MAGAZINE
ルーターマガジン
7セグメントディスプレイを機械学習を使わずにOCRする

時計、気温・湿度計、体重計、ここ最近では外を歩けば見ない日はない体温計、個人的な話をすれば研究室のメダカの水槽の水温計など、大なり小なり各所で目に触れる7セグメントディスプレイ。Raspberry Piなども蔓延る現代ではセンサー内蔵で数値データをダイレクトにPCに送るような機器を挙げれば枚挙に遑がないのであろうが、「既存のディスプレイ付きセンサー(およびカメラ)を活かしたい」、あるいは工場などでの大きな機械となれば、「(ディスプレイのある)現行設備をそう簡単に置き換えることはできない」といったケースも考えられる。そうした際、ディスプレイの文字を読み取る技術がOCRである。
OCRの簡単な説明はこちらの記事に譲るとして、今日日OCRないし文字認識と言えば、各種機械学習の登場・発展によってかなりの精度まで来たと言って良いだろう。況んや数字をや。今回扱う7セグメントはMNISTなどの数字と正確な形状は異なるとは言え、骨格や、端点交点のトポロジーは同じであるので、条件さえ整えばMNISTでもいくらかは太刀打ちできるかもしれないし、事前学習としては活かせる可能性が高い。しかしながら機械学習、殊、ディープラーニングに関しては、
- トレーニングデータを用意するのに多大な労力を要する。
- (然るべきマシンパワーがなければ、)計算(文字認識)に時間がかかる。
といった弱点があるのは広く知られる所である。今回も例に漏れず、トレーニングデータは無ければ、目標は比較的簡素なマシンでも動くようにすることなのだった。
そこでこの記事では、トレーニングデータ0、一切の機械学習を使わずに実装した7セグメントディスプレイOCRについて解説する。
用語の意味
- blob 画像解析においては、2値画像において背景を黒としたとき、個々の白の連結領域を表す。単語自体の意味は「シミ」など。
- ROI = Region of Interest. 画像解析においては、その時点で解析対象としていたり、注目していたりする領域。
- ROD = Region of a Digit. 独自の単語。処理の中で1つ1つの数字を囲むbounding boxを求めるが、1つの数字を囲むbounding boxの内部領域をRODという。
想定する撮影環境
- 撮影角度は、ディスプレイ真正面に限らない。ディスプレイの形が歪んで見えるような画角でも良い。
- ディスプレイの左右方向への傾きは、両方向45°未満とする。
- ディスプレイの形状は、(四隅が丸くなっていない)矩形。
概略
1. ディスプレイを検出する。
- エッジ検出
ディスプレイの輪郭を検出するため、エッジを抽出する。 - ディスプレイ輪郭の推定
抽出されたエッジ情報から、ディスプレイの輪郭を推定する。 - ディスプレイ位置情報の保存
ディスプレイの輪郭から、位置情報をjsonに書き出す。
2. 数字を読み取る。
- 台形補正
画角によるディスプレイの歪みを補正する。 - ROI内のセグメンテーション
"ON"になっているセグメントをピクセルレベルで検出する。 - RODの検出・取捨選択
"ON"になっているセグメントをピクセルレベルで検出する。(セグメンテーション) - ROD内の再セグメンテーション
"ON"になっているセグメントをピクセルレベルで検出する。(セグメンテーション) - 7セグメントの状態推定・数字の分類
数字を識別して情報をjsonに保存する。
3. SSOCRとの比較
4. Google Cloud Vision APIとの比較
必要なライブラリ等
環境 : Python3.9.7
# -*- coding: utf-8 -*-
import argparse
import cv2 as cv
import json
import numpy as np
import os
import time
from util import differential # 自前(ラプラシアンフィルタによる微分処理)
ディスプレイを検出する
エッジ検出
ディスプレイを矩形として検出するため、まずはエッジを抽出する必要がある。これについて、以下のような代表的な方法が考えられたが、それぞれ次のような欠点がある。
- Cannyのエッジ検出
経験的にこうしたデータの自由度の高いケースで上手くいった試しがない。パラメータ調整が感覚的に分かりづらい。 - 微分フィルタ単体
実データではノイズ等の影響が大きく、検出したいエッジが途切れたり、不要なエッジを検出しやすい。 - ガウシアンフィルタ+微分フィルタ
ノイズ除去のためにガウシアンフィルタを使うと、エッジも平滑化されるため良くない。 - メジアンフィルタ+微分フィルタ
メジアンフィルタはエッジを保存する平滑化フィルタとされるが、原理的にエッジが折れ曲がった角の部分は平滑化されやすい。そのため、今回のケースだとディスプレイの四隅が取れず、正しく検出できない。 - バイラテラルフィルタ
他と比べると処理時間を要する。また、画像によってパラメータを調整する場合もあり、その場合は処理時間の長さがより顕著になる。
そこで、今回平滑化に用いたのが、OpenCVに組み込まれている、edgePreservingFilter (Gastal & Oliveira, 2011)である。バイラテラルフィルタと比べて計算時間は短く、四隅も保存した平滑化が行えた。
def detect(img_path, save_dir=None):
image_basename = os.path.basename(img_path)
image_basename_noext = os.path.splitext(image_basename)[0]
img = cv.imread(img_path)
gray_img = cv.imread(img_path, cv.IMREAD_GRAYSCALE)
height, width = gray_img.shape
gray_img = cv.edgePreservingFilter(gray_img, None, sigma_s=60, sigma_r=.4)

edgePreservingFilterを適用する前(上)と後(下)。

平滑化ができたら、ラプラシアンフィルタを用いてエッジの抽出を行う。その結果からエッジ傾向の強弱で2値化し、輪郭検出で用いる。2値化の閾値は、輪郭検出の結果に応じて調節する。
# 平滑化した画像から閾値に応じてエッジを検出して2値画像とする。
edge_img = np.where(differential(gray_img) < bin_thresh, 0, 255).astype(np.uint8)
ディスプレイ輪郭の推定
形状による輪郭の取捨選択
まずは抽出したエッジから、あらゆる輪郭(閉曲線)をcv.findContoursによって検出する。各エッジの長さも求めている。
# 輪郭検出
contours = cv.findContours(edge_img, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)[0]
len_contours = [cv.arcLength(contour, True) for contour in contours]

赤い部分が検出された輪郭。
ここで検出した輪郭にはディスプレイ以外にも様々なものが含まれるため、条件を設定してディスプレイである確率の高い輪郭を推定して残す。考慮したディスプレイ輪郭の特徴は以下になる。
- 輪郭長が、画像の外周長と比べて一定以上大きい
撮影される画像では、目的のディスプレイはある程度の大きさで写っているはずだから。 - 輪郭を多角形近似した際に凸四角形となる
ディスプレイの想定形状から。 - 近似多角形の画像垂直方向の大きさと水平方向の大きさがそれぞれ画像の高さ、幅に比べて一定値以上大きい
極端に細長いディスプレイは実運用上あまり想定されず、一方で誤って検出される輪郭にはこのタイプが一定数見られるため。
これらを全て満たす輪郭を有効な輪郭として残した。詳細は以下のようになる。
for arclen, contour in sorted(list(zip(len_contours, contours)), key=lambda x: x[0], reverse=True):
if (0 < len(valid_contours) and arclen < 2 * (height + width) * min_scale) or 0 == arclen: break
contour = cv.approxPolyDP(contour, .05 * arclen, True)
if not cv.isContourConvex(contour): continue
if 4 != len(contour): continue
# Check the length of each edge.
if max(abs(contour[0][0][0] - contour[1][0][0]), abs(contour[1][0][0] - contour[2][0][0])) <\
width * min_edge_scale:
continue
if max(abs(contour[0][0][1] - contour[1][0][1]), abs(contour[1][0][1] - contour[2][0][1])) <\
height * min_edge_scale:
continue
valid_contours.append(contour)
if arclen < 2 * (height + width) * min_scale: break
else: end_loop = True
if end_loop: break

条件を満たした輪郭。この場合は包含関係にある複数の輪郭は存在しない。
輪郭の包含関係を調べる
ディスプレイ以外にも、画像に他の物体が写っていれば、複数の輪郭が検出されることが想定される。その場合、互いに包含関係にないものについてはどちらも残せば良い。
一方で、機器の輪郭とディスプレイなどのように包含関係にある場合は、ディスプレイ内部には輪郭は検出されないことを想定しているため、最も内側にある輪郭のみを残すようにする。
edge_img = cv.drawContours(np.zeros([height, width, 3], np.uint8), valid_contours, -1, (255, 255, 255), 1)[:, :, 2]
# Discard outer contours.
contours, hierarchy = cv.findContours(edge_img, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
valid_contours = []
if hierarchy is not None:
for contour, hier in zip(contours, hierarchy[0]):
contour = cv.approxPolyDP(contour, .05 * cv.arcLength(contour, True), True)
if 4 != len(contour): continue
if -1 < hier[2]: continue
valid_contours.append(contour)
ディスプレイの位置情報を求める
最終的に残った四角形の輪郭4頂点の情報をjsonとして出力する。次の処理で台形補正を行うため、重要となるのは頂点の位置(どの頂点が左上、左下、右下、右上であるか)と順番、さらにディスプレイのアスペクト比を記録することである。
以下の実装では、
- ディスプレイ左上の頂点を推定し、輪郭情報からその対頂点(右下の頂点)を決定する。
- 対角線との位置関係から、残りの2頂点を決定する。
- 画像上の見た目の長さから、ディスプレイのアスペクト比を求める。
という流れで処理をしている。
ディスプレイに奥行き方向のパースがかかっている場合は、実際の辺の長さと見た目の長さは異なるが、同時に実際の長さの推定もできないため、パースがあまりに強い場合には人間がアスペクト比を修正する必要がある。
dic = {'ROIs': []}
for contour in valid_contours:
xs, ys = np.array([p[0][0] for p in contour], np.int32), np.array([p[0][1] for p in contour], np.int32)
# Find the "top-left" vertex.
idx_p1 = np.argsort(xs + ys)[0]
idx_p3 = (idx_p1 + 2) % 4 # The against vertex.
x1, y1, x3, y3 = int(xs[idx_p1]), int(ys[idx_p1]), int(xs[idx_p3]), int(ys[idx_p3])
idx_p2, idx_p4 = (idx_p1 + 1) % 4, (idx_p1 + 3) % 4
# P_2 and P_4 should be under and over the diagonal from P_1 to P_3 respectively.
if x1 != x3:
m = (y1 - y3) / (x1 - x3)
if m * (xs[idx_p2] - x1) - (ys[idx_p2] - y1) < 0:
x2, y2, x4, y4 = int(xs[idx_p2]), int(ys[idx_p2]), int(xs[idx_p4]), int(ys[idx_p4])
else:
x2, y2, x4, y4 = int(xs[idx_p4]), int(ys[idx_p4]), int(xs[idx_p2]), int(ys[idx_p2])
else:
if xs[idx_p4] < xs[idx_p2]:
x2, y2, x4, y4 = int(xs[idx_p4]), int(ys[idx_p4]), int(xs[idx_p2]), int(ys[idx_p2])
else: x2, y2, x4, y4 = int(xs[idx_p2]), int(ys[idx_p2]), int(xs[idx_p4]), int(ys[idx_p4])
# The ratio of width and height based on the visual length in the image.
w_per_h = ((x3 - x2) ** 2 + (y3 - y2) ** 2) ** .5 / ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** .5
dic['ROIs'].append({'x1': x1, 'y1': y1, 'x2': x2, 'y2': y2, 'x3': x3, 'y3': y3, 'x4': x4, 'y4': y4,
'w/h': w_per_h})
with open('{}.json'.format(os.path.join(save_dir, image_basename_noext)), 'w') as json_file:
json.dump(dic, json_file, indent=2)
return
出力するjsonは以下のようになる。
{
"ROIs": [
{
"x1": 239,
"y1": 375,
"x2": 240,
"y2": 489,
"x3": 406,
"y3": 484,
"x4": 407,
"y4": 371,
"w/h": 1.456744693203718
}
]
}

ディスプレイ検出の結果(検出したディスプレイが赤枠で囲まれている。)
数字を読み取る (OCR)
台形補正
検出したディスプレイは矩形である保証がないため、ディスプレイ検出の段階で算出したアスペクト比を用いて台形補正を行う。また、ディスプレイが複数出力された場合には、位置関係に応じて出力順序を調整している。
def crop_roi(gray_img, rois_json_path=None, debug=False):
# Load ROI information.
with open(rois_json_path) as rois_json: tmp_rois = json.load(rois_json)['ROIs']
if tmp_rois is None or 0 == len(tmp_rois): return []
# Sort ROIs by position.
rois = []
if 'w/h' in tmp_rois[0]:
for roi in tmp_rois: rois.append((roi['y1'], roi['x1'], roi['y2'], roi['x2'],
roi['y3'], roi['x3'], roi['y4'], roi['x4'],
roi['w/h']))
rois = roi_sort(rois, gray_img.shape[0], gray_img.shape[1], horizontal=False)
else:
for roi in tmp_rois: rois.append((roi['y1'], roi['x1'], roi['y2'], roi['x2']))
rois = roi_sort(rois, gray_img.shape[0], gray_img.shape[1])
# Collect ROIs as small images.
roi_grays = []
for i, roi in enumerate(rois):
if 9 == len(roi):
ys = roi[:-1:2]
h_after = max(ys) - min(ys)
w_after = int(h_after * roi[-1])
roi_before = np.float32([[roi[2 * _ + 1], roi[2 * _]] for _ in range(4)])
roi_gray = keystone_correction(gray_img, roi_before, (w_after, h_after))
else:
y1, x1, y2, x2 = roi
roi_gray = gray_img[y1:y2 + 1, x1:x2 + 1].copy()
if debug: save_in_debug('./roi_image/', roi_gray, i)
roi_grays.append(roi_gray)
return roi_grays

台形補正(+ディスプレイ抽出)を行う前(上)と後(下)

RODの検出
7セグメントの各セグメントの間には隙間が空いていることが多いが、RODの検出は、それらのセグメントを連結させ、同じ数字に属するセグメント同士を連結させた状態で行う。具体的には、ディスプレイ内部を2値化し、膨張処理などで連結させ、各数字に対するbounding boxを求める。
# OCR in each ROI.
for roi_gray in roi_grays:
digits_json, rods_img = crop_digits(roi_gray)
json_output['data'] += digits_json['digits']

赤枠で囲まれているそれぞれがROD。
ディスプレイ内部の2値化
続いて、ディスプレイ内部を2値化することを考える。7セグメントディスプレイのタイプとしては、セグメント部分がONのときに黒くなるものと、発光するなどして明るくなるものの2通りがあり、これを自動識別するのは難しい問題である。そのため、現在は数字が黒く表示されるもののみを考慮し、デフォルトで画素値の反転を行なっている。
また、実際に扱う画像は比較的コントラストが弱く、上手く2値化が行われなかったため、cv.createCLAHE()によりコントラスト強調を行なっている。
MIN_ROD_CONTRAST = 32
def crop_digits(roi_gray):
KERNEL_4N = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]], dtype=np.uint8)
roi_gray = roi_gray.copy()
roi_gray_enhanced = cv.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)).apply(roi_gray)
height, width = roi_gray_enhanced.shape
EDGELEN_PERCENT = (height + width) / 200
EDGELEN_PERCENT_LONG = max(height, width) / 100
rods = [] # ROD = Region of a Digit
rods_img = np.zeros([height, width], np.uint8)
roi_gray_enhanced = np.bitwise_not(roi_gray_enhanced)
roi_gray = np.bitwise_not(roi_gray)

コントラスト強調・反転の結果。
2値化の際に気をつけなくてはならないのが、ディスプレイ外縁部の影と、ディスプレイ内部の罫線の影響である。機器に嵌め込まれているタイプのディスプレイであると、外側に影が出来やすく、2値化の結果この影が数字と繋がってしまうと、その後分離するのが非常に面倒になる。罫線についても同様であり、早い段階で簡単に除けるものは除去しておくことが望ましい。
そこで、理想的ではないが仮の処理として、ディスプレイの外側に対しては閾値を厳しく取る形で、外縁部の影が検出されにくくなるようにしている。仮に7の横線や2の最後の横線といった外側にあるセグメントが検出されなくても、後続の処理で修正可能である。
# Remove shadows near the display contour.
inner_x1, inner_x2 = int(width * .02), int(width * .98)
inner_y1, inner_y2 = int(height * .05), int(height * .95)
roi_bin_inner = cv.adaptiveThreshold(roi_gray_enhanced[inner_y1:inner_y2, inner_x1:inner_x2], 255,
cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY,
max(int(min(height, width) / 2 * .5), 1) * 2 + 1, 2)
digits_brightness = np.mean(roi_gray_enhanced[inner_y1:inner_y2, inner_x1:inner_x2][roi_bin_inner > 127])
roi_bin = cv.threshold(roi_gray_enhanced, 255, digits_brightness, cv.THRESH_BINARY)[1]
roi_bin[inner_y1:inner_y2, inner_x1:inner_x2] = roi_bin_inner.copy()
tmp = cv.erode(roi_bin.copy(), KERNEL_4N, iterations=int(EDGELEN_PERCENT / 4 * .5) + 1)
_, labels, stats = cv.connectedComponentsWithStats(tmp)[:3]
for i, stat in enumerate(stats):
if 0 == min(stat[0], stat[1]) or width == stat[0] + stat[2] or height == stat[1] + stat[3]:
roi_bin[i == labels] = 0
また、例えば数字のセグメントがディスプレイの上端付近から下端付近まで連なるようなことは考えにくいため、各行または各列について、一定以上の画素が白になっている場合、罫線があるものとみなしてその行または列は全て画素値を0としている。
# Cut off bright area near the display contour and long bright line.
tmp = roi_bin.copy()
for i, bright in enumerate(np.count_nonzero(roi_bin, axis=1)):
if bright < width * .8: continue
tmp[i, :] = 0
for i, bright in enumerate(np.count_nonzero(roi_bin, axis=0)):
if bright < height * .95: continue
tmp[:, i] = 0
roi_bin = tmp.copy()
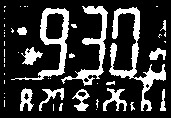
2値化の結果
ノイズ除去
セグメントを連結させる際には膨張処理を行うが、その際にノイズが残っていると、ノイズのサイズも大きくなり性能低下の要因となる。そこでここでは、
- サイズ・形状から、セグメントや複数のセグメントが連結したものである可能性が低いblobを除去する。
- ディスプレイ内に見られることのある細い罫線をオープニング処理により除去する。
- 残った微小なblobを除去する。
という3段階のノイズ除去処理を行なっている。
# Remove blobs which is not a segment or a digit.
labels, stats = cv.connectedComponentsWithStats(roi_bin)[1:3]
for i, stat in enumerate(stats):
left, top, w, h = stat[:4]
if roi_bin[i == labels][0] < 128: continue
right, bottom = left + w, top + h
if not is_digit_or_segment((top, left, right, bottom, stat[4])):
roi_bin[i == labels] = 0
def is_digit_or_segment(roi):
top, left, right, bottom, area = roi
height, width = bottom + 1 - top, right + 1 - left
h_per_w = height / width
if area / (height * width) > .99 or area / (height * width) < .1: return False
if area / (height * width) > .85 and .5 <= h_per_w <= 2: return False
if h_per_w < .3 or h_per_w > 10: return False
return True
ここで、「セグメントや複数のセグメントが連結したものである可能性が低い」とは、具体的には、
- 自身を囲むbounding boxに対して、自身の面積が99%より大きいか10%未満
- 自身を囲むbounding boxに対して自身の面積が85%以上であり、かつbounding boxの(高さ)/(幅)が0.5以上2以下
- bounding boxの(高さ)/(幅)が0.3未満か10より大きい のいずれかを満たすものである。
それぞれ、
- あらゆるセグメントの複合体やセグメントについて、bounding boxに対して過剰に占有率が大きく、あるいは小さくはならないはずである。
- 単一のセグメントまたは"1"を除く、折れ曲がりを含むblobについてはその形状から、bounding boxに対する占有率が一定程度低くなるはずである。
- 横方向に長いセグメント、あるいは"1"について、そのbounding boxの(高さ)/(幅)の値は、現実のほとんどの場合において一定の値より小さく、あるいは大きくはならないはずである。
ということに基づいて設定している。


1段階目の処理の前後比較。右の結果では、右端の縦に長いblobなどが除去されている。
# Remove thin lines.
roi_bin = cv.erode(roi_bin, KERNEL_4N, iterations=int(EDGELEN_PERCENT / 2 * .5) + 1)
roi_bin = cv.dilate(roi_bin, KERNEL_4N, iterations=int(EDGELEN_PERCENT / 2 * .5) + 1)
# Remove tiny blobs.
labels, stats = cv.connectedComponentsWithStats(roi_bin)[1:3]
for i, stat in enumerate(stats):
if roi_bin[i == labels][0] < 128: continue
if is_dust(stat[4], height, width): roi_bin[i == labels] = 0

2,3段階目の処理の前(上)と後(下)

RODの検出・取捨選択
ノイズ除去が完了したら、膨張処理を行なって互いに位置が近いblobを連結させる。
膨張後は、ノイズ除去の際と異なり、この段階では同じ数字に属するセグメントは全て連結していると仮定している。そのため、1つの数字として妥当であるかを、形状等から判定し、相応しくないものは解析対象から除外する。
RODの形状・サイズによる取捨選択
roi_bin_fat = cv.dilate(roi_bin, KERNEL_4N, iterations=int(EDGELEN_PERCENT * .5) + 1)
n_labels, labels, stats = cv.connectedComponentsWithStats(roi_bin_fat)[:3]
json_digits = {'digits': []}
for i, stat in enumerate(stats):
left, top, w, h = stat[:4]
if np.min(roi_bin_fat[i == labels]) < 128: continue
right, bottom = left + w - 1, top + h - 1
if not rod_thresholding((top, left, right, bottom, stat[4]), height, width, max_area_ratio=.4):
continue
(続く ※1)
ここでは、
- ディスプレイに比べて一定程度大きい。
- (高さ)/(幅)が一定範囲内に収まっている。
- (高さ)/(幅)が小さく"1"でないと考えられるRODについては、RODの面積より一定程度blobの面積が小さい。
最後の条件は、"1"以外の数字に対してbounding boxを取ると、その形状からbounding box内部に「背景領域」が多く存在することになるためである。(下図参照)

これらの条件を満たすものを適当なRODとして選択している。
def rod_thresholding(roi, image_height, image_width, min_area_ratio=.0025, max_area_ratio=.2,
min_height_per_width=.5, max_height_per_width=10,
min_height_ratio=.15):
top, left, right, bottom, area = roi
image_area = image_height * image_width
if (bottom + 1 - top) / image_height <= min_height_ratio:
if area / image_area <= min_area_ratio: return False
if area / image_area >= max_area_ratio: return False
h_per_w = (bottom + 1 - top) / (right + 1 - left)
if h_per_w <= min_height_per_width: return False
if h_per_w >= max_height_per_width: return False
if h_per_w <= 4 and area / ((bottom + 1 - top) * (right + 1 - left)) > .85: return False
return True
コントラストによる取捨選択

ここまでの処理によると、この画像の"9"の左に見られるようなぼんやりとした黒い領域(ここでは「午後」の文字)のようなコントラストの低い領域なども検出されることがわかった。一方で、この画像からもわかるように、写真全体のコントラストが一定程度あれば、数字と周辺領域のコントラストは比較的高くなることがわかる。したがって、コントラストに一定の基準を設けることで偽陽性を減らすことができる。
ここでは、cv.createCLAHEによりコントラスト強調を行う前の元画像を用いてコントラストの強弱を判定する。
(続き ※1)
# Remove low contrast area. (ex. shadow but not a digit)
rod_gray = roi_gray[top:bottom+1, left:right+1].copy()
height_rod, width_rod = rod_gray.shape
nth = width_rod * height_rod // (40 if height_rod / width_rod > 3 else 12)
min_value = np.partition(rod_gray.ravel(), nth)[nth]
rod_gray[(i != labels)[top:bottom+1, left:right+1]] = min_value
if np.max(rod_gray) - min_value < MIN_ROD_CONTRAST: continue
(続く)
低コントラスト領域の除去

低コントラスト領域を誤検出することによる弊害は、数字と影が連結するような場合にも起こり得る。この画像では、"7"の左上の影をblobとして検出し、それが"7"と連結することで、本来検出するべき領域よりも(横に)過剰にRODが検出されている。このようにRODが適切に取られない場合、後述する数字識別の処理の際に悪影響が生じるため、こうした数字と連結した低コントラスト領域を極力除去する処理が必要である。
そこでここでは、RODの上端・下端・左端・右端から各行・列のコントラストを走査し、一定以上強いコントラストが見られるまでRODを削っていく処理を行なっている。
(続き)
# Remove low contrast outer area.
nth = -(width_rod // 40)
for i in range(height_rod):
if np.partition(rod_gray[i, :], nth)[nth] < min_value + MIN_ROD_CONTRAST: continue
top += i
break
for i in range(height_rod - 1, -1, -1):
if np.partition(rod_gray[i, :], nth)[nth] < min_value + MIN_ROD_CONTRAST: continue
bottom -= height_rod - 1 - i
break
nth = -(height_rod // 40)
for i in range(width_rod):
if np.partition(rod_gray[:, i], nth)[nth] < min_value + MIN_ROD_CONTRAST: continue
left += i
break
for i in range(width_rod - 1, -1, -1):
if np.partition(rod_gray[:, i], nth)[nth] < min_value + MIN_ROD_CONTRAST: continue
right -= width_rod - 1 - i
break
rods.append((top, left, right, bottom, None))
rods = roi_sort(rods, height, width)
その結果、このように余計な領域を除去することができる。
ROD内部の再セグメンテーション
ここまで行なっていた2値化は、RODを検出するためのものであり、ROI全体を参照して大まかに行なっている。具体的には、
- 同じ数字を構成するセグメントは連結させる必要があるので、偽陽性(セグメントでない部分をセグメントとして検出すること)をある程度許容しており、それが数字の分類の際に悪影響を及ぼす必要がある。
ということである。 そのため、個々のRODについて別途2値化を行えば、数字識別の段階でより良い結果が得られる可能性がある。そこで、ROD検出の段階での問題
- 部分的に入る影の誤検出(偽陽性)が多い。
- ディスプレイの外縁部に影が生じやすく、
- 偽陽性が多く、数字とコロンや"℃"、検出目標としていない小さな数字などのblobが連結して数字の識別に悪影響を及ぼす。
の軽減・解消を行う。
凹凸係数を用いた2値化
改めて2値化を行うことになるが、ここで、ROD検出の初めに行ったコントラスト強調は、上で挙げた様々な影も強調するという弊害があるため、コントラスト操作前の画像を参照する。 ROD検出の段階で用いたcv.adaptiveThreshold( )は、一般的にはシェーディングに強い2値化手法とされているが、今回の応用では良い結果が得られなかった。そこで今回は、凹凸係数(Sato & Sato, 2007)を用いている。
# Compute unevenness coefficient.
ksize = int(EDGELEN_PERCENT_LONG * 5 * .5) * 2 + 1
_ksize = int(EDGELEN_PERCENT_LONG * .5) * 2 + 1
uneven = np.where(roi_gray / cv.blur(cv.medianBlur(roi_gray, _ksize), (ksize, ksize)) > 1.01, 255, 0).astype(np.uint8)
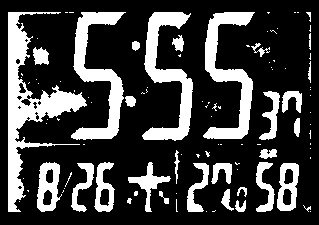

ROD検出の段階での2値化結果(左)と凹凸係数を用いた2値化結果(右)
凹凸係数による手法は、その計算式より、シェーディングに強いと同時に局所的に画素値の低い箇所は前景として検出しにくいため、わずかしか離れていない隣接セグメントなどについても分割されるという特徴がある。
ディスプレイ外枠の影の除去・異常形状blobの除去
ディスプレイ外縁部の影を明度分布情報のみから判定するのは困難であるため、以下のようにしてその影響を軽減した。
- 一定の値によってディスプレイを「外縁部」「中央部」「それ以外(マージン)」の3領域に分ける。このとき、閾値は経験的に決めるが、外縁部にはほとんどセグメントは存在せず、中央部には外枠による影と繋がったblobがほとんど生じないように、「安全な値」を定めることを想定する。すなわち、機器やディスプレイ検出の結果によってセグメントや外枠の影が存在したりしなかったりする範囲はマージンとする。
- 一部分でも外縁部に含まれ、中央部には含まれないblobは、「外枠の影である可能性が高い」と判断される。
- また、ディスプレイに対してかなり大きいblobについても、「外枠の影である可能性が高い」と判断される。
- 「外枠の影である可能性が高い」blobについては、画像の各行におけるそのblobが占める割合を計算する。各行について、割合が異常に高い場合、当該blobに属する画素のうち、その行内のものを全て除去する。
上記の初めの3項目は極力多くの種類のディスプレイに対応するための処置であるが、最終項目については詳しく説明する。
このような場合に外枠の影(画像では外側に四角く1周繋がった白い領域として見える。)を除去することを考える。
外枠の影のblob全体を除去してしまうと、それと連結する"5"のセグメントも消えてしまい、後続の処理に弊害を及ぼす。そこで、主にOCR自体に悪影響を及ぼすのは上辺と下辺だけであるため、そこだけの除去を目標とすると、上辺と下辺の、「画像の1行のほとんどをこれらの影が占める」という特徴が利用できる。すなわち、極端に自身の占める割合が大きくなる行のみを除去対象とすれば、以下のように、上下にある影を除去できる。

ちなみにここでは、極めて小さいblobをノイズとして除去する処理と、面積に対して外周が長いblobを除去する処理も行っている。特に後者は、セグメントは輪郭が比較的直線的であり、太さもあることから、面積に対する外周長が小さくなる傾向があることを利用している。
# Define inner and outer area.
outer_left, outer_right = int(width * .04), int(width * .96)
outer_top, outer_bottom = int(height * .04), int(height * .96)
inner_left, inner_right = int(width * .1), int(width * .9)
inner_top, inner_bottom = int(height * .1), int(height * .9)
inner_area[inner_top:inner_bottom+1, inner_left:inner_right+1] = 255
outer_area[outer_top:outer_bottom+1, outer_left:outer_right+1] = 0
_, labels, stats = cv.connectedComponentsWithStats(uneven)[:3]
for i, stat in enumerate(stats):
# Remove tiny blobs.
if height * width / 1000 > stat[4]:
uneven[i == labels] = 0
continue
# Remove shadows near by the display edge.
is_outer = np.bitwise_and(i == labels, outer_area).any()
is_inner = np.bitwise_and(i == labels, inner_area).any()
if stat[2] > min(height, width) / 2 or (is_outer and not is_inner):
hsizes = np.count_nonzero(i == labels, axis=1)
uneven[((i == labels).T & (hsizes > np.mean(hsizes) + 1.5 * np.std(hsizes))).T] = 0
continue
# Remove anomaly shaped blobs.
target_blob = np.where(i == labels, 255, 0).astype(np.uint8)
arclength = np.count_nonzero(target_blob - cv.erode(target_blob, KERNEL_4N, iterations=1))
if stat[4] / arclength < 2:
uneven[i == labels] = 0
continue
7セグメントの状態推定・数字の分類
# Convert to digit.
for rod in rods:
rod_bin = uneven[rod[0]:rod[3]+1, rod[1]:rod[2]+1]
json_digits['digits'].append(rod2digit(rod, rod_bin))
rod = json_digits['digits'][-1]
rods_img[rod['top']:rod['top']+rod['height']-1, rod['left']:rod['left']+rod['width']-1] = 255
RODごとに、数字の分類を行う。分類は、7つのセグメントのうちどこがONになっているかを推定し、それを基にして表示されている数字を推定するという流れで行う。
セグメントのON/OFFの判定は、以下のように行う。
RODを左・中央・右の領域ができるように3等分し、左右の2領域はさらに上下に2等分、中央の領域は上・中央・下の領域ができるように3等分する。すると、7つのセグメントは、おおよそ今できた7つの領域それぞれに含まれていると期待される。これを利用して、各領域において一定の条件により対象となるセグメントの状態を決定する。

def rod2digit(rod, rod_bin):
height_rod, width_rod = rod_bin.shape
_, labels, stats = cv.connectedComponentsWithStats(rod_bin)[:3]
# Remove tiny blobs.
for i, stat in enumerate(stats):
left, top, w, h = stat[:4]
if max(w, h) < min(width_rod, height_rod) * .15: rod_bin[i == labels] = 0
if height_rod / width_rod > 3: read_digit = 1
else:
vline1, vline2 = width_rod // 3, width_rod * 2 // 3
hline1, hline2, hline3 = height_rod // 3, height_rod // 2, height_rod * 2 // 3
segments = [rod_bin[:hline1, vline1:vline2], rod_bin[:hline2, :vline1], rod_bin[:hline2, vline2:],
rod_bin[hline1:hline3, vline1:vline2], rod_bin[hline2:, :vline1], rod_bin[hline2:, vline2:],
rod_bin[hline3:, vline1:vline2]]
is_verticals = [False, True, True, False, True, True, False]
ret_vals = [64, 32, 16, 8, 4, 2, 1]
read_digit = SEGMENTS2DIGIT[sum(list(map(ison, segments, is_verticals, ret_vals)))]
if -1 == read_digit and np.max(np.count_nonzero(rod_bin, axis=0)) / max(1, np.max(np.count_nonzero(rod_bin, axis=1))) > 3.5:
read_digit = 1
return {'digit': int(read_digit), 'left': int(rod[1]), 'top': int(rod[0]),
'width': int(width_rod), 'height': int(height_rod)}
ディスプレイの仕様等によって、各領域に占めるセグメントの割合は異なるため、以下の関数isonのようなON/OFF判定を行う。これにより、セグメントの太さの影響をなくし、ハイライトなどによってセグメントの一部分が検出できなかった場合などでも正しくセグメントの状態を推定することが可能となる。 また、アルゴリズムの仕様上、"1"については"ON"になっているセグメントしか検出できないため、別途判定している。
def ison(roi_bin, is_vertical: bool, ret_val: int) -> int:
if is_vertical:
thresh = roi_bin.shape[0] * .6
if (np.count_nonzero(roi_bin, axis=0) > thresh).any(): return ret_val
else:
thresh = roi_bin.shape[1] * .7
if (np.count_nonzero(roi_bin, axis=1) > thresh).any(): return ret_val
return 0
各セグメントのON/OFFは2値で表され、7セグメントの状態は下記のように7桁の2進数128通りで表す。
ここで、全てのRODは0〜9いずれかの数字に対応していると期待できるため、各RODに対して1つの数字が割り当てられるべきである。しかしながら、実際にはセグメントではないノイズがRODとして検出されたり、7セグメントのうちいくつかのセグメントが検出できなかったりする。
そこで、本来表示されていると考えられる数字が一意に決定できる場合、仮に1つのセグメントが誤ってOFFと推定されている状態でも、本来の数字が表示されていると推定するようにして、頑健性を高めている。
SEGMENTS2DIGIT = {0b0000000: -1, 0b0000001: -1, 0b0000010: 1, 0b0000011: -1, 0b0000100: -1,
0b0000101: -1, 0b0000110: -1, 0b0000111: -1, 0b0001000: -1, 0b0001001: -1,
0b0001010: -1, 0b0001011: -1, 0b0001100: -1, 0b0001101: -1, 0b0001110: -1,
0b0001111: -1, 0b0010000: 1, 0b0010001: -1, 0b0010010: 1, 0b0010011: -1,
0b0010100: -1, 0b0010101: -1, 0b0010110: -1, 0b0010111: -1, 0b0011000: -1,
0b0011001: -1, 0b0011010: 4, 0b0011011: 3, 0b0011100: -1, 0b0011101: 2,
0b0011110: -1, 0b0011111: -1, 0b0100000: -1, 0b0100001: -1, 0b0100010: -1,
0b0100011: -1, 0b0100100: -1, 0b0100101: -1, 0b0100110: -1, 0b0100111: -1,
0b0101000: -1, 0b0101001: -1, 0b0101010: 4, 0b0101011: 5, 0b0101100: -1,
0b0101101: -1, 0b0101110: -1, 0b0101111: 6, 0b0110000: -1, 0b0110001: -1,
0b0110010: 4, 0b0110011: -1, 0b0110100: -1, 0b0110101: -1, 0b0110110: -1,
0b0110111: 0, 0b0111000: 4, 0b0111001: -1, 0b0111010: 4, 0b0111011: 9,
0b0111100: -1, 0b0111101: -1, 0b0111110: -1, 0b0111111: 8, 0b1000000: -1,
0b1000001: -1, 0b1000010: -1, 0b1000011: -1, 0b1000100: -1, 0b1000101: -1,
0b1000110: -1, 0b1000111: -1, 0b1001000: -1, 0b1001001: -1, 0b1001010: -1,
0b1001011: 3, 0b1001100: -1, 0b1001101: -1, 0b1001110: -1, 0b1001111: 6,
0b1010000: -1, 0b1010001: -1, 0b1010010: 7, 0b1010011: 3, 0b1010100: -1,
0b1010101: 2, 0b1010110: -1, 0b1010111: 0, 0b1011000: -1, 0b1011001: 2,
0b1011010: 3, 0b1011011: 3, 0b1011100: 2, 0b1011101: 2, 0b1011110: -1,
0b1011111: 8, 0b1100000: -1, 0b1100001: -1, 0b1100010: 7, 0b1100011: 5,
0b1100100: -1, 0b1100101: -1, 0b1100110: -1, 0b1100111: 0, 0b1101000: -1,
0b1101001: 5, 0b1101010: 5, 0b1101011: 5, 0b1101100: -1, 0b1101101: 6,
0b1101110: 6, 0b1101111: 6, 0b1110000: 7, 0b1110001: -1, 0b1110010: 7,
0b1110011: 0, 0b1110100: -1, 0b1110101: 0, 0b1110110: 0, 0b1110111: 0,
0b1111000: -1, 0b1111001: 9, 0b1111010: 9, 0b1111011: 9, 0b1111100: -1,
0b1111101: 8, 0b1111110: 8, 0b1111111: 8}
最終的な結果を可視化すると以下のようになる。(ディスプレイに対して小さい数字については、膨張処理の際に個々の数字を分離することが困難であるため、特に検出対象とはしていない。)


加えて、メイン出力であるjsonは以下のようになる。
{
"data": [
{
"digit": -1,
"left": 40,
"top": 67,
"width": 28,
"height": 28
},
{
"digit": 1,
"left": 424,
"top": 51,
"width": 6,
"height": 63
},
{
"digit": 6,
"left": 89,
"top": 29,
"width": 78,
"height": 168
},
{
"digit": 0,
"left": 187,
"top": 26,
"width": 84,
"height": 171
},
{
"digit": 9,
"left": 276,
"top": 24,
"width": 78,
"height": 173
},
{
"digit": 3,
"left": 355,
"top": 125,
"width": 31,
"height": 73
},
{
"digit": -1,
"left": 356,
"top": 207,
"width": 29,
"height": 17
},
{
"digit": 3,
"left": 389,
"top": 127,
"width": 29,
"height": 70
},
{
"digit": 8,
"left": 47,
"top": 224,
"width": 36,
"height": 67
},
{
"digit": 2,
"left": 94,
"top": 225,
"width": 33,
"height": 66
},
{
"digit": 6,
"left": 127,
"top": 225,
"width": 30,
"height": 66
},
{
"digit": -1,
"left": 174,
"top": 226,
"width": 61,
"height": 65
},
{
"digit": 2,
"left": 256,
"top": 225,
"width": 33,
"height": 66
},
{
"digit": 6,
"left": 288,
"top": 225,
"width": 31,
"height": 66
},
{
"digit": 6,
"left": 324,
"top": 258,
"width": 19,
"height": 33
},
{
"digit": 5,
"left": 353,
"top": 224,
"width": 28,
"height": 67
},
{
"digit": 9,
"left": 386,
"top": 225,
"width": 30,
"height": 66
}
]
}
これを用いた後処理により、異常な位置にあったり、大き過ぎる/小さ過ぎる数字を除外することが可能である。
改善点等
- 小さい数字を検出対象としていないのは、数字の大きさによって数字同士の隙間の幅などの性質が異なるため、一括での膨張操作などが難しいからである。 RODに分けられた時点で2つの数字が含まれていることを検知して分割して認識させることができれば、これらについての検出率を改善できる。
- ディスプレイへの物体の映り込みの影響には対処できていない。
- 画素値反転の必要性の自動判定
- 幅広いディスプレイ形状への対応
- 影に対する頑健性向上
3. SSOCRとの比較
SSOCRとは、こちらの記事で検証された、当記事と目的を(ほぼ)同じくするアプリケーションである。そこで、SSOCR検証記事で使われていた2つの画像を今回のアルゴリズムにかけてみよう。
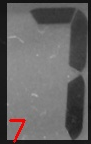
まず、SSOCRでは領域指定と度重なるパラメータチューニングの末にかろうじて読み取れていた"827"であるが、本アルゴリズムでは、"7"については不本意であるものの、パラメータ調整なく全ての数字が読み取れている。

続いて、読み取りには厳密な領域指定とパラメータチューニングを要したこちらの画像も、メインターゲットとしていない小さめの数字についても比較的精度よく認識できている。こうした結果と、パラメータチューニングを要しなかったことを踏まえ、SSOCRよりも高性能であることは確かであろう。
4. Google Cloud Vision APIとの比較
Google Cloud Vision APIは、こちらからデモが利用できるので、一度使ってみて欲しい。「さすがはGoogleの一言」であり、日本語の、広告等やロゴに頻出するような手書きっぽい文字からあらぬ方向を向いた文字まで、かなりの精度で認識してくる。(ただし線が太い文字については精度は落ちる。)僭越ながら、この最強APIとも比較させていただくとしよう。

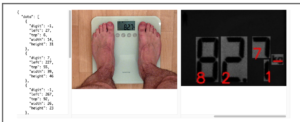
まずはSSOCRとの比較でも用いたこの画像である。下にある比較的小さな数字については読み取れているが、やはり線が太くなると精度は落ちてくるようだ。続いて、Cloud Vision APIに勝る例をいくつかご覧いただこう。(スペースの都合により、本アルゴリズムの結果については背景を除いた最終結果のみを掲載する。)




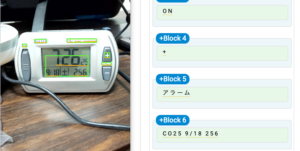

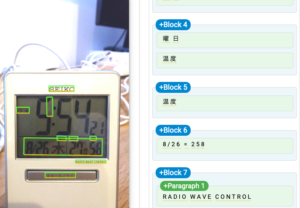

このように、特にシェーディングのある場合やディスプレイに軽度の写り込みのある場合など、本アルゴリズムがCloud Vision APIより高い認識能力を発揮する場面は多く見られる。

コントラストがはっきりしている場合や先に挙げたような精度低下の要因がない場合など、Google Cloud Vision APIが本来の認識能力を発揮する場合も少なくないが、7セグメントディスプレイのOCRに限って言えば、今回実装したアルゴリズムは撮影条件の悪い場合でも比較的精度よく頑健な結果を得られるものとなったと言える。今後も、多様な実践例を通して改善を行なっていく予定である。
CONTACT
お問い合わせ・ご依頼はこちらから