(全件commit)
| BEGIN | INSERT | COMMIT |
| 0.11 [s] | 14.87 [s] | 0.05 [s] |
処理時間の内訳(bulk_insert)
| BEGIN | INSERT | COMMIT |
| 2.42 [s] | 0.46 [s] | 0.05 [s] |
インデックスあり
次に,あらかじめテーブルにインデックスが貼られていた場合を考えます.インデックスがたくさん貼られていると,参照などは高速になりますが,挿入や更新などの処理は一般に遅くなってしまいます.
今回は,以下のSQL文を用いて,テーブルにインデックスを作成しました.
CREATE INDEX comp_index ON register_companies (
corporate_number,
`process`,
correct,
update_date,
change_date,
`name`,
name_image_id,
kind,
prefecture_name,
city_name,
street_number,
address_image_id,
prefecture_code,
city_code,
post_code,
address_outside_image_id,
close_date,
close_cause,
successor_corporate_number,
assignment_date,
latest,
en_prefecture_name,
hihyoji,
created_at,
updated_at);
こちらのSQLを実行すると,以下の画像のようにインデックスが作られます.
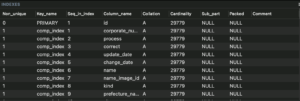
あとはインデックスなしの時と同様,Rubyプログラムを実行します.結果は以下の通りです.
| autocommit | 全件commit | bulk_insert |
| 28.91 [s] | 15.12 [s] | 2.99 [s] |
処理時間の内訳(全件commit)
| BEGIN | INSERT | COMMIT |
| 0.10 [s] | 14.97 [s] | 0.05 [s] |
処理時間の内訳(bulk_insert)
| BEGIN | INSERT | COMMIT |
| 2.43 [s] | 0.51 [s] | 0.05 [s] |
インデックスあり・なしの内訳を比較すると,BEGIN,COMMITはほぼ変わらず,INSERTのみが変わっているのがわかります.
各手法の特徴(強み・弱み)
autocommit
強み
autocommitを使う利点としては,途中でinsertできないレコードがあった場合も,その直前のレコードまではinsertされることが挙げられます.トランザクションが1件ごとに分割されているため,10000件目のレコードがエラーだったとしても,9999件目のレコードまではinsertされます.
弱み
他の手法と比較して処理が遅いことが挙げられます.また,上の2つの表を見比べていただくとわかるように,インデックスの有無によって処理にかかる時間が大きく変わってしまいます.
全件commit
強み
autocommitと比較して,処理にかかる時間が短くなります.今回の実験でも,autocommitと比較して所要時間は約半分でした.
また,トランザクションを使用することによって,データの整合性を損なわない状態でinsertができるといった強みもあります.例えば処理の途中にエラーがあった場合,autocommitだと途中までのレコードが挿入されているため,もう一度プログラムを動かした場合に同じレコードを再度挿入してしまう可能性もあります.この手法では,エラーがある場合は何も実行されないため,INSERT文に不備がない場合のみ挿入の処理が行われるというのは強みにもなります.
弱み
途中でinsertできないレコードがあった場合,1件もinsertされないことが挙げられます.全てのレコードを1つのトランザクションで括っている影響で,どこかでエラーが起きた場合はそのトランザクション全体が実行されないためです.9999件目までは正常で10000件目のレコードがエラーだった場合でも,この手法では1件もinsertされません.
また,先述のとおりデッドロックの危険性も生じます.
bulk_insert
強み
上の2手法と比較しても,処理時間はかなり短縮されます.今回の実験において,その処理速度はautocommitの8~10倍ほどでした.
弱み
デッドロック
全件commitの手法と同様,デッドロックの危険性が生じてきます.
クエリのサイズ
また,クエリのサイズが大きくなりすぎるという問題が生じます.今回は1万件のレコードで実験しましたが,10万件にしてbulk_insertを行うと以下のようなエラーが出てきます.
Mysql2::Error::ConnectionError: MySQL server has gone away (ActiveRecord::StatementInvalid)
このように,bulk_insertはINSERTが一文にまとまる分高速化しますが,逆にいうと一文にまとまることによってINSERT文自体が長くなり,エラーが起こりやすくなるのです.
created_atなどの自動補完
上2つの手法では,特に設定しなくともINSERT文に"created_at"や"updated_at"が自動補完されるのに対し,bulk_insertではこれらが補完されません.例えば今回の場合,bulk_insertによって生成されるINSERT文は以下のようになります.
INSERT INTO `register_companies` (`corporate_number`,`process`,`correct`,`update_date`,`change_date`,`name`,`name_image_id`,`kind`,`prefecture_name`,`city_name`,`street_number`,`address_image_id`,`prefecture_code`,`city_code`,`post_code`,`address_outside`,`address_outside_image_id`,`close_date`,`close_cause`,`successor_corporate_number`,`change_cause`,`assignment_date`,`latest`,`en_name`,`en_prefecture_name`,`en_city_name`,`en_address_outside`,`furigana`,`hihyoji`) VALUES (レコード1の値), (レコード2の値), ...
「bulk_insertを使いたい、なおかつcreated_atやupdated_atカラムに値を挿入したい」という方は,あらかじめ挿入するレコードに"created_at"カラムなどを追加するか,テーブル作成時に"created_at"カラムなどのdefault値を"CURRENT_TIMESTAMP"にすることで解決できます.今回は,後者の方法を採用しています.
最後に
今回は,RubyのActiveRecordを用いた書き込みに関して3通りの手法を試し,それぞれの特徴について述べました.時と場合に応じて各手法を使い分けられるとよいでしょう.
CONTACT
お問い合わせ・ご依頼はこちらから