MAGAZINE
ルーターマガジン
動画のOCRをGoogle Cloud Vision APIで安く実現する

Contents
Prelude. ようこそ省力至上主義の動画OCRへ
1. 動画の文字さえ読めばいい。
2. Cloud Vision API のコスト感
3. 開発者様は間引かせたい
4. それでもなお、開発者はコスト削減を求め続ける。
Postludium. 三流開発者は適応的サンプリングの夢を見ない
ようこそ省力至上主義の動画OCRへ
OCR(=Optical Character Recognition, 光学文字認識)は、今日では書類や名刺や手書きのメモ、請求書やレシートなど様々なものを対象として一般的に用いられるようになった、画像から文字を検出し読み取る技術である。OCR自体の歴史は長く、各種機械学習の浸透を通したソフト面・ハード面での進化、ビッグデータの集積と活用が容易に行えるようになったことに伴い、汎化性能については、既に個人ないし1法人がちょっと努力した位では最先端の技術には到底太刀打ち出来ないレベルとなった。この理由の1つは、機械学習が「数で殴る」側面を有しているからであり、数々の機械学習(AI)の代表的・最新モデルの論文を見ていると、googleやMicrosoft、Facebook (AI Research)の名前については、見飽きるを通り越して単純接触効果で好きになっちゃうまである。
したがって、このような領域特化型OCRならまだしも、汎用OCRについては強き者の力を借りてしまうべきなのである。よってこの記事でも、せっせとアルゴリズムを設計するのでなく、Google Cloud Vision APIをベースとして、毛を生やす程度の工夫を行い、安価な動画OCRが可能となった。以下では、画像認識やOCRの知識は必要としないどころか、コードブロックさんには1円のギャラも発生しない。
動画の文字さえ読めばいい。
先に挙げたような世界的企業のアレな超パワーもあり、画像認識はここ10年弱で飛躍的な進歩を遂げた。そんな中でも尚改善の余地に溢れているのが動画解析(行動検出・行動識別、要約、etc.)である。動画は画像を時間軸方向に積み重ねたものであり、一般的な動画解析では時間経過に伴って発生する情報の扱いがメインとなる。そのような、例えば動きのパターンをどこで区切ってどう一般化するのか、といった情報の学習が難しいことは、動画解析の難易度を上げている大きな要因である。(だが、まあおそらく、学習データの不足の影響も大きいため、そちらの改善で解決する面もあるかも知れない。)
一方で、おそらくは動画の編集が容易になったことにより、動画の情報量は映る動物の動きや風景の変化などだけではなく、字幕などの文字が占める割合も増加した。これは、(特にYouTuberが上げるような)ウェブ上の動画や多くのテレビCMを見ればお分かりいただけるだろう。中でも、音声情報のないネットの動画広告や、徐々に増えてきた電車内ビジョンの動画広告では、文字で情報量を補わなければ仕方ないため、より一層重要な情報を持つことになる。

このように字幕が必要となる。
これだけ前フリをすれば(しなくても)気付いた方も多いかも知れない。今回の目的においては(ある意味)経時変化情報を必要としないことに。いくら動画解析が難しいものであり続けているとは言え、時間要素がなくなってしまえば(もちろん各点ごとの時間情報は残すが。)複数の画像の集まりに他ならない。この段階において、動画のOCRという問題は、識別能では人間を超えていると言われることもある画像認識領域まで落とし込まれたのである。
Cloud Vision API のコスト感
この記事でも言及したが、OCRとなるとGoogle Cloud Vision APIを使わない手はないという状況だ。というか、これに勝てるものを作れる自信はない。ゆえに、動画のOCRを行う手法としては、「動画の各フレームをCloud Vision APIによりOCRする」というのが、現時点での最善手の1つであろう。


しかしながら、そこで問題となるのが使用料である。Cloud Vision APIの機能はOCRの他、顔検出、物体検出、ロゴ検出、プロパティ検出、不適切コンテンツ検出など多岐にわたるが、OCR(テキスト検出)の使用料は月当たり、1000リクエストまで無料、以降500万リクエストまでは$1.50/1000リクエスト、それ以降は$0.60/1000リクエストとなる。また、一般的な動画では、1秒当たりのフレーム数は24程度 (24fps) である。これらを基にして愚直にリクエストを投げた場合の使用料を考えると、例えば15秒の広告動画1つでは約360フレームとなるから、月3本まではほぼ無料でOCRできるが、それ以降は1本60円程度、3本でレギュラーないしハイオク1L分(地域差があります。)もの料金を支払うことになる。(2021年11月14日現在、$1.00≒114円)
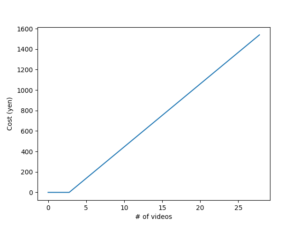
愚直にAPIを利用した場合の、動画数に対する料金増加
開発者様は間引かせたい
流石にこれでは日々増える広告動画を解析することは現実的でないため、使用料の抑え方を考えなくてはいけない。そこでまず考えられるのは、フレームを間引くことである。殊、広告動画のように、メッセージを伝えなければならない動画であるならば、サブリミナル効果を狙うのでもない限り、主要なテキストは一定時間以上表示されているはずである。(1秒の間にまともに認識できる文字数は日本語で4〜6文字だと言われている。)そこで例えばOCR対象となるテキストは1秒以上表示されているものとして、フレームのサンプリング間隔を1秒とすると、使用料は1/24、すなわち月70本程度は無料、それ以降も1本当たり2〜3円程度まで抑えることができる。
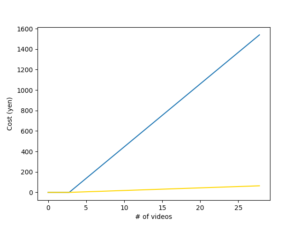
(青):愚直に使用した際の料金増加、(黄):等間隔サンプリングした際の料金増加
使用目的と予算によっては、このラインで充分ということも大いにあるだろう。しかし、例えば先に述べたようなCloud Vision APIの機能のうちOCR以外も使うことを考えた場合、概ね機能ごとに同じ方式で課金されるため、使った機能の分だけ使用料は比例して増加する。では、ここからさらに使用料を抑えるためにはどうすれば良いだろうか。
それでもなお、開発者はコスト削減を求め続ける。
端的に言うと、「1リクエストにフレームを詰め込めるだけ詰め込む」ということになる。前節と合わせてこの記事で最も重要な部分はここで終了である。この方法は別のAPIを使うときに考えていたものだったが、この方法を使うには以下のような条件が満たされている必要があった。
- APIが充分大きなサイズの画像も許容すること。
- 複数のフレームをマージした画像を「1つの画像」であると認識しない程度に認識性能が高いこと。
- 元々の動画のフレームサイズが大きくない(画質が良過ぎない)こと。
1つ目は言うまでもないし、2つ目は文字認識の精度が甘いとマージしてできた大局的な模様を文字だと判定する可能性がある。3つ目は画質を適切に落とせば多くの場合では問題とならないだろうが、場合によっては文字がぼやける原因となる。
奇跡的に、これらの条件をCloud Vision API + 広告動画という組み合わせは全て満たしているのである。Cloud Vision APIは4MBのリクエストまで受け付けるし、条件2を楽々満たす程度に認識性能は高い。また、広告動画はあらゆる視聴環境を想定するためあまり高画質にはならない。
ということで、フレームを縦横にタイルのように貼り付けた画像を作り、それをリクエストとして投げれば良い。その際、ただ単に画像を貼っていってしまうと、いくらCloud Vision APIと言えど隣接フレーム間で文字列が結合してしまう可能性があるため、格子状になるように適宜マージンを設けた方が良い。また、4MBギリギリを攻めるために一旦エンコードしてサイズを見て、余裕があればさらにフレームを足す、という操作が必要になるが、エンコード・デコードを繰り返していく方式の場合は、jpg等の非可逆圧縮でやっているとどんどん劣化していくので注意が必要だ。そのため、途中過程は画像配列を全てメモリに残しておくかpngで保持しておくかして、サイズ確認と最終出力のみをjpgにするなどの対策を要する。
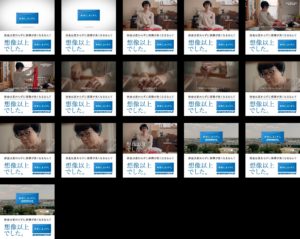
こんな風に。
この場合の費用概算はフレームサイズや動画によって変わってくるため一概には言えないが、上の画像で示したような15〜30秒の広告動画(600*480px程度、サンプリング間隔1秒)を用いた場合、1リクエストのみで済んだ。したがって、動画1本当たり0.171円まで使用料を削減することができたことになる。
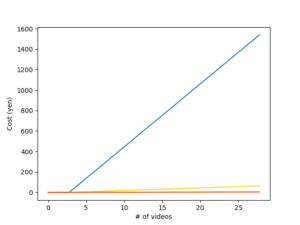
(赤):上記リクエスト削減を施した場合の料金増加。目視では傾きがあるか分からない。
まとめると、本記事では、動画のOCRにGoogle Cloud Vision APIを使用する場合の使用料を、「テキスト表示時間を考慮したフレーム間引き」+「1つの画像に複数のフレームを詰め込む」ことで、1/300〜1/800スケールまで削減することに成功した。この記事のメインはここで終わりになる。
三流開発者は適応的サンプリングの夢を見ない
前節の実装からさらにサンプリング数を削減しようとするならば、「間引き」をより適応的に行い、「同じテキストの映るフレームは極力1度しかサンプリングしないようにする」ことになる。理論上は理想的で自然なこの方法は、フレーム敷き詰め法を実装する前の初期段階で考えていたことである。具体的には、この段階で真面目にOCRしてしまうと本末転倒になってしまうので、「大まかにテキストの場所を検出し、文字の識別は行わず、連続的に同じ位置にテキストがあればそれらは同じテキストを表していると見做す。」という考え方を基本とし、テキストの変化の検知、サンプルすべきフレームの取捨選択に繋げる。
このように高い性能を求めないOCRであれば、無料で使えるアプリやコードはいくつか存在し、それらを使うことで追加費用をかけずにリクエストを減らすことが可能になる。参考までに詳しく書いておくと、今回調べた中では、EAST Text Detectorが検出精度の観点で比較的有効であった。見たところ日本語でトレーニングした様子は伺えなかったが、結構日本語も認識してくれる。

しかしながら位置同定の精度がそれほど高い訳でなく、偽陽性もやや見られることもあり、等間隔サンプリングを適用した段階から半分程度にサンプル数を減らすことには成功したものの、理想的なレベルまで削減することはできなかった。また、ニューラルネットを通すため、1フレーム当たり1秒程度を要するという欠点もあった。さらには、前2節のコスト削減を適用してしまうと、特にフレームマージの力が大きく、30秒程度の1リクエストで済んでしまう動画であれば、これによる削減効果は表にならないという結果から、適応的サンプリングは実装したものの日の目を見ることはなくなった、、、。
とは言っても、必要な開発コストさえかければこの手法は有効になるはずであり、やり甲斐のあるテーマでもあるはずだ。(あらゆるテロップが同じタイミングで現れて消える訳ではないため、やってみると奥が深い。)しかしながら実用レベルの目的はすでに達成しているし、トレーニングデータもなければ開発にかけるエネルギーも私にはないため、興味のある方がいれば取り組んでみてもらいたい。
CONTACT
お問い合わせ・ご依頼はこちらから