MAGAZINE
ルーターマガジン
UTF-8からSJISに変換する時にはShift-JIS系エンコードの種類だけじゃなくてUNICODE正規化も気にしないとダメという話
利用シーン
UTF-8で記述されたテキストをShift-JISエンコードに変換する機会はあります。 UNICODEで表現できる文字の種類の方がShift-JISに比べて圧倒的に広いのですべての文字が変換できるわけではありませんが、「これは変換できてよかろう」というものまでこぼれ落ちるケースは多数あります。
以下こぼれ落ちる例とその対応を示します。
サンプルコード
まずはサンプルコード。 rubyで記述していますが、原理はどの言語でも同じです。
str = "あ~あ①髙島屋パバぱ"
sjis = str.encode(Encoding::Shift_JIS, :invalid => :replace, :undef => :replace)
File.write('Shift_JIS_from_nfd.txt', sjis)
# => あ?あ??島屋ハ?ハ?は?
sjis = str.encode(Encoding::SJIS, :invalid => :replace, :undef => :replace)
File.write('SJIS_from_nfd.txt', sjis)
# => あ~あ①髙島屋ハ?ハ?は?
sjis = str.unicode_normalize(:nfc).encode(Encoding::SJIS, :invalid => :replace, :undef => :replace)
File.write('SJIS_from_nfc.txt', sjis)
# => あ~あ①髙島屋パバぱ
解説
str = "あ~あ①髙島屋パバぱ"
この手の文字をよく使います。文字の変換では必須のテストデータですね。
sjis = str.encode(Encoding::Shift_JIS, :invalid => :replace, :undef => :replace)
File.write('Shift_JIS_from_nfd.txt', sjis)
# => あ?あ??島屋ハ?ハ?は?
はい。ここでグズグズに文字が化けてしまいました。Rubyのencodeメソッドはエンコーディングを変換してくれるのですが、対応する文字がない時には、?に変換してねってオプションを付けています。
まず「~」が化けていますね。昔から存在する「波ダッシュ問題」です。「~」を波ダッシュ文字に割り当てるのか、全角チルダに割り当てるのかという課題です。UNICODE上では両方存在しているしパット見はほぼ同じなのですが、いずれにしても別の文字として存在するので、Shift-JISに対応する文字がどちらなのかという対応表の違いで文字が化けます。
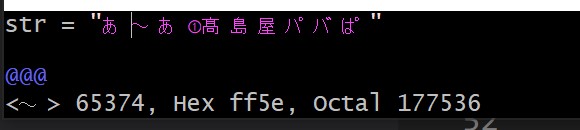
今回記述している~は全角チルダ(ff5e)のコードで記載されています。
対応としては Encoding::Shift_JIS というところを変えます。Shift_JISというのは確かに規格としては存在するのですが、日本のビジネス現場で言うShift_JISはWindows-31Jのことを指します。なのでEncoding::Windows-31J と書くと良いです。Javaに慣れた人なら、CP932 という言い方もあります。Rubyでは Encoding::Windows-31J のエイリアスとして SJISが存在します。つまり Shift_JISではなく SJIS と指定すると、うまく機能します。それが次の段落のソースになります。
sjis = str.encode(Encoding::SJIS, :invalid => :replace, :undef => :replace)
File.write('SJIS_from_nfd.txt', sjis)
# => あ~あ①髙島屋ハ?ハ?は?
はい。これで、波ダッシュと丸数字が化けなくなりました。それでも、濁点の文字から濁点がなくなって謎の文字化けをしています。なんでしょうこの文字は。
ということで、実際元のテキストをみてみます。
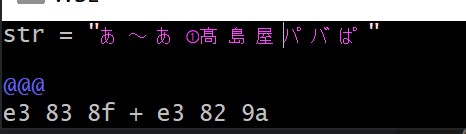
UTF-8のテキストなので、3バイトであるはずが、3バイト+3バイトの計6バイトの二文字が使われている合成文字になっています。これはこれでUNICODEとしては存在します。ただShift-JISには合成文字の概念はないので、合成文字の二文字目としての濁点は化けてしまいます。
そこで行うのがUNICDODE正規化です。
str.unicode_normalize(:nfc)
の部分で、二文字濁点から1文字濁点に変換しています。これでめでたく濁点も化けなくなります。
このブログを書くにあたっての文字コード周りのコツ
各文字コード見方
メジャーどころで文字単位で文字コードが見れるのはvimです。 カーソル位置で以下のコマンドでステータスバーにコードポイントがみれます。
- g a → UNICODの文字コードが見れる
- g 8 → UTF8での文字コードが見れる
これよく使います。手元PCで便利ツールがあってもサーバー側にある化けてるデータをダウンロードするのはセキュリティ上難しいケースもあるでしょうから、サーバー側でコードが見れる手法は持っておいた方がいいですね。
二文字濁点のテストデータの作り方
エディタの保存機能を使って、UTF-8で保存できても、さらに「濁点は二文字で保存」みたいなオプションはありません。Macのファイル名は二文字濁点になるようですが、そのためにMacを用意するのも遠回りです。
なので、今回はirbでunicode_normalizeメソッドを使って二文字濁点にしています。
irb(main):003:0> "ガ".unicode_normalize(:nfd)
=> "ガ"
みためはわからないですが、二文字の濁点に変換されています。 (vimに貼り付けて、g8をタイプすればわかる)
CONTACT
お問い合わせ・ご依頼はこちらから