MAGAZINE
ルーターマガジン
PDF内の表をスクレイピングしてCSV変換する

こんにちは。エンジニアの増田です。 昨今、様々なシチュエーションで透明性が叫ばれ、官公庁や地方自治体でもデータ公開が増えております。しかし、外向けのデータ公開に慣れていなかったり、既存ツールの制約上、機械判読が困難なPDF形式でのデータ公開が多いのが現状です。 弊社では2年前からPDFスクレイピングというサービスを提供しています。この技術により、これまで再利用が難しかったPDFからデータを抽出し、CSVやエクセルといった形に変換が可能になりました。 今回はPDFスクレイピングの具体例ということで、PDF内のセル結合された表をCSV変換する事例について紹介します!スクレイピングといえばPythonを使う事例が多いですが、DBとのつなぎ込みに便利なActiveRecordを使いたいため弊社ではRubyでクローラーの開発をしています。
使用するデータセット
東京都保健医療局の
休日・全夜間診療事業実施医療機関一覧(東京都指定二次救急医療機関一覧)を用います。
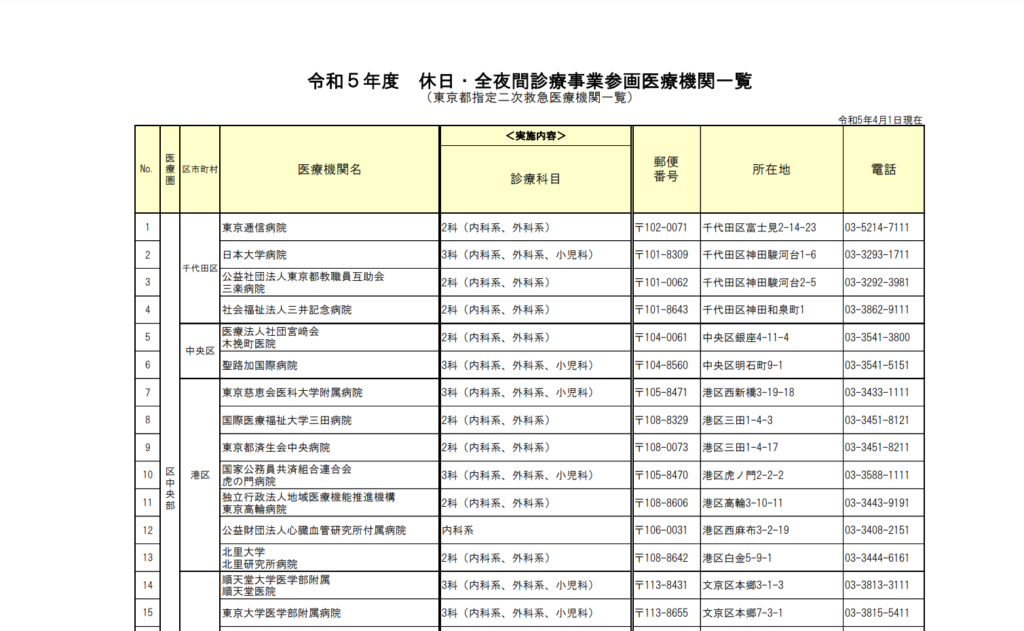
手順
以下の手順でPDFを解析していきます。
- 独自PDFパーサーでPDF→HTMLへ変換
- セル結合を分割する
- NokogiriでHTMLをパースしてCSVへ変換
今回は簡単のために1ページ目だけをCSVに変換していきます。
1. 独自PDFパーサーでPDF→HTMLへ変換
独自PDFパーサーpdf2htmlをrequireして、ファイルパスを渡すと、1ページごとにHTMLに変換し配列で値を得られます。
require_relative 'pdf2html'
file_path = ARGV[0]
htmls = PDF2HTML(file_path)
htmls.each.with_index(1) do |html, idx|
File.open("page_#{idx}.html", 'w') { |f| f.write(html) }
end変換された1ページ目のHTMLをブラウザで開くと、以下のように見えます。ほとんど見たままでHTMLに変換できていますね! 内部的には直接PDF→HTMLではなく、PDF→JSON→HTMLという経路で変換しています。
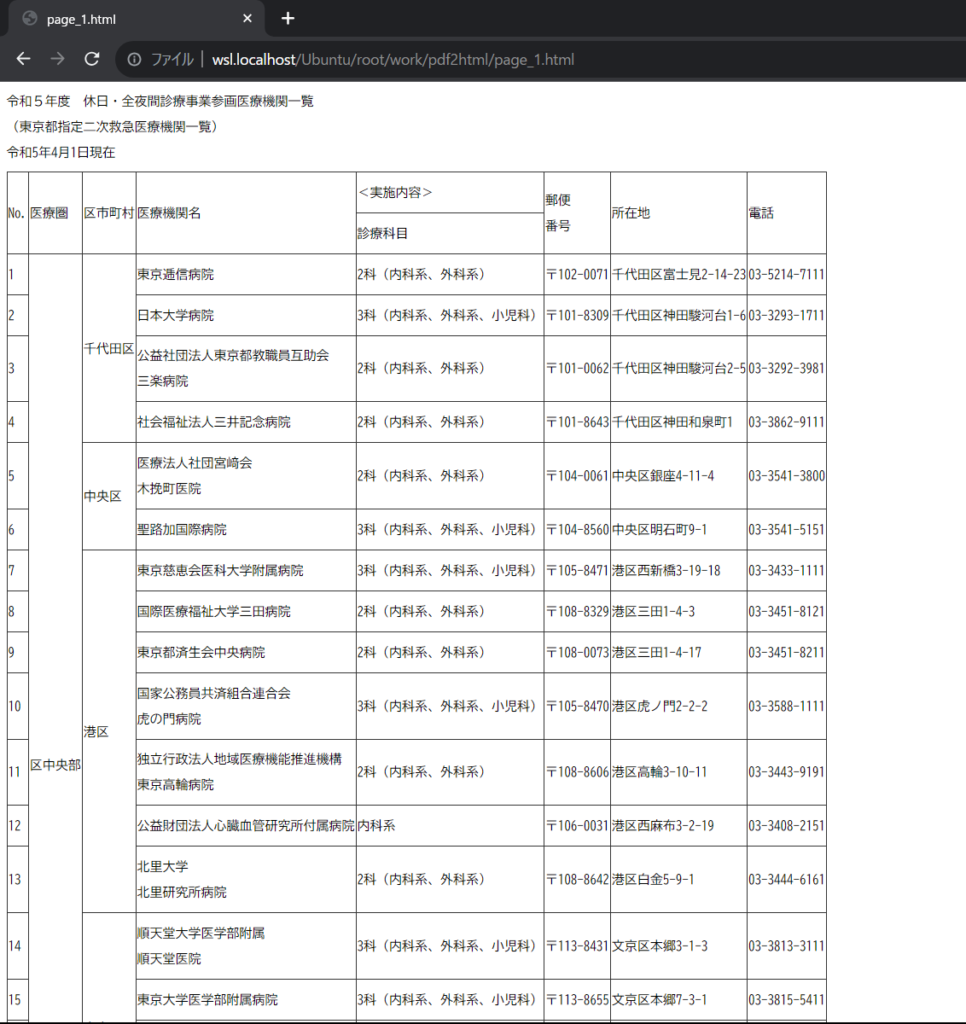
2. セル結合を分割する
セル結合を分割するとはどういう意味かというと、百聞は一見に如かずということで、変換後のHTMLをご覧ください。
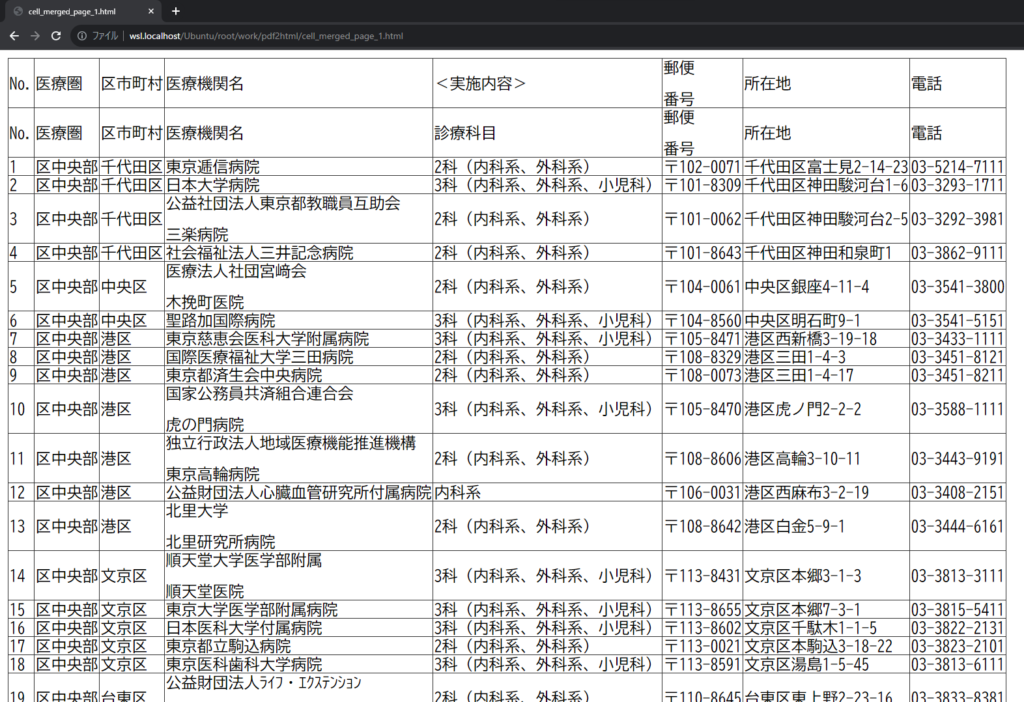
お分かりでしょうか。行方向のセル結合がまたがっている行それぞれにセル結合していない1セルとして”分割”されました!
HTML上のセル結合は、行方向の結合がrowspan、列方向の結合がcolspanの属性で表されます。弊社ではこのようなセル結合されたテーブルをパースすることが頻繁にあるため、このセル結合分割ライブラリも自作しております。
3. NokogiriでHTMLをパースしてCSVへ変換
あとは泥臭くHTMLをパースしていくだけです。ヘッダー行が2行にまたがっているのが若干面倒ですね。最終的なRubyソースは以下のようになりました。
require 'nokogiri'
require 'csv'
doc = Nokogiri::HTML.parse(File.open(ARGV[0]).read)
rows = doc.css('table > tr')
header = []
values = []
rows.each_with_index do |row, idx|
if idx < 2
header << row.css('td').map { |td| td.text.gsub(/\s/, '') }
next
else
values << row.css('td').map { |td| td.text.gsub(/\s/, '') }
end
end
headers = header.transpose.map { |h| h.uniq.join }
CSV.open("sample.csv", "wb", headers: true, force_quotes: true) do |csv|
csv << headers
values.each { |value| csv << value }
end以下が作成されたCSVです。きれいにパースできていますね!

まとめ
今回は弊社サービスのPDFスクレイピングの具体例について取り上げました。
ルーターではDX時代のデータ活用の第一歩となるデータ収集という点で一役買っております。PDFのデータ収集にお困りの際はぜひご相談ください。 お問い合わせはコチラから
CONTACT
お問い合わせ・ご依頼はこちらから