
InnoDBのインデックス
インデックスとは、 データベース上でのSELECT、WHEREなどの操作による データの集計・検索の高速化に貢献する技術の1つです。 ここでは、MySQLで使用されるInnoDBのインデックスについて説明します。B+木(B+Tree)について
MySQLのInnoDBエンジンで使われるインデックスは、B+木というデータ構造で実装されています。 InnoDBのインデックスは、以下の種類があります。- クラスタインデックス
- セカンダリインデックス
- カバリングインデックス
- 複合インデックス
B+木の派生元
B+木は、B木というデータ構造をもとに改良したデータ構造となっています。 B+木の説明に入る前に、その派生元であるB木について説明します。B木と木構造
B木は、「B木」という名前から見て「木」という文字が使われていることから分かるように、 木構造というデータ構造がベースとなってできています。 実世界にある木(Tree)の構造に見たてています。 木を形成する各部構造は、節と枝はもちろん、根や葉もあります。
上記をそれぞれ英名表記して、ノード、ブランチ、ルート、リーフと呼んでいます。
木を形成する各部構造は、節と枝はもちろん、根や葉もあります。
上記をそれぞれ英名表記して、ノード、ブランチ、ルート、リーフと呼んでいます。
- ノード (= 節)
- ブランチ (= 枝)
- ルート (= 根)
- リーフ (= 葉)
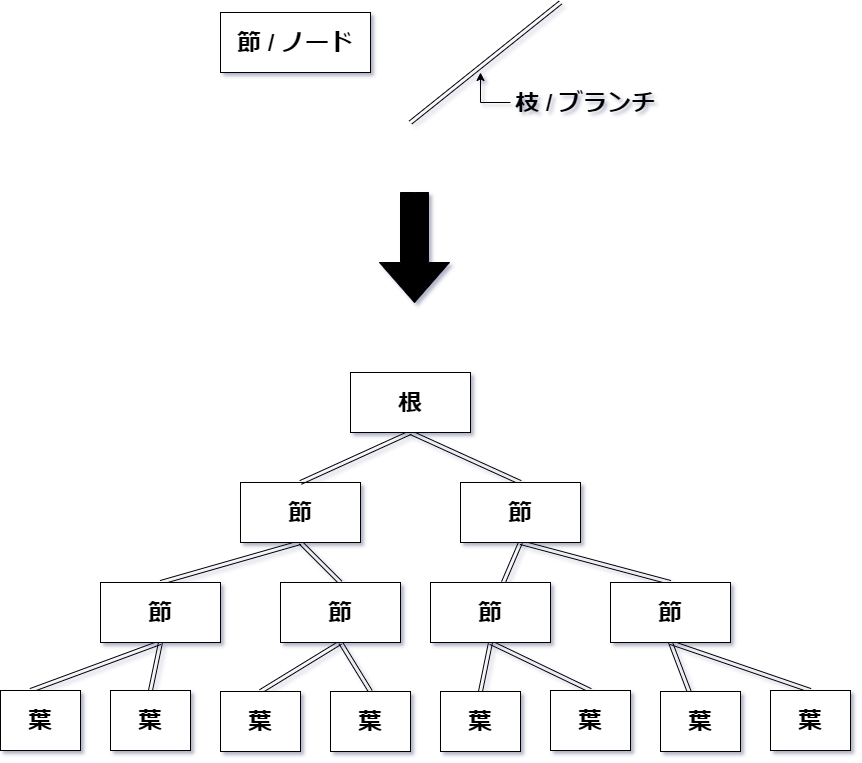 特に、最上位の根にあたるノードをルートノードといい、
最下位の葉にあたるノードをリーフノードや葉ノード
という呼び方をします。
特に、最上位の根にあたるノードをルートノードといい、
最下位の葉にあたるノードをリーフノードや葉ノード
という呼び方をします。
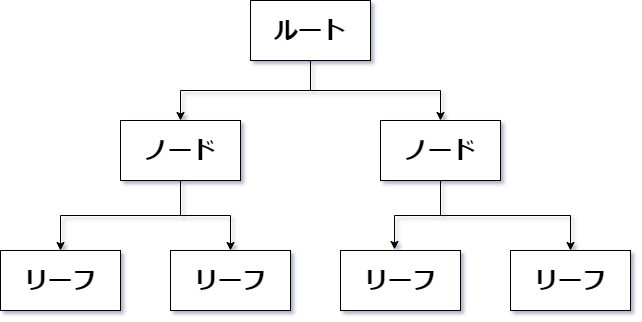
B木の説明
B木も上記の木構造の一種であるため、木構造と同じ言葉や概念があります。- 最上層ノードをルートノードと呼ぶ。
- 最下層のノードをリーフノードと呼ぶ。
- ノード同士がそれぞれ繋がり、それぞれにデータ値を持っている。
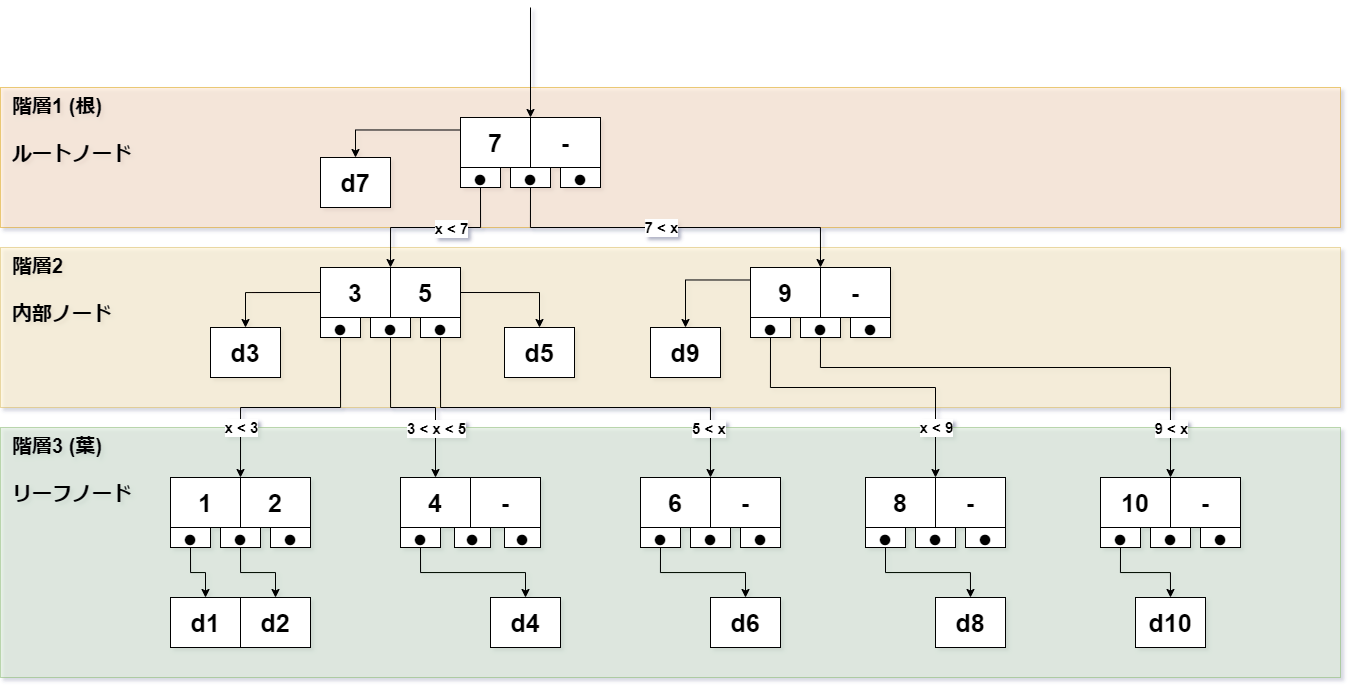 数値データは、ルートノード、内部ノード、リーフノードの各ノードに格納されます。
データを検索するときは、
数値データは、ルートノード、内部ノード、リーフノードの各ノードに格納されます。
データを検索するときは、
- ルートノードから探索を開始します。
- 各ノードでの大小比較により、指定された次のノードを辿ります。
- 目的のデータがあるノードに辿り着くと、そのノードで検索が終了します。
B+木の構造
ここからは、本題のB+木の説明です。 B+木は、B木の改良版の木構造であるため、B木の基本的な構造を受け継いでいます。 しかし、B木と比べて以下の違いと特徴があります。- データ値は、リーフノードのみに格納する。
- リーフノード以外のノードには、キーを格納する。
- リーフノードの隣接間がポインタで相互接続される。
- データベースのデータ値を格納しているのは、最下層にあるリーフノードのみ。(→ データ部) ※リーフノード以外のノードには、データ値を格納しない。
- キー(ポインタ)情報は、内部ノードというノードに格納する。(→ 探索部)
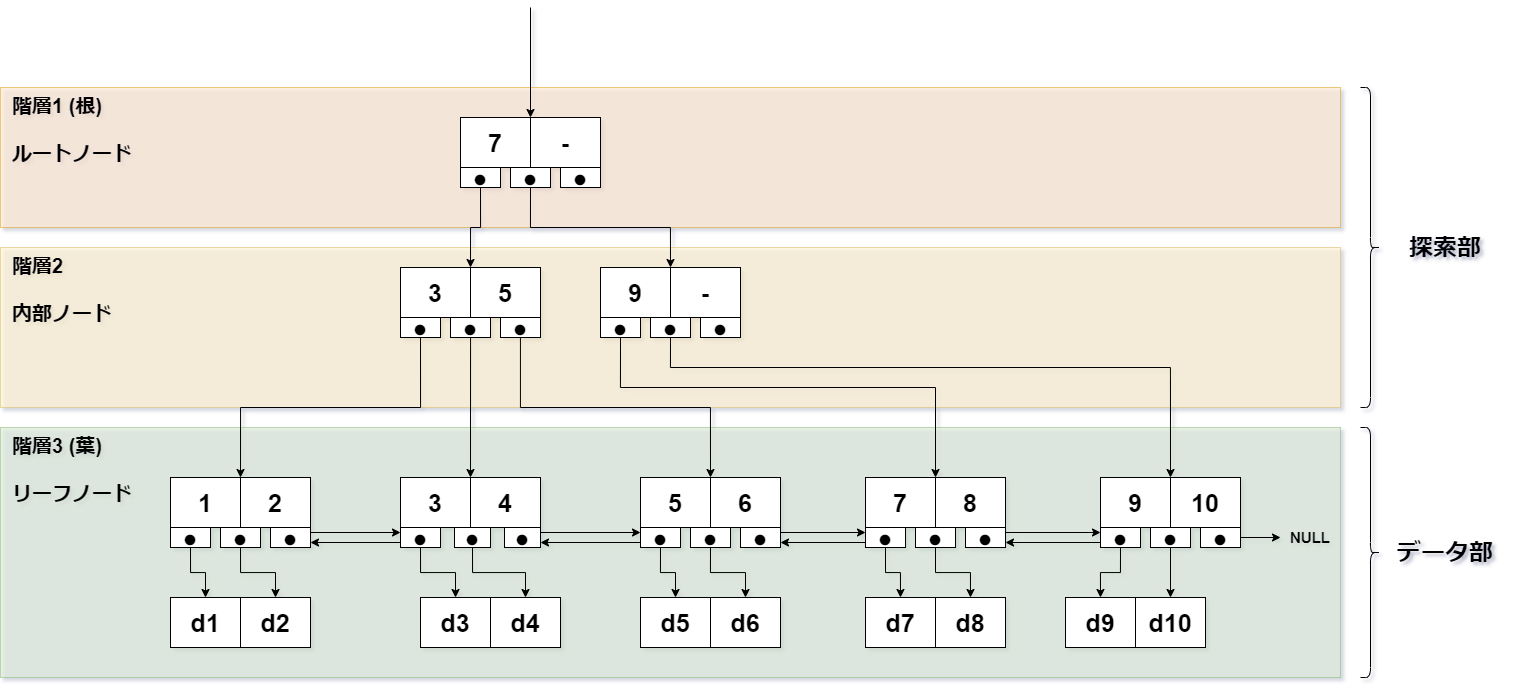 ※B木は内部ノードにもデータ値を格納するのに対し、B+木はリーフノードのみにデータ値を格納します。
※内部ノード間同士は、ポインタで接続されています。
※隣接するリーフノード同士は、双方向のポインタで接続されています。
SQL実行時、データベース(InnoDB)内部では、
※B木は内部ノードにもデータ値を格納するのに対し、B+木はリーフノードのみにデータ値を格納します。
※内部ノード間同士は、ポインタで接続されています。
※隣接するリーフノード同士は、双方向のポインタで接続されています。
SQL実行時、データベース(InnoDB)内部では、
- ルートノードからデータ探索を開始します。
- 探索部にある内部ノード(探索部)をキー情報でリーフノード(データ部)まで探索します。
- 最下層にあるリーフノードにたどり着きます。
- リーフノード上にあるデータ値を取り出します。
なぜB+木が採用されているのか
なぜB+木が採用されているのか、B+木のメリットは大きく分けて2つあります。- 等価検索の処理時間が短縮される。
- 特に範囲検索が高速になる。
検索時間の短縮
(A)B+木を用いない順読み検索と、(B)B+木を用いた検索 にかかる検索時間Oをそれぞれデータ量をnとして、次のように表現します。- (A) O(n)
- (B) O(log n)
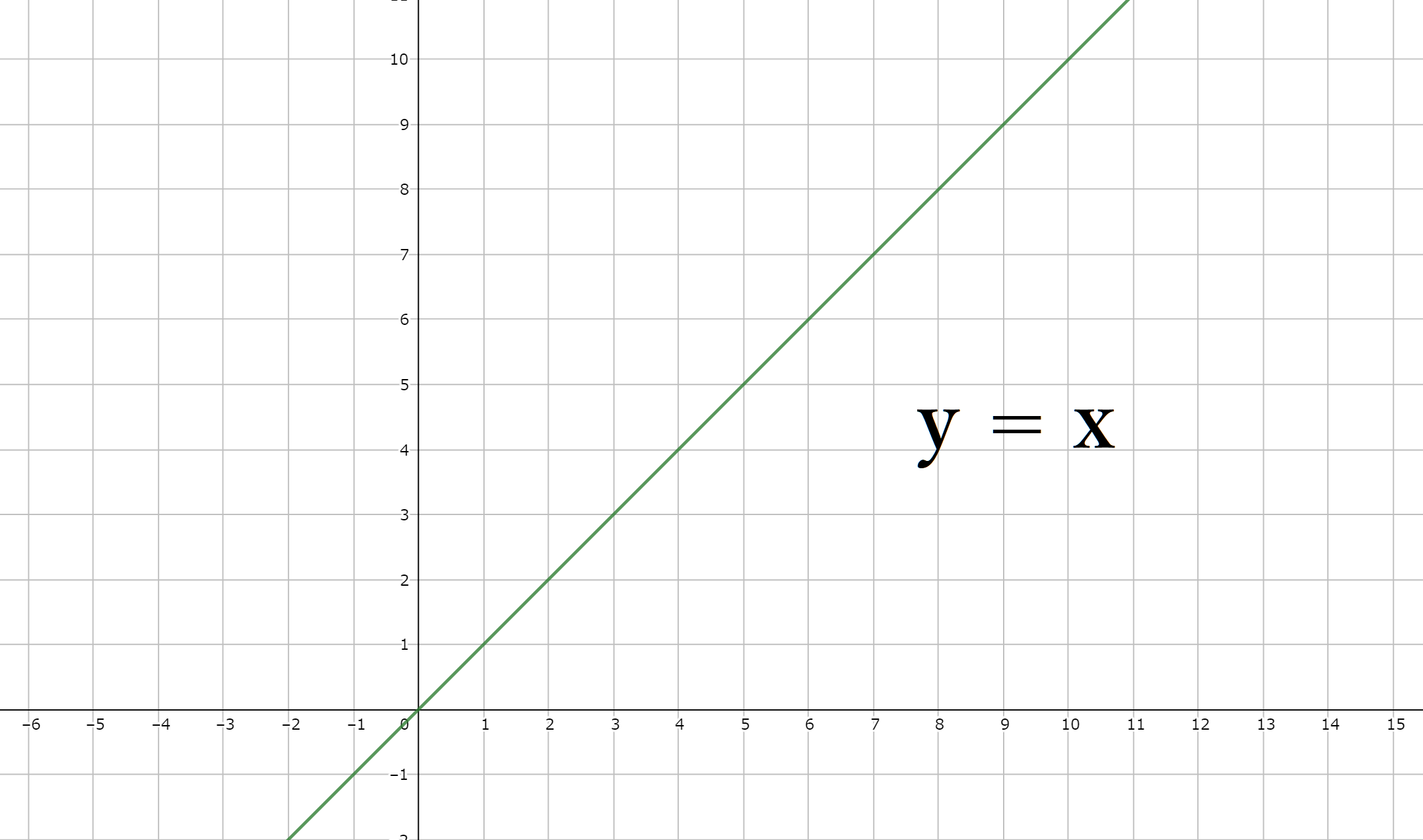 しかし、(B)ではデータ量nが増えても、検索時間Oが緩やかにしか上がらないことが分かります。
しかし、(B)ではデータ量nが増えても、検索時間Oが緩やかにしか上がらないことが分かります。
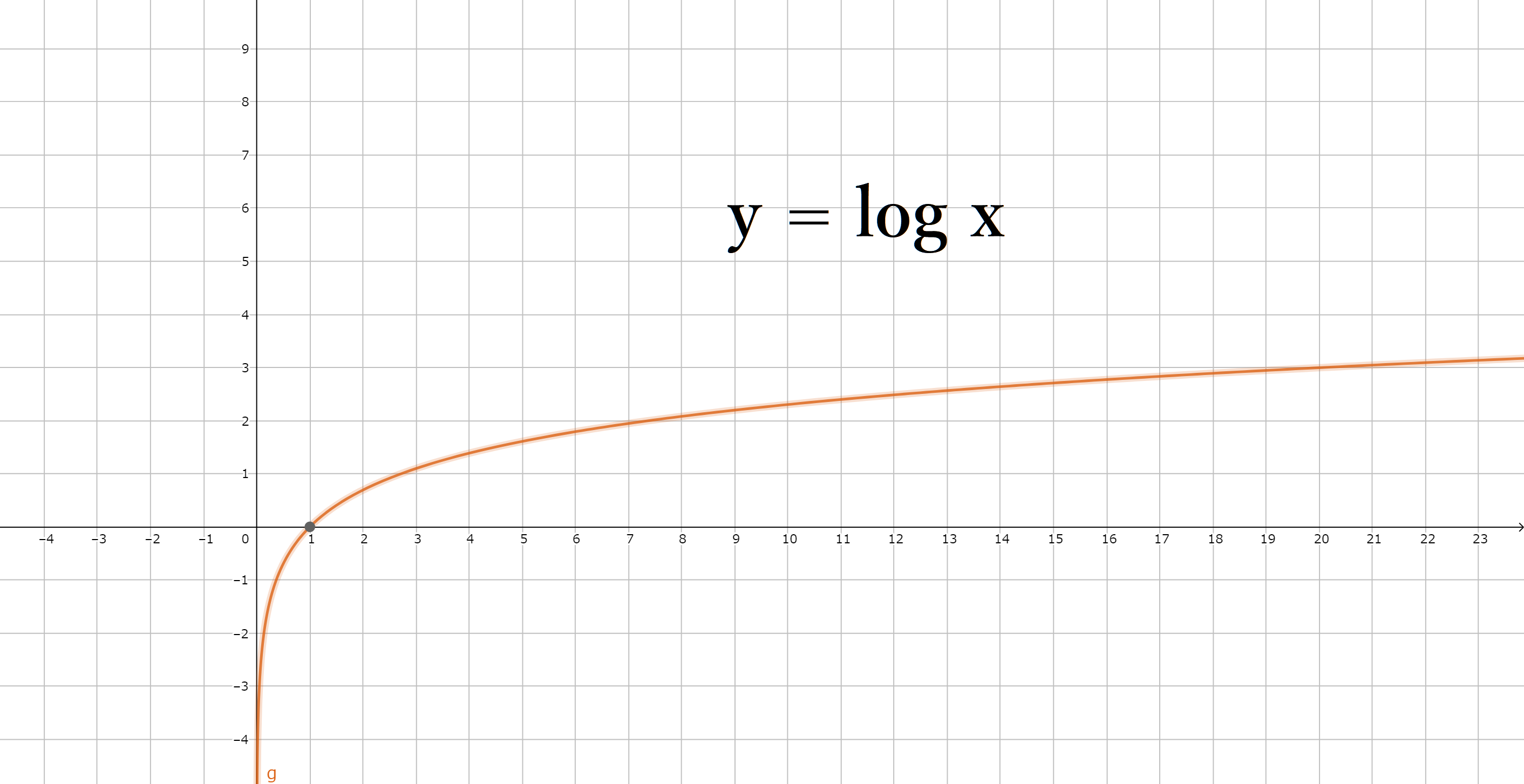 上記からデータ量が急激に増えたとしても、(B)B+木の方が安定して効率的に検索できることがわかります。
ここで安定・効率的となるのは、ルートノードからリーフノードまでの高さが、
上記からデータ量が急激に増えたとしても、(B)B+木の方が安定して効率的に検索できることがわかります。
ここで安定・効率的となるのは、ルートノードからリーフノードまでの高さが、
- すべてのリーフノードにおいて常に同じになる。
- 全体の木の高さ自体が低い。
範囲検索の高速化
B+木は、B木には持っていない以下の特徴がありました。- リーフノードのみに値を格納する。
- リーフノードの隣接間が接続されている。
WHERE C BETWEEN A AND B
や、
WHERE A <= C AND C <= B
のような範囲検索時に効果を発揮します。
B+木の挙動
B+木のインデックスの検索の流れとして、以下のSQLを例示します。等価検索
[SQL] SELECT col FROM table WHERE col = 6;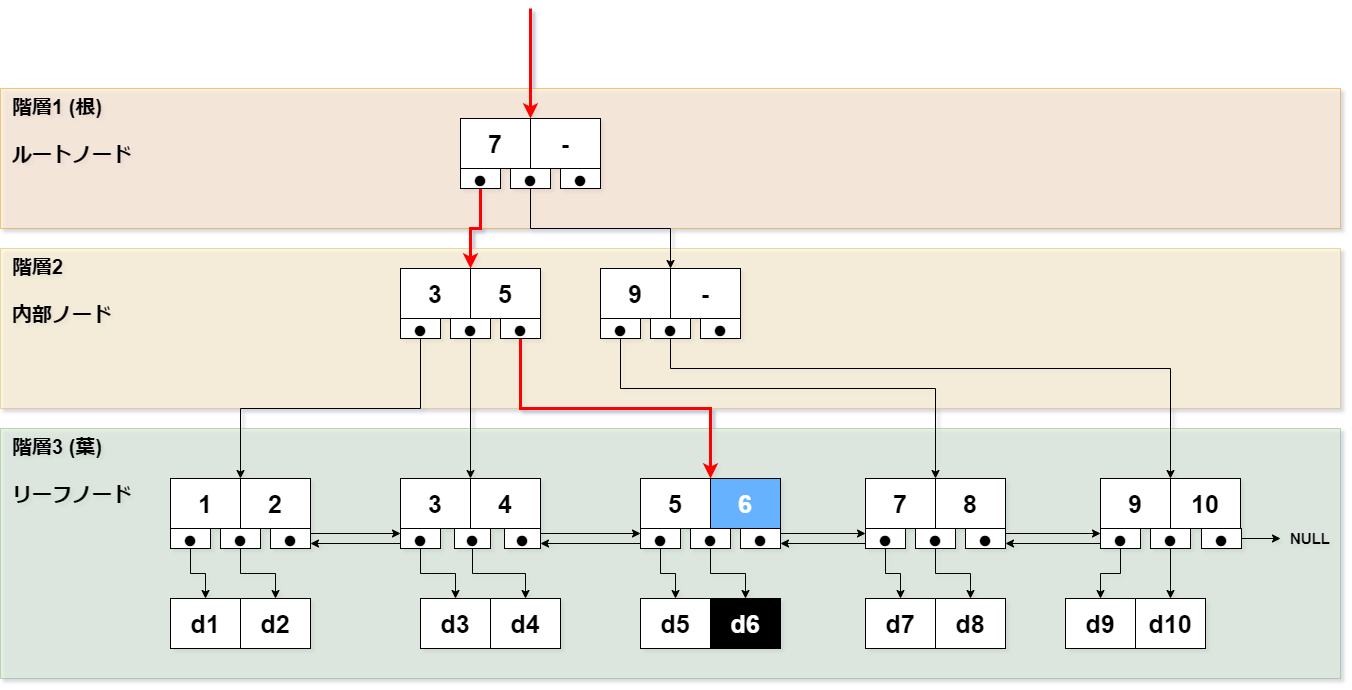 [手順]
[手順]
- col = 6を探します。
- 内部ノードをたどります。
- リーフノードに到達します。
- 値を取り出します。(col = 6)
範囲検索1
[SQL]
SELECT col FROM table
WHERE col BETWEEN 4 AND 7;
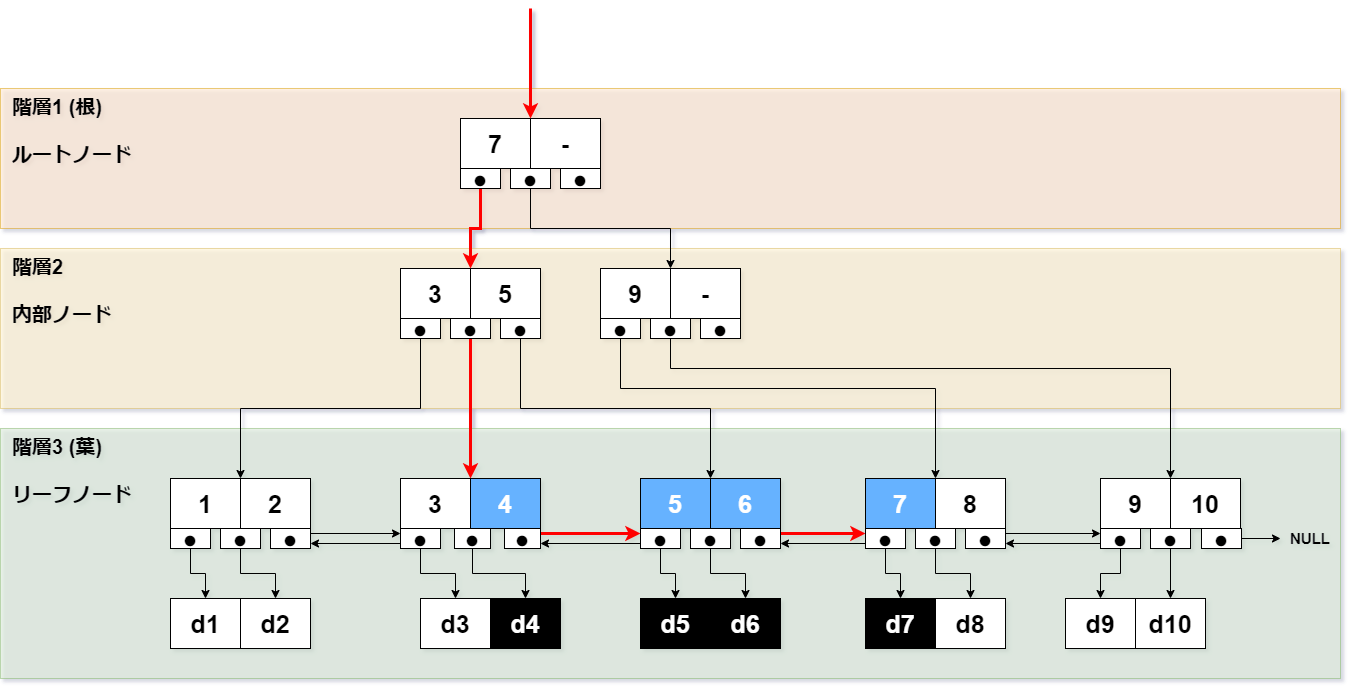 [手順]
[手順]
- col = 4を探します。
- 内部ノードをたどります。
- リーフノードに到達します。
- 値を取り出します。(col = 4)
- 次のリーフノードの値を取り出します。(col = 5)
- 次のリーフノードの値を取り出します。(col = 6)
- 次のリーフノードの値を取り出します。(col = 7)
範囲検索2
[SQL]
SELECT col FROM table
WHERE col < 9;
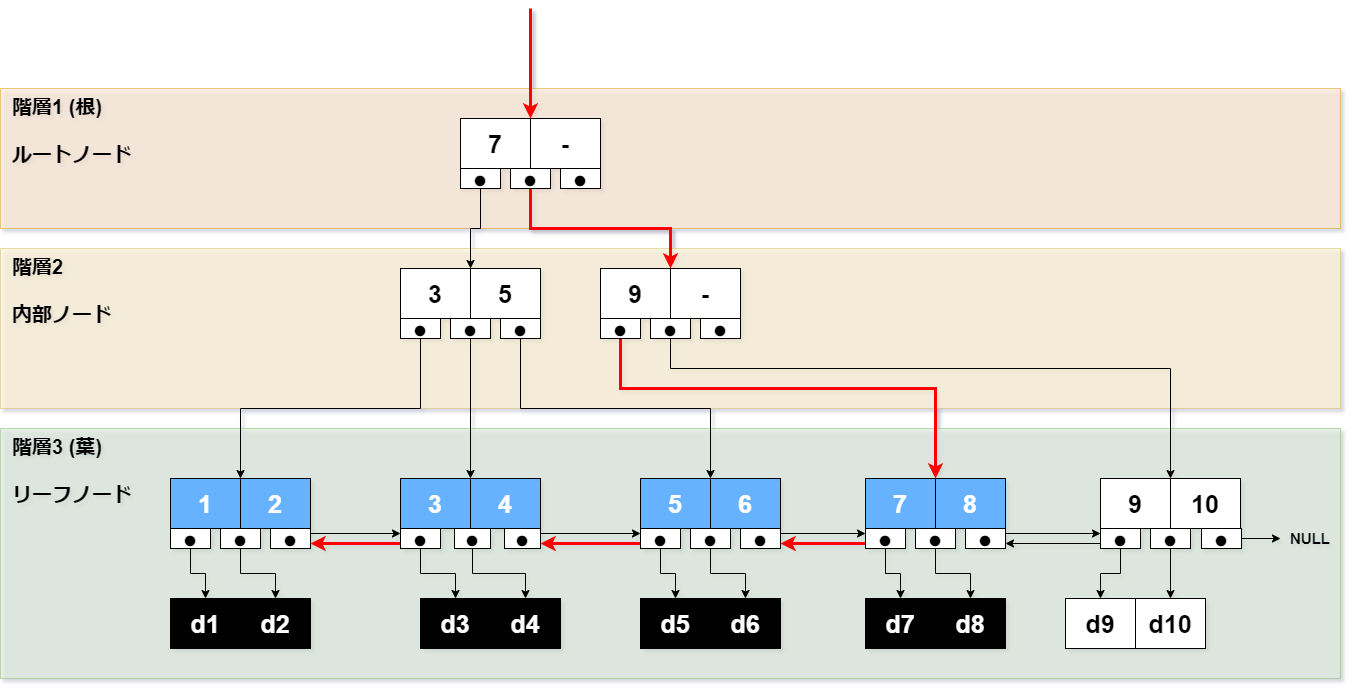 [手順]
[手順]
- col = 8を探します。
- 内部ノードをたどります。
- リーフノードに到達します。
- 値を取り出します。(col = 8)
- 前のリーフノードの値を取り出します。(col = 7)
- ~ 省略 ~
- 前のリーフノードの値を取り出します。(col = 2)
- 前のリーフノードの値を取り出します。(col = 1)
まとめ
- InnoDBのインデックスの実装には、B+木が利用されている。
- B+木はB木の改良型のツリー構造をしている。
- データベースのデータ値は、B+木の最下部にあるリーフノードのみに配置する。
- 検索時は、内部ノードのキーを検索しリーフノード上のデータを取得する。
- B+木を利用すると、B木の特性を生かした等価検索のパフォーマンスや、 B+木の特性であるリーフノード同士がポインタで結ばれるため、範囲検索での探索効率も高い。
インデックスの種類
前章では、B+木の基本構造について説明しました。 実際のテーブルのデータがインデックスとして格納されるとき、- クラスタインデックス
- セカンダリインデックス
- カバリングインデックス
- 複数インデックス
CREATE TABLE SAMPLE_TABLE(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(100),
qty INT,
date DATE
);
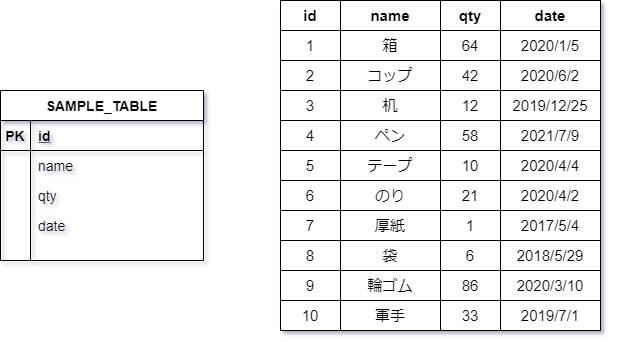
クラスタインデックス
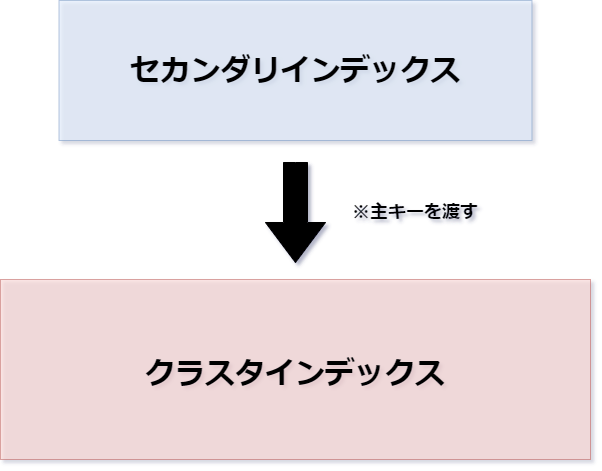
クラスタ化インデックスとも呼びます。 クラスタ(Cluster) = 集団、房 という意味です。 カラムの全データが集まっていると考えます。 CREATE、ALTER文などで、PRIMARY KEYやUNIQUEキーの定義を行ったとき、 そのカラムは自動的にクラスタインデックスとなります。 B+木の各内部ノードには、主キーやユニークキーが割り当てられ、 リーフノードには、主キーを含めたすべてのカラムのレコードのデータが入っています。 セカンダリインデックスでデータが見つからなかったとき、 セカンダリインデックスから渡される主キーで、クラスタインデックスにアクセスしてデータを取得します。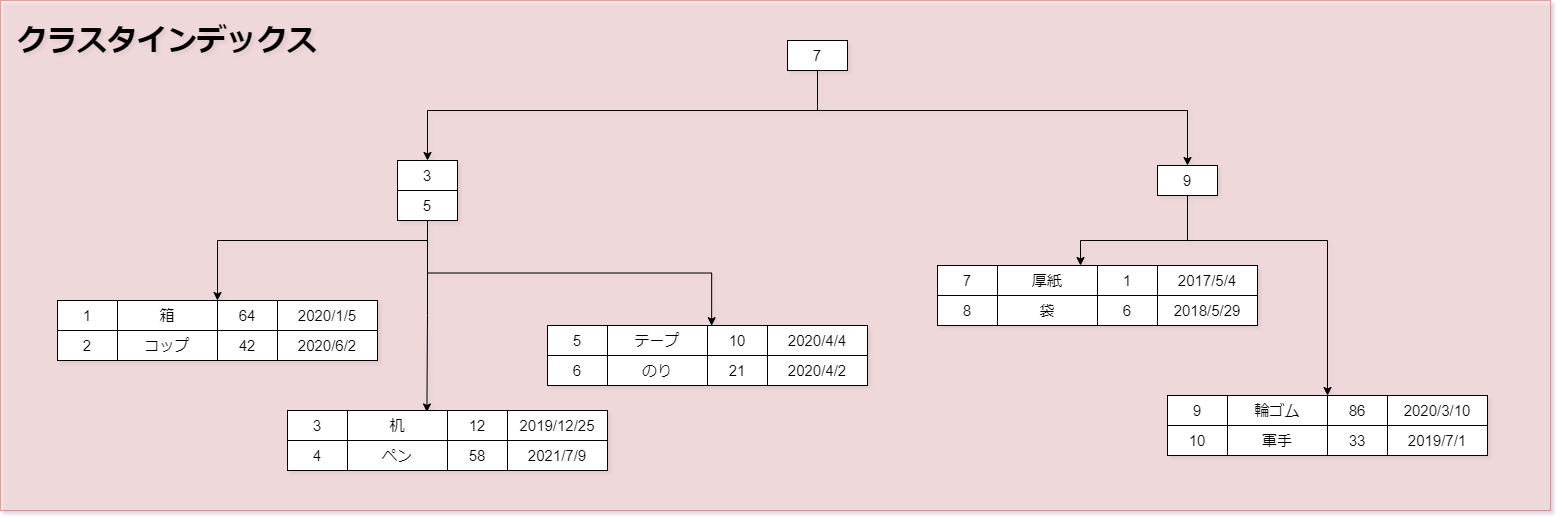
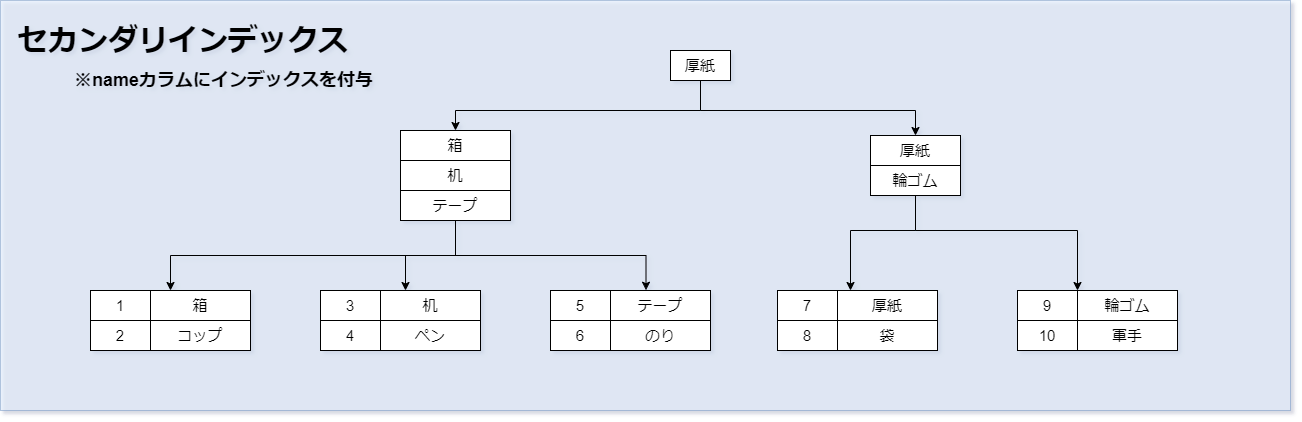
セカンダリインデックス
セカンダリ(Secondary) = 第2の という意味です。 クラスタインデックスとは異なり、特定のカラムデータにつけるインデックスです。 ここで特定のカラムとは、主キーやユニーク以外のカラムを指します。 B+木の各内部ノードには、特定のカラムのインデックスがキーとして割り当てられ、 リーフノードには、主キーが格納されます。 インデックスのデータ探索は、まずこのセカンダリインデックスから行われます。 セカンダリインデックス内に対象検査データが存在しない場合、 セカンダリインデックスの主キーをクラスタインデックスに渡し、クラスタインデックスでの探索を開始します。 CREATE、ALTER TABLE文でインデックスを追加することができます。 次のSQL例は、nameカラムにインデックスを付与しています。
CREATE TABLE SAMPLE_TABLE(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(100),
qty INT,
date DATE,
INDEX INDEX_NAME(name)
);
ALTER TABLE SAMPLE_TABLE ADD INDEX INDEX_NAME(name);
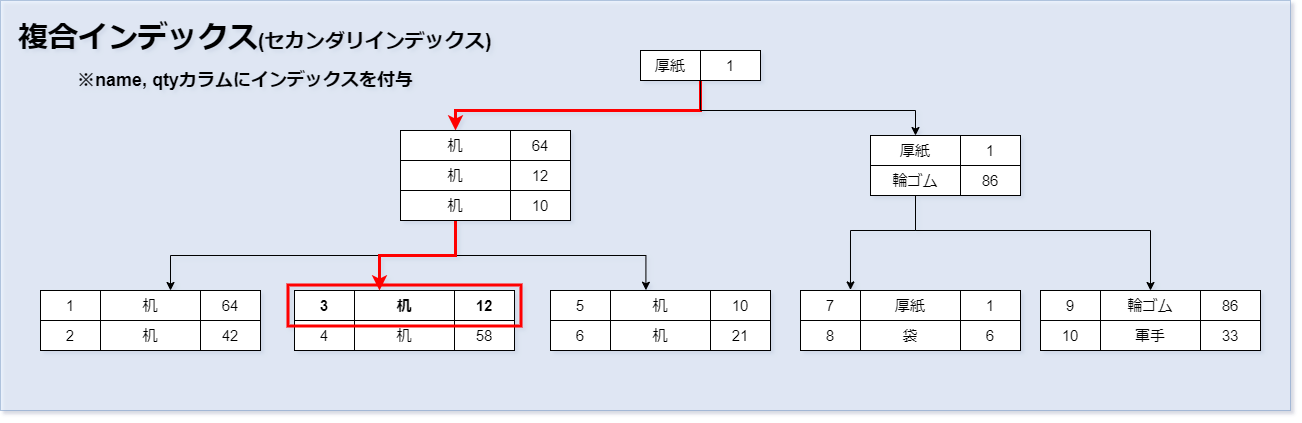
複合インデックス
マルチカラムインデックスとも呼びます。 インデックスは、同一のテーブルに1つのカラムだけではなく、複数のカラムにインデックスを持たせることができます。 複合インデックスとは、2つ以上のカラムを組み合わせて、1つのインデックスとすることを指します。 主に2つ以上のカラムに対する検索時に、その全カラムに複合インデックスが付与されていると、検索が高速になります。 複合インデックスでは、例示テーブルの一部を以下のように変更します。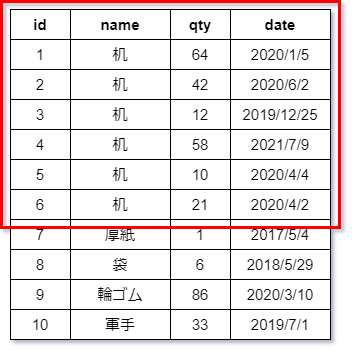 idが1~6に該当するnameカラムの値をすべて「机」に変更しました。
ここで、nameとqtyカラムに複合インデックスを付与します。
次のSQL例で、nameとqtyカラムを複合インデックスとすることができます。
idが1~6に該当するnameカラムの値をすべて「机」に変更しました。
ここで、nameとqtyカラムに複合インデックスを付与します。
次のSQL例で、nameとqtyカラムを複合インデックスとすることができます。
ALTER TABLE SAMPLE_TABLE ADD INDEX INDEX_NAME_QTY(name, qty);
 上記のように複合インデックスを付与させると、次のようなWHERE検索が高速化します。
WHERE name = '机' AND qty = 12;
しかし、次のようなWHERE検索は、dateカラムにインデックスが付与されていないため、大きな高速化は望めません。
上記のように複合インデックスを付与させると、次のようなWHERE検索が高速化します。
WHERE name = '机' AND qty = 12;
しかし、次のようなWHERE検索は、dateカラムにインデックスが付与されていないため、大きな高速化は望めません。
WHERE name = '机' AND date = '2019/12/25';
カバリングインデックス
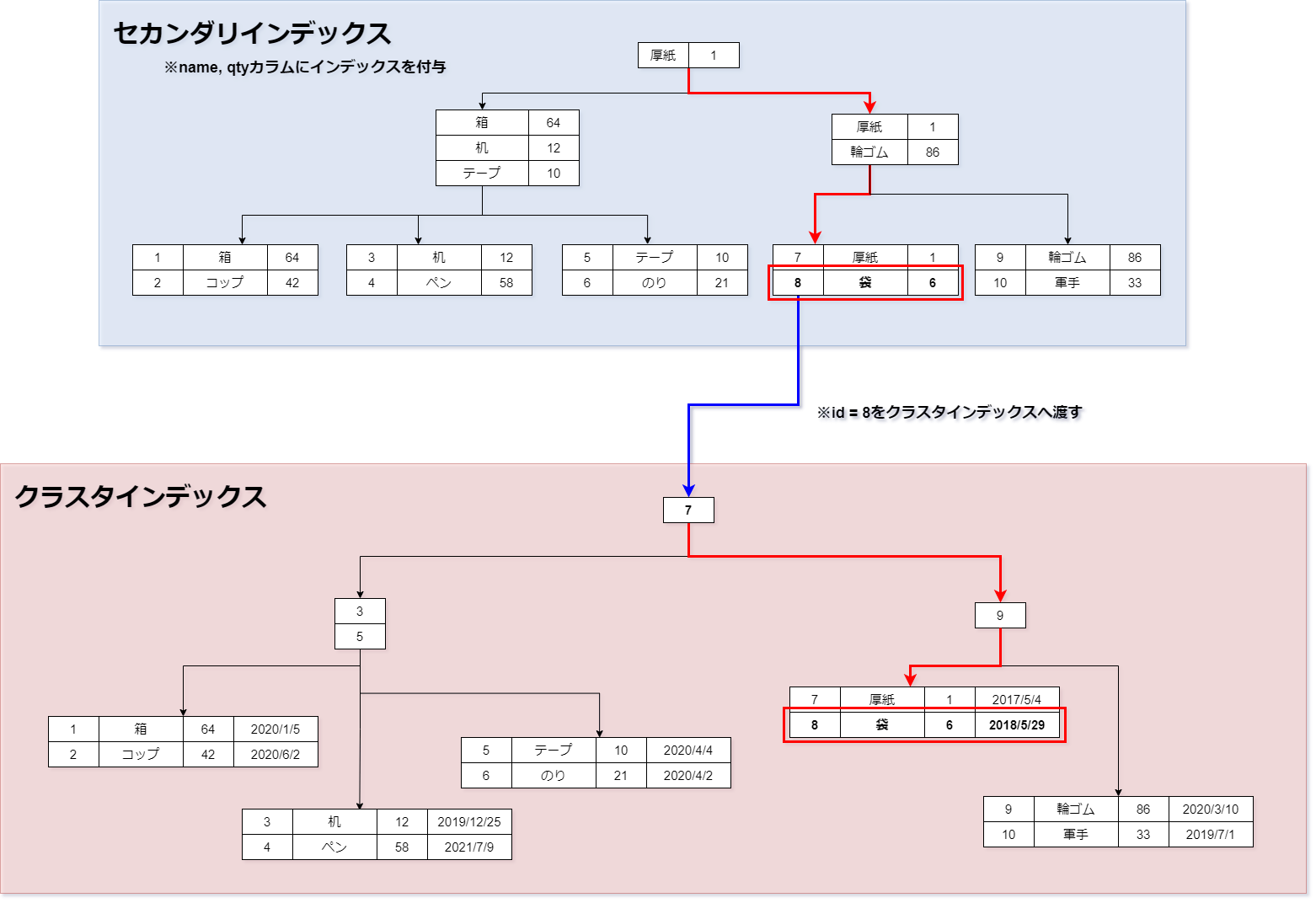
カバリング(Covering) = 網羅 という意味です。 インデックスでのデータ検索は、セカンダリインデックスとクラスタインデックスが 次の手順を経ることで、データを取得します。- 検索対象カラムがセカンダリインデックスに存在しないとき
セカンダリインデックス
↓
クラスタインデックス
※セカンダリインデックスから渡された主キーをもとに、クラスタインデックスで検索データを見つける。
- 検索対象カラムがセカンダリインデックスに既に存在するとき
セカンダリインデックス
↓
検索終了(クラスタインデックスにはアクセスしない)

カバリングインデックスとなるSQL例
セカンダリインデックスのみでデータの取得が完結するSQL例です。
SELECT id, name, qty FROM SAMPLE_TABLE
WHERE name = '袋';
SELECT name FROM SAMPLE_TABLE
WHERE qty = 6;
SELECT id, qty FROM SAMPLE_TABLE
WHERE id = 8;
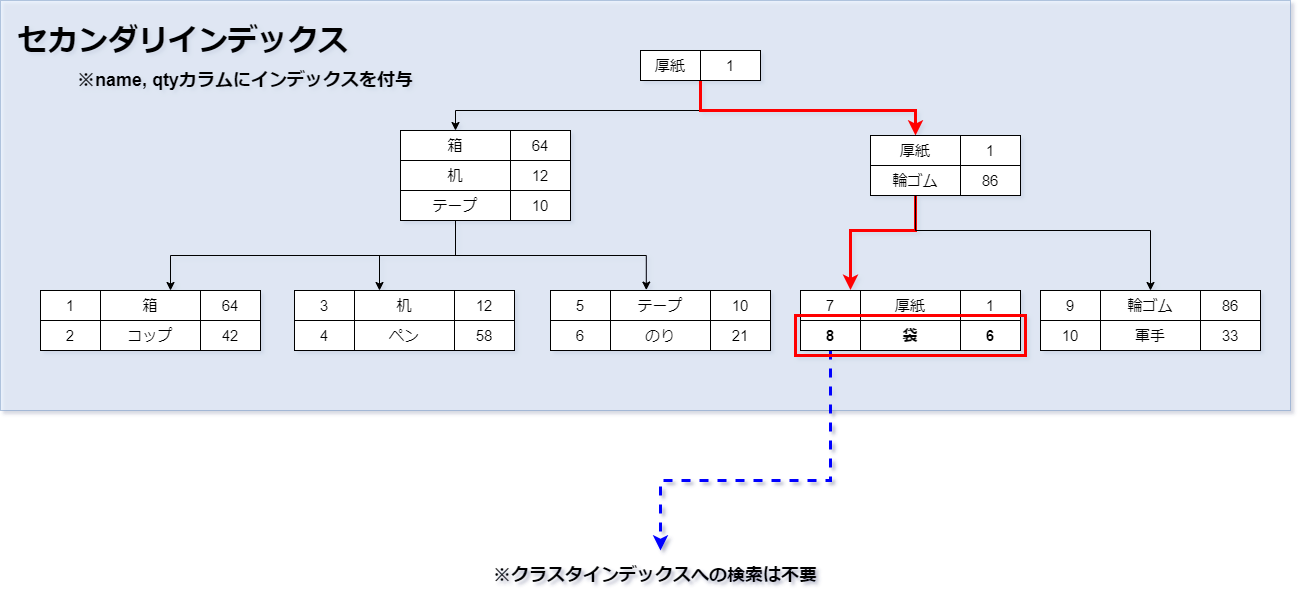
カバリングインデックスとならない例
セカンダリインデックス → クラスタインデックスでデータを取得するようなSQL例です。
SELECT date FROM SAMPLE_TABLE
WHERE name = '袋';
SELECT * FROM SAMPLE_TABLE
WHERE id = 8;
SELECT id, name FROM SAMPLE_TABLE
WHERE date = '2018/5/29';
まとめ
- テーブルの全データは、クラスタインデックスというインデックスに保持される。
- セカンダリインデックスは、明示したカラムのインデックスが保持される。
- セカンダリインデックスのみ、クラスタインデックスのみで検索データの取得が完了することを、カバリングインデックスという。
- 検索パフォーマンスを上げるには、カラムに必要な分だけ複合インデックスを付与し、適切なSELECT、WHEREを意識する。