MAGAZINE
ルーターマガジン
生活音を機械学習してみた
音声認識というとどうしてもスピーチをテキストにするというソリューションが多いです。しかし用途がユーザーインターフェースに限られる。IOTのシーンではモノとモノが通信し合ってこそ、人間様が楽できるので、生活音を識別することをゴールとしたいと思います。
▼ 概要
今回は5種類のスズの音のサンプルを使って,2種類ずつどちらのスズか判別を行ってみたいと思います。
▼ 実装環境
- Ubuntu 14.04.1
- Python 2.7.6
▼ 用意するもの
Pythonと機械学習ライブラリのscikit-learnを使います。
(参考: http://www.iandprogram.net/entry/2015/09/15/221518 )
UbuntuにPythonをインストール
$ sudo apt-get install python2.7
pipをインストール
$ sudo apt-get install python-pip
Ubuntuにscikit-learnをインストール
$ sudo pip install scikit-learn
他にnumpyもインストールしておく。
▼ 教師データの作成
5種類のスズの音サンプルを用意します。
| スズの名前 | スズの音のタイプ |
|---|---|
| suzu01 | 一般的なスズ |
| suzu02 | 喫茶店のドアについてる感じ |
| suzu03 | チリーン 風鈴みたいな |
| suzu04 | シャン! クリスマスっぽい |
| suzu05 | 川の流れる音みたいな |
音のサンプルを載せているWebサイトはたくさんありますが、 スズの音階がわからなかったりや同じスズを使っているけど鳴らし方だけ違ったりするサンプルが多く、教師データを作るのがなかなか難しい(正解ラベルが貼れない)。
人間が聞いて明らかに違うスズだとわかるものをサンプルとして使うことが望ましい。
5種類のスズの音サンプルは実際に聞いてみて明らかに違うものを用意する。今回用意したスズはスペクトログラムを書いてみると、その形状の違いから5つの異なるスズを使っていることがわかります。





サンプルだけではパターンが少ないので、機械学習するには十分ではありません。
そこで、スズの音にノイズ音を加えてデータを量産することに。
| ノイズの名前 | ノイズの内容 |
|---|---|
| noise01 | ハイヒールの足音 |
| noise02 | 皮靴の足音 |
| noise03 | ドアが閉まる音 |
| noise04 | ドアノブをガチャガチャする音 |
| noise05 | ドアをノックする音 |
| noise06 | ドアが開く音 |
| noise07 | 道路の環境音 |
| noise08 | 人の笑い声 |
| noise09 | 水洗トイレが流れる音 |
| noise10 | トイレットペーパーを回す音 |
| noise11 | TOTOの音姫 |
5種類のスズの音に11種類のノイズを加えてデータを作成します。
さらに,ノイズの音量を10段階に設定することで更に多くの音声パターンを生成できる(5 × 11 × 10 = 550種類)。
今回はSoX (Sound eXchange) を使って,以下の手順でスズの音とノイズをミックスしていきます。
(参考:http://qiita.com/mountcedar/items/a04ebc4f8c27c226bbff)
ノイズ入りデータ作成手順 1. すべての音声データを一旦.wav形式に変換する 2. 5種類のスズの音を正規化 3. 11種類のノイズの音を正規化 4. 手順1と手順2からできた音声データをスズの音の長さに合わせて合成する。 その際, 新たに合成したノイズ入りのアウトプットファイルをスズの種類ノイズの種類音の段階(0~9).wav として保存する。
例:suzu03のwavファイルとnoise07のwavファイルを合成する。
$ sox -m suzu/suzu03.wav -v 0.2 noise/noise07.wav learning_sample/3_7_9.wav trim 0 suzu03_len
-m : --combine mixの略で2つのファイルを結合するためのオプション。
-v : 後ろの音ファイルの音量を調節をするオプション。(1より大:音量を上げる、1より小:音量を下げる)
trim : 音声を切り取るオプション。例では0秒目からsuzu03の音の長さ(suzu03_len)に合わせてクリッピングしている。




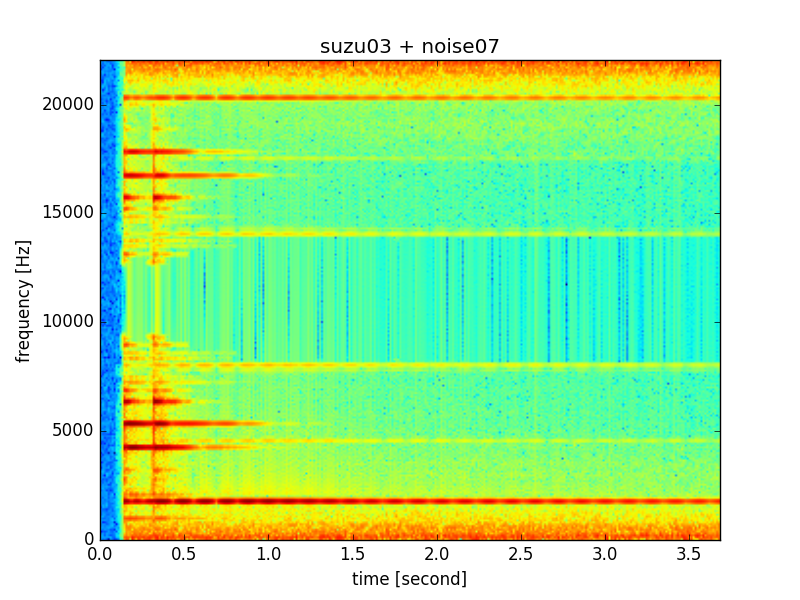
スペクトログラムと波形図をそれぞれ見てみると、元々のsuzu03の画像と比較して、ノイズが入っていることが確認できます。
▼ MFCC (メル周波数ケプストラム係数)
音のデータから特徴量を抽出する方法としてMFCCを使います。
MFCCは人間の聴覚の特性にあわせて低周波部分は細かく,高周波部分は粗く調べる手法らしい(音声解析ではよく使われている)。
音の専門家じゃないので不明な点がありますが、音声データの一部分を取り出して、指定した次元のベクトルに集約して特徴量を抽出してくれます。
サンプル間で音の長さが違う場合でも、同じ長さのベクトルを用意することができるので、そのまま機械学習にかけられる。
MFCCの抽出手順は
- プリエンファシスフィルタで波形の高域成分を強調する
- 窓関数をかけた後にFFT(高速フーリエ変換)して振幅スペクトルを求める
- 振幅スペクトルにメルフィルタバンクをかけて圧縮する
- 上記の圧縮した数値列を信号とみなして離散コサイン変換する
- 得られたケプストラムの低次成分がMFCC
(参考:http://aidiary.hatenablog.com/entry/20120225/1330179868)
#coding:utf-8
import wave
import numpy as np
import scipy.signal
import scipy.fftpack
import scipy.fftpack.realtransforms
def wavread(filename):
wf = wave.open(filename, "r")
fs = wf.getframerate()
x = wf.readframes(wf.getnframes())
x = np.frombuffer(x, dtype="int16") / 32768.0 # (-1, 1)に正規化
wf.close()
return x, float(fs)
def hz2mel(f):
"""Hzをmelに変換"""
return 1127.01048 * np.log(f / 700.0 + 1.0)
def mel2hz(m):
"""melをhzに変換"""
return 700.0 * (np.exp(m / 1127.01048) - 1.0)
def melFilterBank(fs, nfft, numChannels):
"""メルフィルタバンクを作成"""
# ナイキスト周波数(Hz)
fmax = fs / 2
# ナイキスト周波数(mel)
melmax = hz2mel(fmax)
# 周波数インデックスの最大数
nmax = nfft / 2
# 周波数解像度(周波数インデックス1あたりのHz幅)
df = fs / nfft
# メル尺度における各フィルタの中心周波数を求める
dmel = melmax / (numChannels + 1)
melcenters = np.arange(1, numChannels + 1) * dmel
# 各フィルタの中心周波数をHzに変換
fcenters = mel2hz(melcenters)
# 各フィルタの中心周波数を周波数インデックスに変換
indexcenter = np.round(fcenters / df)
# 各フィルタの開始位置のインデックス
indexstart = np.hstack(([0], indexcenter[0:numChannels - 1]))
# 各フィルタの終了位置のインデックス
indexstop = np.hstack((indexcenter[1:numChannels], [nmax]))
filterbank = np.zeros((numChannels, nmax))
for c in np.arange(0, numChannels):
# 三角フィルタの左の直線の傾きから点を求める
increment= 1.0 / (indexcenter[c] - indexstart[c])
for i in np.arange(indexstart[c], indexcenter[c]):
i=int(i)
filterbank[c, i] = (i - indexstart[c]) * increment
# 三角フィルタの右の直線の傾きから点を求める
decrement = 1.0 / (indexstop[c] - indexcenter[c])
for i in np.arange(indexcenter[c], indexstop[c]):
i=int(i)
filterbank[c, i] = 1.0 - ((i - indexcenter[c]) * decrement)
return filterbank, fcenters
def preEmphasis(signal, p):
"""プリエンファシスフィルタ"""
# 係数 (1.0, -p) のFIRフィルタを作成
return scipy.signal.lfilter([1.0, -p], 1, signal)
def mfcc(signal, nfft, fs, nceps):
"""信号のMFCCパラメータを求める
signal: 音声信号
nfft : FFTのサンプル数
nceps : MFCCの次元"""
# プリエンファシスフィルタをかける
p = 0.97 # プリエンファシス係数
signal = preEmphasis(signal, p)
# ハミング窓をかける
hammingWindow = np.hamming(len(signal))
signal = signal * hammingWindow
# 振幅スペクトルを求める
spec = np.abs(np.fft.fft(signal, nfft))[:nfft/2]
fscale = np.fft.fftfreq(nfft, d = 1.0 / fs)[:nfft/2]
# メルフィルタバンクを作成
numChannels = 20 # メルフィルタバンクのチャネル数
df = fs / nfft # 周波数解像度(周波数インデックス1あたりのHz幅)
filterbank, fcenters = melFilterBank(fs, nfft, numChannels)
# 定義通りに書いた場合
# 振幅スペクトルに対してフィルタバンクの各フィルタをかけ、振幅の和の対数をとる
mspec = np.log10(np.dot(spec, filterbank.T))
# 離散コサイン変換
ceps = scipy.fftpack.realtransforms.dct(mspec, type=2, norm="ortho", axis=-1)
# 低次成分からnceps個の係数を返す
return ceps[:nceps]
#wavファイルと次元数を入れてMFCCを抽出
# nfft:FFTのサンプル数 1024, 2048, 4096
# nceps:MFCCの次元数 大体12次元が多い
# ※ fs * cuttime >= nfft/2 を満たす値を与えなければいけない
def get_feature(wavfile,nfft,nceps):
# 音声をロード
wav, fs = wavread(wavfile)
t = np.arange(0.0, len(wav) / fs, 1/fs)
# 音声波形の中心部分を切り出す
center = len(wav) / 2 # 中心のサンプル番号
cuttime = 0.8 # 切り出す長さ [s]
wavdata = wav[int(center - cuttime/2*fs) : int(center + cuttime/2*fs)]
ceps = mfcc(wavdata, nfft, fs, nceps)
return ceps.tolist()
先ほどミックスしたsuzu03とnoise07 (ノイズの音量レベル9) の3_7_9.wavをMFCCにかけてみる。
上記のコードに以下のコードを付け加えて、実際にMFCCを実行する。
if __name__ == "__main__": wavfile="learning_sample/3_11_9.wav" nfft=2048 nceps=12 tmp=get_feature(wavfile,nfft,nceps) print tmp
実行すると、
[-2.1340185367571975, -1.2788164503621682, 0.2980729758980935, -0.7116624981453882, 0.33237397666134955, 0.22739636812287548, 0.7001966634450906, -0.12020691819143244, -0.10969326122265541, -0.45330444421058963, 0.2237907950505698, 0.2439421042510435]
このように、音声のwavファイルから12次のベクトルを生成することができました。
▼ SVMで判別
いよいよ、スズの音を判別してみます。
5種類のスズ (suzu01~05) を以下すべての組み合わせで判別します。
(ただし、すべてノイズ入りです。)
| スズの組み合わせ | スズの音番号のペアNo |
|---|---|
| suzu01, suzu02 | (1, 2) |
| suzu01, suzu03 | (1, 3) |
| suzu01, suzu04 | (1, 4) |
| suzu01, suzu05 | (1, 5) |
| suzu02, suzu03 | (2, 3) |
| suzu02, suzu04 | (2, 4) |
| suzu02, suzu05 | (2, 5) |
| suzu03, suzu04 | (3, 4) |
| suzu03, suzu05 | (3, 5) |
| suzu04, suzu05 | (4, 5) |
全組み合わせにおいて、ノイズ11種類中10種類を学習データに、残り1種類を評価用データに使用するようにして、
学習時にないノイズであっても、スズの音を判別できるかを試しました。
| 学習用データ | 200個 |
| 評価用データ | 20個 |
今回は機械学習ではメジャーなSVM (Support Vector Machine) を使用します。
(参考:http://may46onez.hatenablog.com/entry/2016/02/19/152532)
#coding:utf-8
from sklearn import svm
from sklearn.metrics import classification_report, accuracy_score
import sys
from mfcc import *
import glob
import csv
import random
import itertools
import numpy as np
if __name__ == "__main__":
bell_nums = range(1,6)
pairs = list(itertools.combinations(bell_nums,2))
for pair in pairs:
bell_num1=int(pair[0])
bell_num2=int(pair[1])
train_data = np.empty((0,12),float)
train_label = np.array([])
test_data = np.empty((0,12),float)
test_label = np.array([])
noise_nums = range(1,12)
level_nums = range(0,10)
random.shuffle(noise_nums)
nfft = 2048 # FFTのサンプル数
nceps = 12 # MFCCの次元数
#鈴の音1
for noise_num in noise_nums[0:10]:
random.shuffle(level_nums)
#学習用データを作成
for level_num in level_nums[0:10]:
files_name = glob.glob("learning_sample/%d_%d_%d.wav" % (bell_num1,noise_num,level_num))
for file_name in files_name:
feature = get_feature(file_name,nfft,nceps)
if len(train_data) == 0:
train_data=feature
else:
train_data=np.vstack((train_data,feature))
train_label=np.append(train_label,bell_num1)
#テストデータを作成
file_name = "learning_sample/%d_%d_%d.wav" % (bell_num1,noise_num,level_nums[8])
feature = get_feature(file_name,nfft,nceps)
if len(test_data) == 0:
test_data=feature
else:
test_data=np.vstack((test_data,feature))
test_label=np.append(test_label,bell_num1)
#鈴の音2
for noise_num in noise_nums[0:10]:
random.shuffle(level_nums)
#学習用データを作成
for level_num in level_nums[0:10]:
files_name = glob.glob("learning_sample/%d_%d_%d.wav" % (bell_num2,noise_num,level_num))
for file_name in files_name:
feature = get_feature(file_name,nfft,nceps)
if len(train_data) == 0:
train_data=feature
else:
train_data=np.vstack((train_data,feature))
train_label=np.append(train_label,bell_num2)
#テストデータを作成
file_name = "learning_sample/%d_%d_%d.wav" % (bell_num2,noise_num,level_nums[8])
feature = get_feature(file_name,nfft,nceps)
if len(test_data) == 0:
test_data=feature
else:
test_data=np.vstack((test_data,feature))
test_label=np.append(test_label,bell_num2)
#特徴データをテキストに出力
feature_train_data=np.hstack((train_label.reshape(len(train_label),1),train_data))
feature_test_data=np.hstack((test_label.reshape(len(test_label),1),test_data))
with open("feature_data/train_data.txt","w") as f:
writer=csv.writer(f)
writer.writerows(feature_train_data)
with open("feature_data/test_data.txt","w") as f:
writer=csv.writer(f)
writer.writerows(feature_test_data)
#識別機学習
clf = svm.SVC()
clf.fit(train_data,train_label)
#推定
test_pred = clf.predict(test_data)
#print np.hstack((test_label.reshape(len(test_label),1),(test_pred.reshape(len(test_pred),1))))
#結果算出
score=accuracy_score(test_label, test_pred)
print pair,score
svm.pyの中でmfcc.pyをインポートして特徴量抽出ができるように関数を呼び出しています。
train_dataとtest_dataは1列目にスズの音のラベル、2列目以降にMFCCで抽出した12次元の特徴量ベクトルが入っており、これをSVMの学習器に入れます。
▼ 結果
(1, 2) 1.0 (1, 3) 1.0 (1, 4) 1.0 (1, 5) 1.0 (2, 3) 1.0 (2, 4) 1.0 (2, 5) 1.0 (3, 4) 1.0 (3, 5) 1.0 (4, 5) 1.0
1列目が判定したスズの音番号のペアNoで2列目が正答率になっています。
どのスズの組み合わせも100%の精度で判別することができました。
▼ まとめ
今回,SVM自体のチューニングは特にしていません。
前処理のMFCCによる特徴量抽出の時点でかなり上手く分類できてしまっているのだと思います。
CONTACT
お問い合わせ・ご依頼はこちらから