MAGAZINE
ルーターマガジン
AWS Lambda上のヘッドレスChromeとPuppeteerでサーバーレススクレイピング
こんにちは、ルーターのSakaeです。
IT業界ではその時代時代に流行する単語というものがあり、新たな言葉が日々生まれては、そのうちいくつかが大流行し、そしてまた新しい言葉の登場により、古い言葉が忘れさられていきます。
そんな言葉の中でも「クラウド」という言葉はもはや当たり前の言葉になりました。以前はSaaS、IaaS、PaaSなど細かくカテゴライズした言葉でクラウドを定義していましたが、最近では「〜aaS」と言う言葉を使う人が以前よりは減って来ているかなと感じます。(個人の感想です汗)
そのクラウド関連ワードの中でも、ここ数年で台頭してきた新たな言葉として「サーバーレス」というものがあります。PasS(Platform as a Service)に近いものと考えますが、サーバーレスはFaaS(Function as a Service)と呼ばれることもあるそうで、極端に言ってしまえば、「サーバーは気にしなくて良いから、機能(プログラム、クエリ)などだけ作ってくれ」という考え方です。このサーバーレス界隈で最も有名なAWS LambdaやGoogle Cloud FunctionsはソースコードをNode.jsやPythonなどなどで記述すれば、インフラのことはあまり考えることなくプログラムの実行結果を得ることが可能です。
なんだか細かい単語だらけで何の記事か忘れかけていますが、ルーターもクローリング・スクレイピングを基幹事業とする会社として、このサーバーレスの波にちょっと関わってみたい!というのが今回のメインのお題となります。
ではようやく本題です!
ヘッドレスChromeによるスクレイピングをサーバーレスで実行する
今回の目的は、2年ほど前(Chrome 59 以降)にヘッドレスモードを標準搭載し、今ではヘッドレスブラウザのデファクトスタンダードとなったChromeを、サーバーレス環境で実行してスクレイピングを行いましょうということです。
サーバーレスサービスとして使うのはAWS Lambdaで、Chromeを操作するドライバとしてはPuppeteerを使います。PuppeteerはNode.jsでプログラミングを行い、Chromeブラウザを自動操縦します。
今回のゴールはrooterの公式サイトのニュースページに遷移し、最新のトップニュースのタイトルとURLを取得することとします。いかにも宣伝のようなゴール設定ですね♪
Lambda Layer上にChrome x Puppeteer環境を構築する
Lambda Layerとは2018年末にリリースされたLambda関連新サービスで、Node.jsで作成した機能を、レイヤーと呼ぶ外部ライブラリとして管理することができるものです。
今回のメインの使い所で説明すると、PuppeteerやChromeは今回作成するLambda関数のみで個別に利用するNodeパッケージではなく、今後、別のスクレイピング系Lambda関数を作る際にも当然再利用したいと考えます。そこで、Lambda関数ごとにこれらのパッケージをデプロイするのではなく、Lambda Layerとして外部にデプロイしておき、新しいスクレイピング用のLambda関数を利用する際にはChrome x PuppeteerのLambda Layerを呼び出して再利用しようという考え方です。
そして、さらなるメリットとして、Lambda関数はデプロイしたソースコードのサイズが大きすぎると、Lambda管理コンソール上でインライン編集(ブラウザ上で直接Node.jsプログラミングを行うこと)ができなくなってしまいます。Chrome x PuppeteerのNodeパッケージは非常にサイズが大きくなるので、Lambda関数のソースとこれらパッケージを合わせてデプロイすると、あっという間にサイズ制限を超えてWebブラウザ上でのLambda関数コーディングができなくなります。
この課題に関しても、Lambda Layerとして重たいChrome x Puppeteerのパッケージを外部管理しておけば、Lambda関数としてのデプロイソースの容量が削減されるため、インライン編集ができなくなることを避けられます。
Lambda Layer用 Chrome x PuppeteerのNodeパッケージをローカル環境で準備
まずはローカル開発環境で必要なNode.jsパッケージを準備します。LambdaでNode.jsのパッケージを利用する場合、予めパッケージを開発環境上で導入して、それらのプロジェクト(ディレクトリ)をzip化してLambda Layerにデプロイする必要があります。
はじめに、今回Lambda上で利用するNode.jsバージョンは8.10とします。
$ node --version
v8.10.0Lambda上でヘッドレスのchromeを立ち上げるために「chrome-aws-lambda」というNodeパッケージを利用しますが、こちらのNodeパッケージがNode.jsバージョン8台までしか対応していないためです。Node.js v10.xの対応が待たれますね。
Usage
The nodejs8.10 AWS Lambda runtime is required for this package to work properly. Due to unmet dependencies, the nodejs10.x AWS Lambda runtime is currently not supported.
では、以下の手順でNode.jsでChrome x Puppeteerを動作する環境を構築していきます。ここで注意頂きたいのですが、Node.js用のLmabda Layer仕様により、ディレクトリ名は必ず「nodejs」にする必要があります。
$ mkdir nodejs
$ cd nodejs
$ npm i chrome-aws-lambda puppeteer-core
$ ls -l
total 24
drwxr-xr-x 44 meguroman staff 1.4K 7 30 08:49 node_modules
-rw-r--r-- 1 meguroman staff 12K 7 30 08:49 package-lock.jsonLambda Layer上へのChrome x Puppeteer Node.jsパッケージアップロード
Lambda Layer用パッケージアップロードZipファイルの準備
上記のPJ用環境設定をディレクトリごとzip化します。
$ cd ..
$ zip -r modules.zip nodejs
$ ls -l
total 79808
-rw-r--r-- 1 meguroman staff 40274922 7 30 09:05 modules.zip
drwxr-xr-x 4 meguroman staff 128 7 30 08:49 nodejsこのmodules.zipファイルをLambda Layerに登録します。
ちなみに、Lambda Layerとして登録するzip ファイル内の構造は以下のようになっている必要があります。パッケージ類をzip化してLambda Layer 上で動作させるまでのハマりポイントなので注意です!
.
└── nodejs
├── node_modules
│ ├── chrome-aws-lambda
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── bin
・・・略・・・Lambda LayerへChrome x Puppeteer Node.jsパッケージを追加
では、作成したmodules.zipファイルをLambda Layerに登録していきます。
AWSのマネジメントコンソール上でLambdaの管理画面を開きます。左側のサイドバーにLayersというメニューがありますので、そちらを選んでLambdaレイヤーの登録画面を開いてください。画面上に「レイヤーを作成」ボタンがありますので、ここから新規のLambdaレイヤー登録画面を開きましょう。
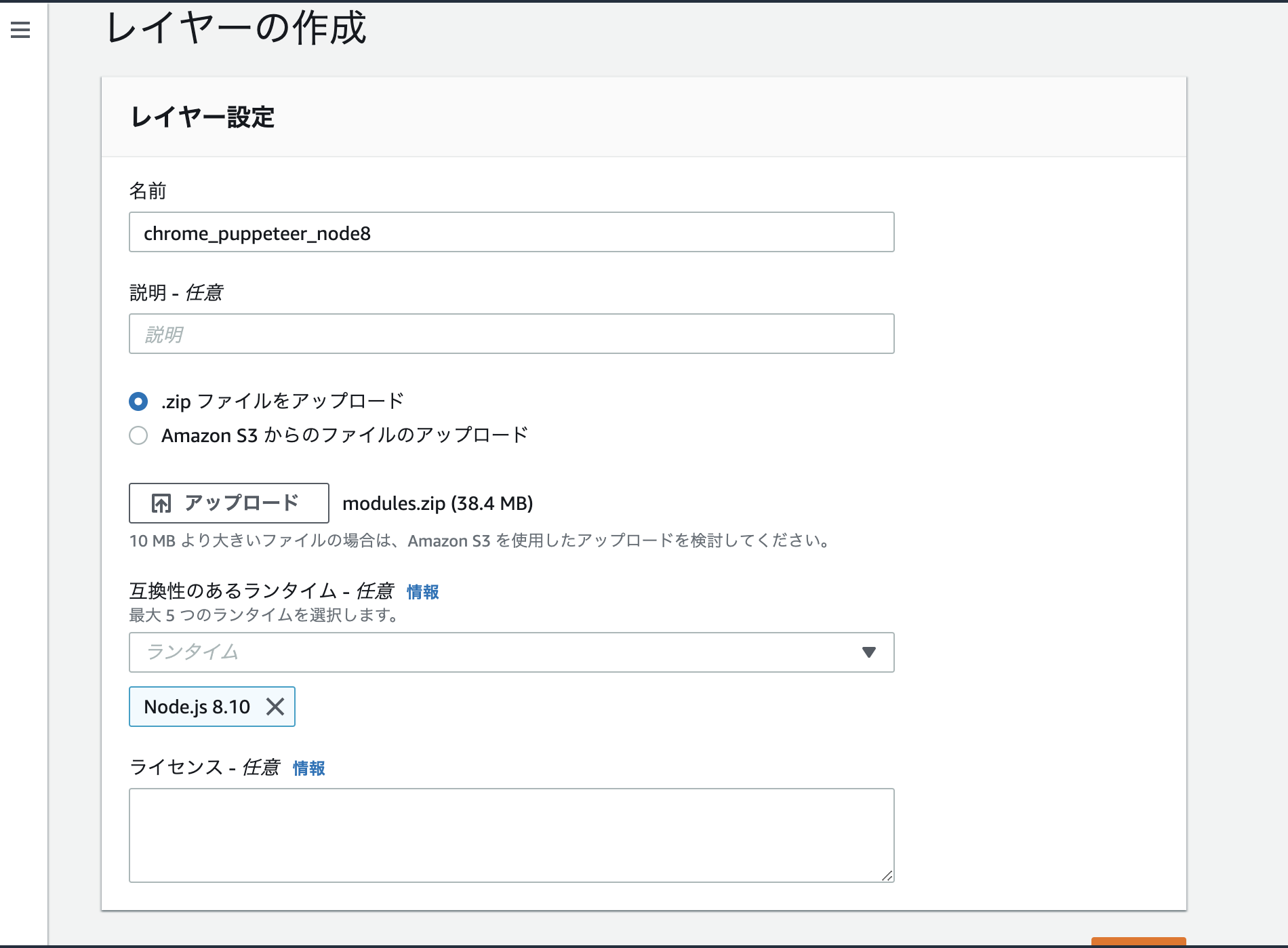
続いて、下図のように「.zipファイルをアップロード」欄で、先程作成したmodules.zipファイルをアップロードしてください。また、「互換性のあるランタイム」欄は上述の通りNode.js 8.10を選択します。あとは「作成」ボタンを押してChrome x Puppeteer Node.jsパッケージをLambda Layerとして登録しましょう。
以上でLambda LayerへのChrome x Puppeteer Node.jsパッケージの追加が完了します。今後はLambda関数を作成する際に、今回作成したレイヤーを外部ライブラリとして利用することができます。
Lambda関数を作成し、「https://rooter.jp」のタイトルを取得するテストを行う
Lambda関数にLambdaレイヤーを付与する
では、さきほど作成したLambda LayerをLambda関数から利用するテストをしてみます。
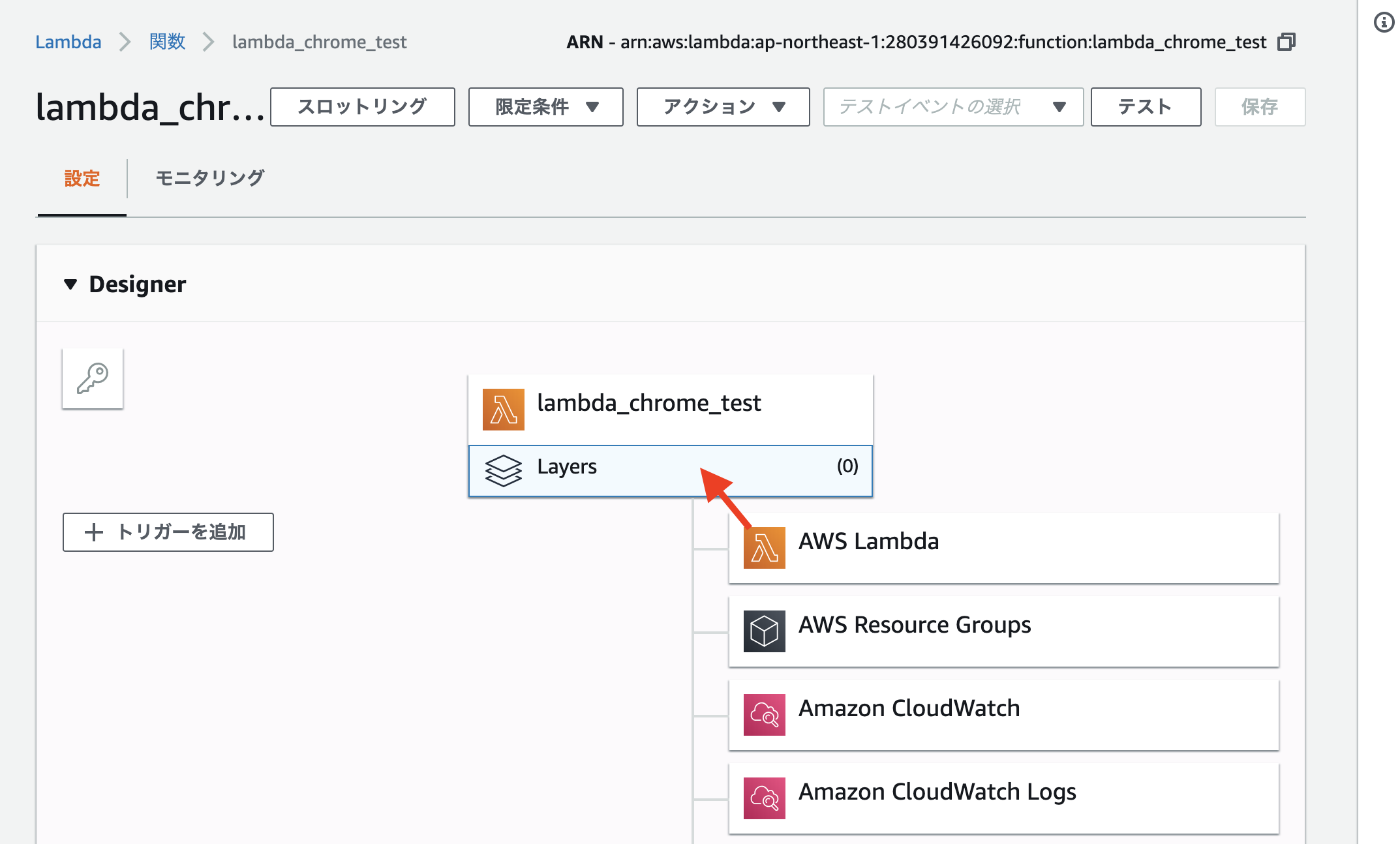
Lambda関数の新規作成画面を開いてください。昔のLambdaには無かったLayersという赤矢印部分のボタンを押してください。
この状態では一見画面上では何の変化も起きていないように見えますが、ブラウザでWeb画面を下にスクロールしていくと、下図のようにLambda上のレイヤー管理のメニューが下部に表示されていますので、赤矢印の「レイヤーの追加」を押しましょう。
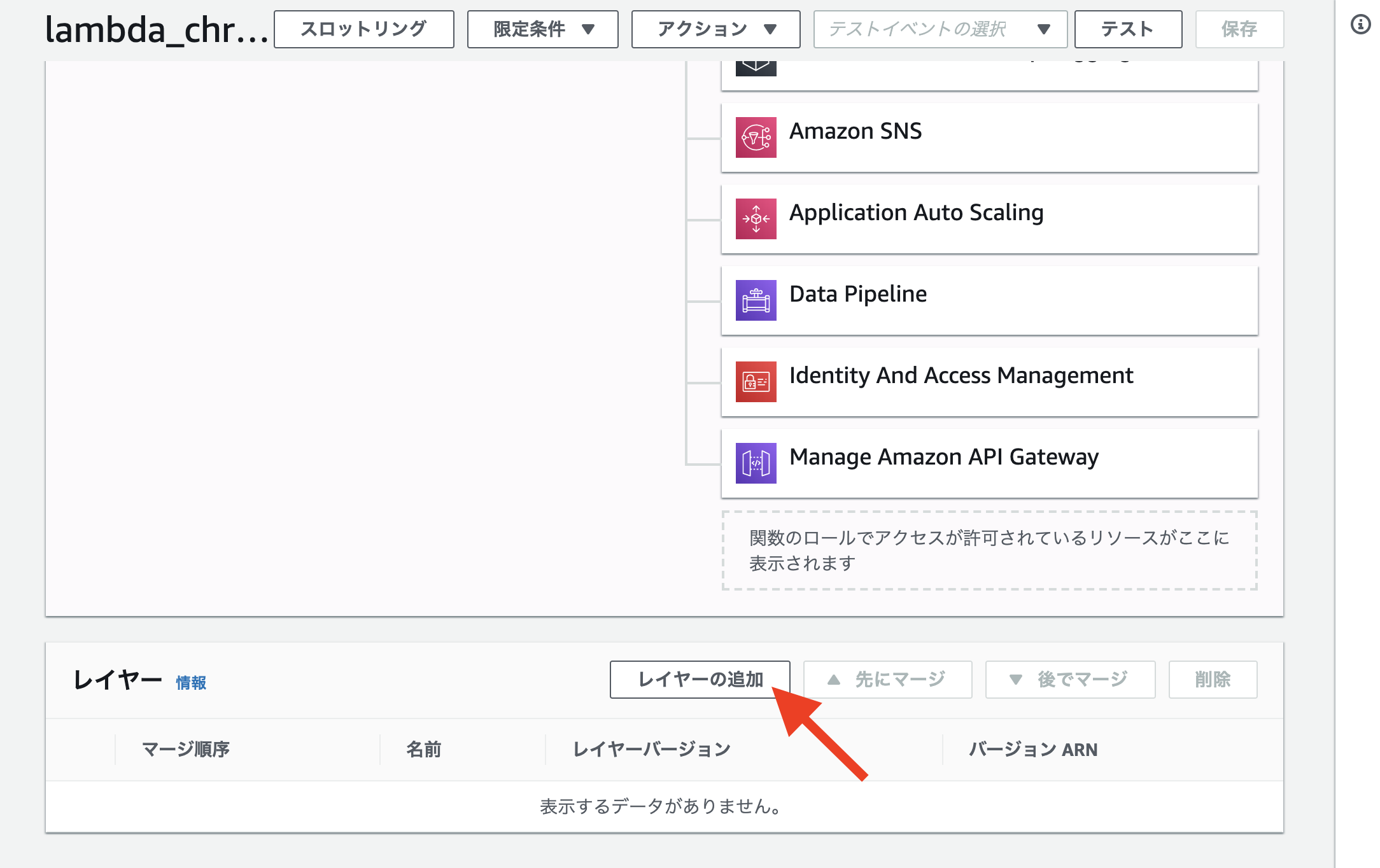
すると「関数にレイヤーを追加」の画面になりますので、ここで先ほどLambda Layerに登録したChrome x Puppeteer Node.jsパッケージのレイヤーを選択します。バージョンはつけた覚えがありませんが、自動採番されているようで、新規登録直後はバージョン「1」、Lambdaレイヤーの同一レイヤーを上書きで更新していくと自動的にバージョン番号が繰り上がっていきます。
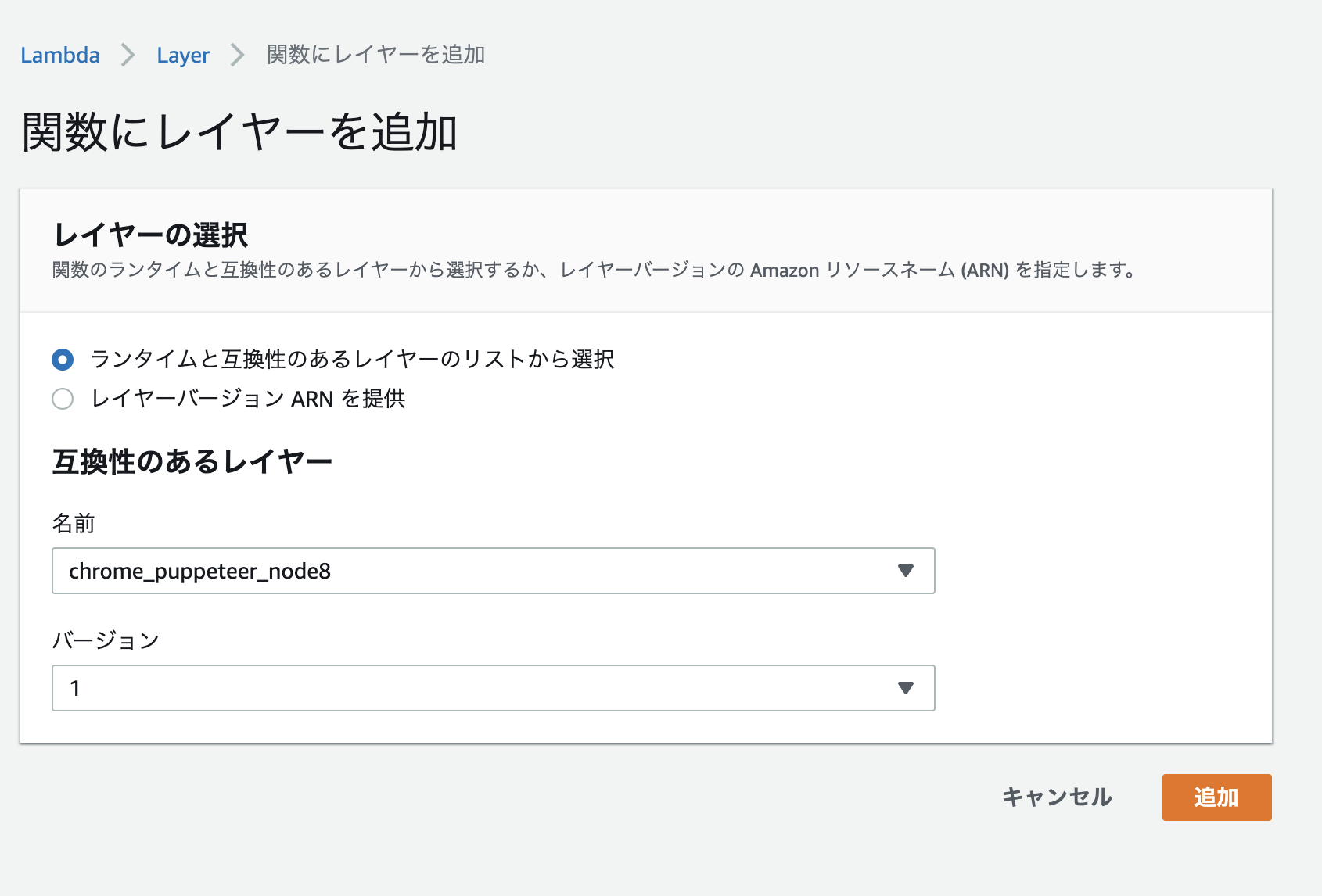
これでLambda関数にレイヤーを付与することができました。この時点で、Lambda関数本体としてはChrome x Puppeteer Node.jsパッケージをLambdaにアップロードしていませんが、chrome-aws-lambda、puppeteer-coreのパッケージをLambda関数のNode.jsソースからrequireで呼び出すことができます。
Lambda関数からChrome x Puppeteerのテスト実行
それでは、実際にLambdaからヘッドレスChromeを起動するテストを行います。
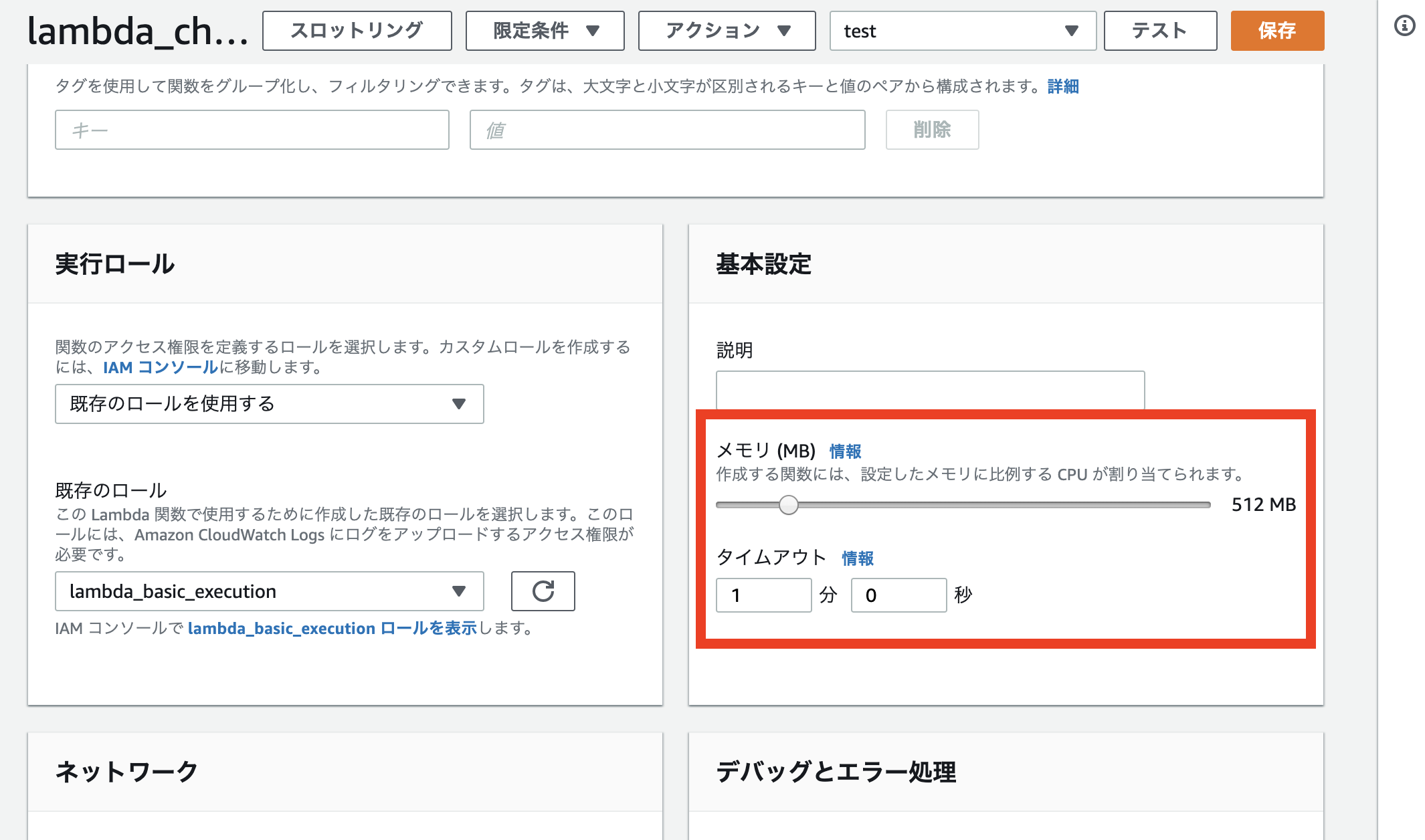
が、その前に一点注意点です。今回のChromeを利用したスクレイピングですが、ヘッドレスとはいえ、Chromeプロセスが立ち上がりますので、それ相応にメモリを必要とします。Lambdaのデフォルト設定の128MBメモリではメモリ不足のエラーが出ますので、下図の通り一旦512MBまでLambda関数が利用可能なメモリサイズを増やしましょう。(512MBは仮です。本当に必要なメモリ量は、ソースコードの完成後に徐々に下げながら見極めていきます。)
また、スクレイピングを行ううえで、Chromeブラウザ上でコンテンツを(ヘッドレスに)レンダリングしていきますので、画面描画、画面遷移などに割と時間がかかります。Lambda関数のタイムアウト時間も下図のとおり1分と長めにしておきましょう。
Lambdaの課金金額はメモリ量と実行時間によって決定されます。そのため、上記の設定によりLambda関数の1呼び出しあたりの単価が若干あがりますので、一応気にはしておいてください。とはいえ、テストで使って頂く分には毎月の無料利用枠を超えることはないと思いますが。。
では、Lambda管理画面上で、index.jsとして以下のテストコードを入力してください。このテストソースでは、ルーターの公式サイト「https://rooter.jp」のタイトルタグを取得してきます。ちなみに以下のソースは、ほぼchrome-aws-lambda公式チュートリアルのテストソースにならっています。
const chromium = require('chrome-aws-lambda');
const puppeteer = require('puppeteer-core');
exports.handler = async (event, context) => {
let result = null;
let browser = null;
try {
browser = await puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless,
});
let page = await browser.newPage();
await page.goto('https://rooter.jp');
result = await page.title();
console.log(result);
} catch (error) {
return context.fail(error);
} finally {
if (browser !== null) {
await browser.close();
}
}
return context.succeed(result);
};ソースコードの登録が終わったら、忘れず画面右上の「保存」ボタンを押しておいてください。
では、早速作成したソースをテスト実行します。下図のLambda関数の「テスト」ボタンを押しましょう。
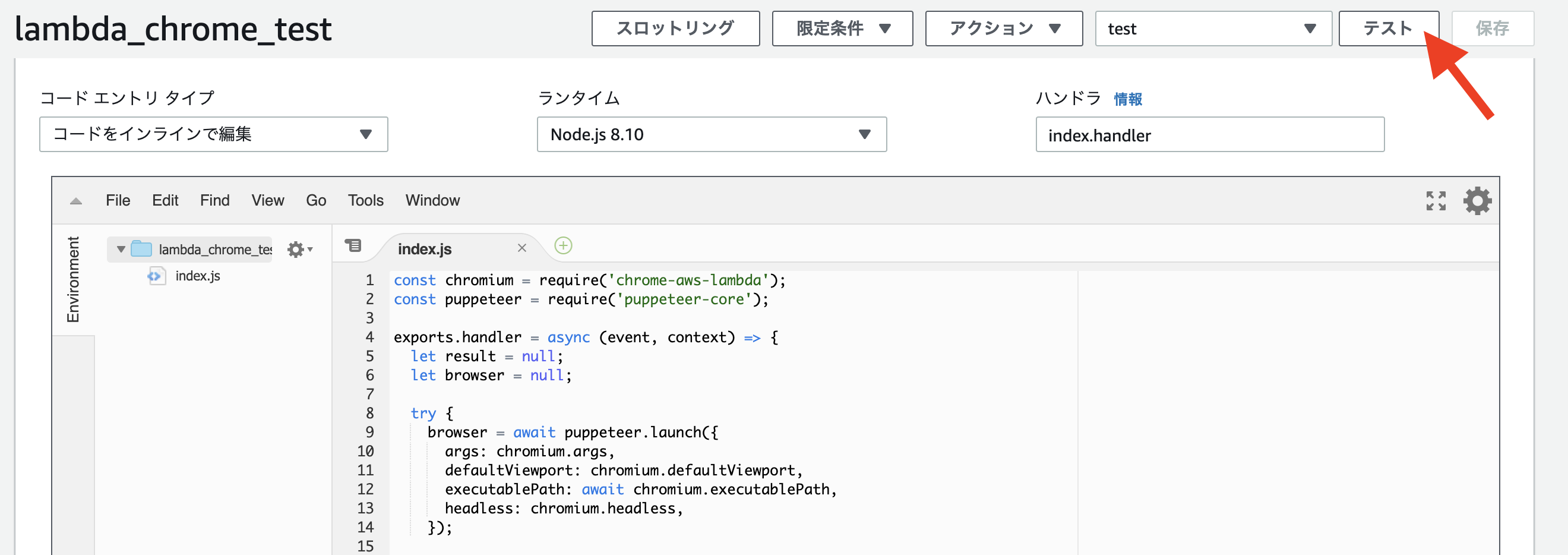
初回のテスト実行時には、テストイベントが一つも登録されていないため、テストイベント作成画面が開きます。今回はLambda関数の入力イベントの内容はChromeスクレイピングには関係しませんので、初期設定で記載されたデフォルトのテストイベントの内容をそのまま登録しましょう。テスト名だけは入力が必要なので仮に「test」と入れておきます。
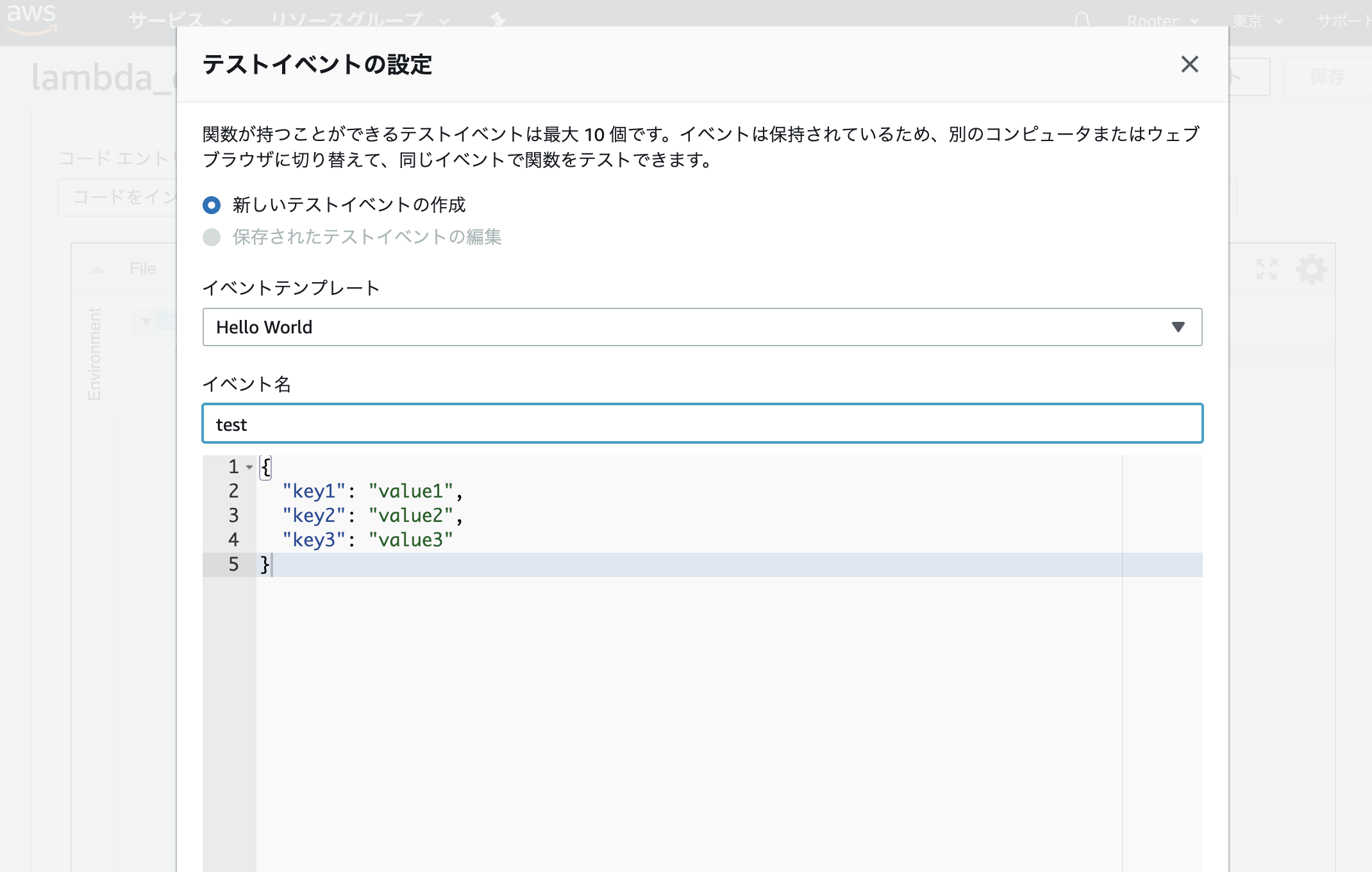
テストイベントが作成されたら、再度画面上部の「テスト」ボタンを押します。
実行に10秒以上かかると思いますが、しばらくするとテストが完了します。下図の通り「実行結果:成功」で緑色背景のテスト結果画面が表示されれば成功です。また、Lambda関数の返り値と、「ログ出力」欄に「株式会社ルーター - データクローリング・スクレイピングによるビッグデータ収集」と記載があれば正常にLambda関数でのChromeによるスクレイピングが成功しています!
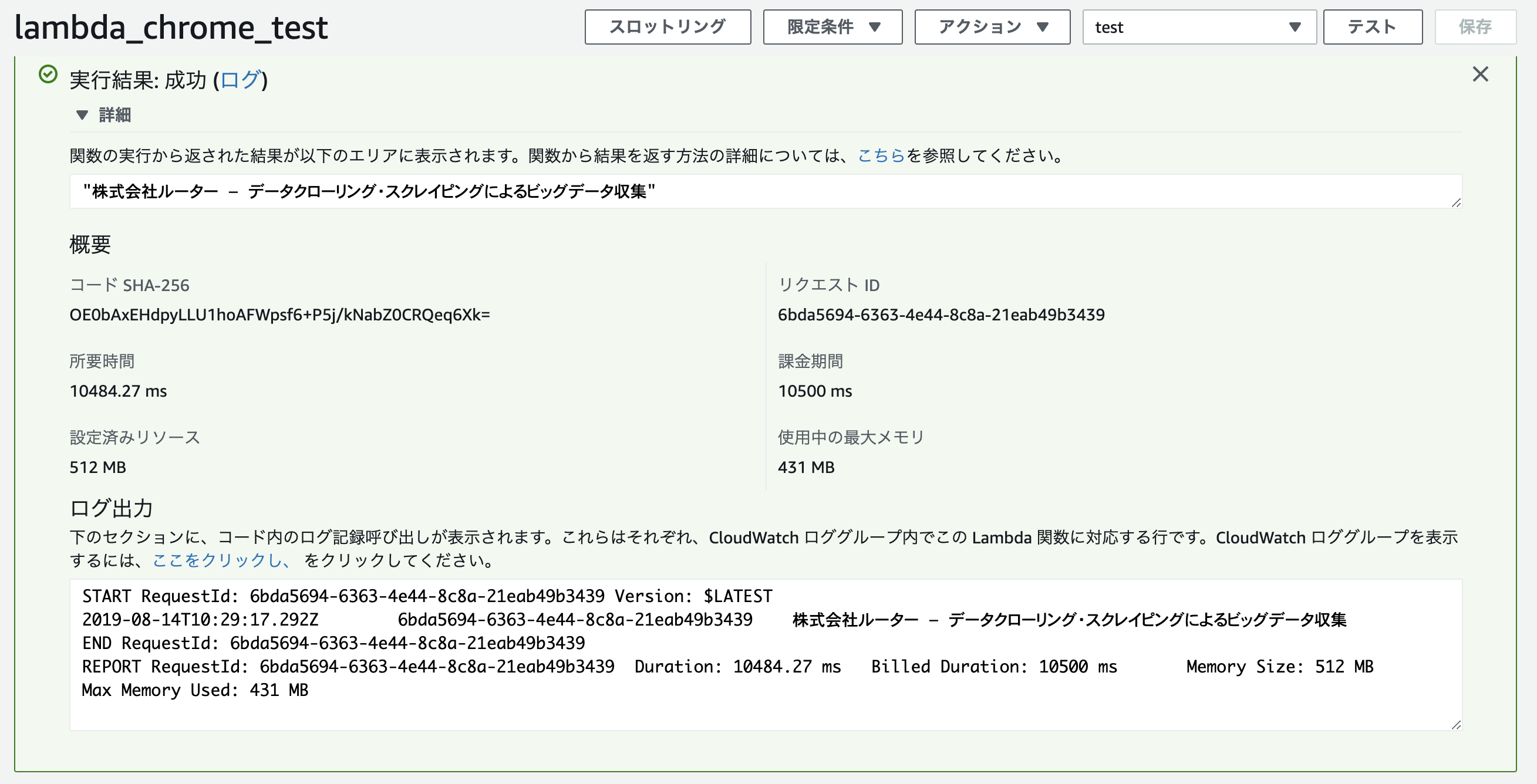
Lambda関数で検索結果画面の
それでは、今回のゴールである、
rooterの公式サイトのニュースページに遷移し、最新のトップニュースのタイトルとURLを取得すること
という操作をLambda上のヘッドレスChromeで実施してみます。
いきなりですが、以下のサンプルソースを実行すると、ルーターのWebサイトから最新のトップニュース情報を取得することができます!
const chromium = require('chrome-aws-lambda');
const puppeteer = require('puppeteer-core');
exports.handler = async (event, context) => {
let topNews = null;
let browser = null;
try {
browser = await puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless,
});
let page = await browser.newPage();
// きちんとUserAgentを指定しましょう
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36')
// ルーター公式サイトトップページに遷移します、レンダリング待ちのためにwaitUntilオプションを入れましょう
await page.goto('https://rooter.jp', {waitUntil: 'networkidle2'});
// 次の遷移先ページ(ニュース一覧ページ)のURLを取得します
let newsPageUrl = await page.evaluate(() => {
return document.querySelector('#menu-item-2142 > a').href
});
// ルーター公式サイトニュース一覧ページに遷移します
await page.goto(newsPageUrl, {waitUntil: 'networkidle2'});
// トップニュース記事のタイトルとURLを取得します。
topNews = await page.evaluate(() => {
let title = document.querySelector('h3.article-title').textContent.trim();
let url = document.querySelector('div.news-list > article > a').href;
return {
title: title,
url: url
}
});
} catch (error) {
// 途中でエラーが発生した場合にそなえ、例外処理(Lambda関数の例外時レスポンス)を記述しておきます
return context.fail(error);
} finally {
// 最後に必ずchromeプロセスをkillします
if (browser !== null) {
await browser.close();
}
}
// 正常系のLambda関数のレスポンスです
return context.succeed(topNews);
};これを実行すると以下のように、トップニュースのタイトルとURLをjson形式で記載した結果が得られます。つまりLambda関数でChromeを使ったスクレイピングに成功したということです!
Response:
{
"title": "対話特化型音声合成エンジン、VOICECLOUDのデモをリリース",
"url": "https://rooter.jp/news/release-voicecloud-demo/"
}
Request ID:
"b7fe4e1c-ccc7-479d-8b51-7899ad1758f4"
Function Logs:
START RequestId: b7fe4e1c-ccc7-479d-8b51-7899ad1758f4 Version: $LATEST
END RequestId: b7fe4e1c-ccc7-479d-8b51-7899ad1758f4
REPORT RequestId: b7fe4e1c-ccc7-479d-8b51-7899ad1758f4 Duration: 13487.95 ms Billed Duration: 13500 ms Memory Size: 512 MB Max Memory Used: 442 MB 細かいソースコードの説明は省略しますが、コツとして、
- gotoでページ遷移する際には、
{waitUntil: 'networkidle2'}を使って画面の描画を待たせる。 - puppeteerの専用メソッドは覚えるのが大変なので、
page.evaluateで見慣れたJavaScriptコードを直接書いてしまう。 Lambdaで実行したpuppeteerの見ているHTMLソースは自分の想像と異なる場合があるので、以下のようにLambdaのHTMLをCloudWatchLogsに出力し、Chromeが見ている実際のHTMLソースを見ながら、ページの遷移が正常に実施できていることや、指定するCSSセレクタが正しいことなどを確認していく。
var html = await page.evaluate(() => { return document.getElementsByTagName('html')[0].outerHTML; });
最後に
プログラムを実行するインフラは一切意識することなく、プログラムの実行結果を得られるとは夢のような時代が来ました。Lambdaをはじめとするサーバーレス(FaaS)は使った文だけお金を払うというクラウド思想の究極系ともいえます。
とはいえ、サーバーレスならではの制限もまだまだ多いですし、常時稼働するようなバッチ処理などの場合は仮想マシン上で動かすほうが安上がりな場合も多いと思います。
とはいえ、総じて今後に注目したいテクノロジーですね。ルーターはスクレイピング・クローリングのリーディングカンパニーとして、いろいろと新しいテクノロジーも取り入れて参ります!ぜひスクレイピング・クローリングでお悩みの際には↓↓の「CONTACT」ボタンよりご相談ください。
CONTACT
お問い合わせ・ご依頼はこちらから