MAGAZINE
ルーターマガジン
YouTubeの限定公開動画広告をBERTで分類する

ルーターの伊崎です。今回は、弊社で実際に行っている、BERTによるYouTubeの広告分類についてお話いたします。
はじめに
弊社では、YouTubeの動画広告のスクレイピングを行っており、そこで得られたデータは弊社の広告データ収集サービス「アドクロール」の一部としてお客様に提供しております。中でも、限定公開動画と呼ばれるカテゴリーの広告はお客様からの需要も高く、弊社でも重要視しております。その中でも特に需要の大きいジャンルとして、以下の4分野があります。
- コスメ
- 健康食品
- 男性コンプレックス
- 女性コンプレックス
これらのジャンルの広告が一定数取得できていることは、弊社のサービスの品質を保つ上で重要であり、したがってこれらの動画広告の取得数については常時モニタリングを行っております。モニターを行う際には、実際に人の目を通して、動画広告がどのジャンルに属するものであるかを判別してから集計を行う必要があり、相応の人的リソースを必要としておりました。こちらの「動画広告のジャンル判別」を機械化できないかという問題は、長らく弊社の課題となっておりました。最近になってようやく、最新の機械学習手法を用いることにより、こちらの課題がほぼ解決に至りました。その全貌をご紹介いたします。
成果
実際の判定結果
まず、実際の動画広告のジャンル判定結果をご紹介いたします。「4分野のいずれかの広告を出したことのある広告主」に1を、そうでない広告主に0を付けております。
| 広告主名 | 人力判定 | 機械判定 |
|---|---|---|
| kirei lab | 1 | 1 |
| ぼくらのファミ通チャンネル | 0 | 0 |
| YOURMYSTAR ユアマイスター | 0 | 0 |
| オゾンペン | 1 | 1 |
| ディズニー公式 | 0 | 0 |
| Uber Eats | 0 | 0 |
| アイエフピー 資産形成相談所 | 0 | 0 |
| 恋肌 | 1 | 1 |
| 【公式】フレイアクリニック | 1 | 1 |
| Good news | 0 | 0 |
| テンピュール | 0 | 0 |
| NEWS TOKIMEKI | 0 | 1 |
| スーパーDEAL- | 1 | 0 |
| JA共済公式チャンネル | 0 | 0 |
| UUUM GOLF-ウーム ゴルフ- | 0 | 0 |
| ほけんの窓口 | 0 | 0 |
| DeNA Channel | 0 | 0 |
| M&E Time Entertainment Co. | 0 | 0 |
| YT Lady | 1 | 1 | 黒ずみ改善ラボ | 1 | 1 |
| メンズビューティ | 1 | 1 |
| 『Rise of Kingdoms―万国覚醒―』公式 | 0 | 0 |
| 味の素AGF株式会社公式チャンネル | 0 | 0 |
| 新型濃密育毛剤BUBKA(ブブカ) | 1 | 1 |
ほぼ完全に人間の結果を再現できています。実際の精度は93.8%でした。以下で述べるように人間が間違っており機械が正しい場合もあるため、実際の精度はこれを上回ります。
判定結果の分析
人力判定と機械判定が異なる部分(太字の部分)を見てみます。NEWS TOKIMEKI様について、人間は該当ジャンルでないと判定し、機械は該当ジャンルであると判定しています。NEWS TOKIMEKI様は、主に金融関連の広告を出稿しておられますが、一部健康食品の広告も出稿していらっしゃいます。したがって、機械が正解です。人間は時間の制約上すべての広告を見るわけにはいかず、見落としが発生しました。一方で、機械であればそのような制限はなく、全広告をみて判定することが可能です。一方、スーパーDEAL-様では、人間は該当ジャンルであると判定し、機械は該当ジャンルでないと判定しています。こちらは人間のほうが正解です。機械が間違えた理由は、スーパーDEAL-様の広告数が少なく、情報として不十分であったためでした。機械学習のモデル自体の不備ではないと言えます。
まとめ
データ不足の場合があるため完全には人間と同等とはいかないものの、人間による分類をかなりの程度補完可能といえます。弊社の実際の運用では、最初に機械が判定をおこない、最後に人間が軽くチェックを行うという形を想定しております。判別が容易な広告についてはあらかじめ機械が判別しておけば、人間は判断が微妙なもののみにリソースを割けばよくなります。現状ではすべての動画を視聴してチェックを行っていることを考えると、大幅な負担削減となります。
手法
ここからは、上で述べた結果を得た手法についてご説明いたします。
データ
機械学習の肝はデータです。弊社には、約2万件のYouTube限定公開動画広告があります。これをもとに、機械学習を行います。以下、データの詳細をご説明いたします。
弊社のYouTubeスクレイプでは、以下のようなデータを収集しております。
- 動画そのもの
- サムネイル
- 動画タイトル等の文章(広告主名を含む)
- 広告のリンクをクリックした際に表示されるLP(ランディングページ)の情報
このうち、今回のジャンル判別で我々が着目したのは、LPの情報です。LPの情報として実際に収集しているのは、LPのタイトル、説明、メタキーワードといった文字情報です。
このようなLPであれば

このようなテキストデータが得られます。こうした文字情報を学習データとして、自然言語処理方面の機械学習で判別が行えるのではないか?それが我々のアイデアでした。動画やサムネイルそのものから画像認識によりジャンル分けする選択肢もありましたが、データ量が膨大になるのに加え、広告の内容をダイレクトに反映しているとは限らない問題があります。テキストデータであれば、より直接的にどのような広告であるかの情報が得られ、学習データとして優秀です。このような形で使用可能な文字データを十分に保持しているというところが、データスクレイピングを本業とする弊社の強みであり、それが今回のプロジェクト成功の鍵となりました。
機械学習
今回はBERTという手法を利用いたしました。BERTの簡単な説明、および今回の実装の詳細については、弊社のアズマインから以下ご説明いたします。
BERT 解説
BERTのどこがすごいの?
2017年にGoogleの研究チームは"Attention is all you need"という論文を発表し、自然言語処理研究の世界に旋風を巻き起こしました。
英語版論文 https://arxiv.org/pdf/1706.03762.pdf
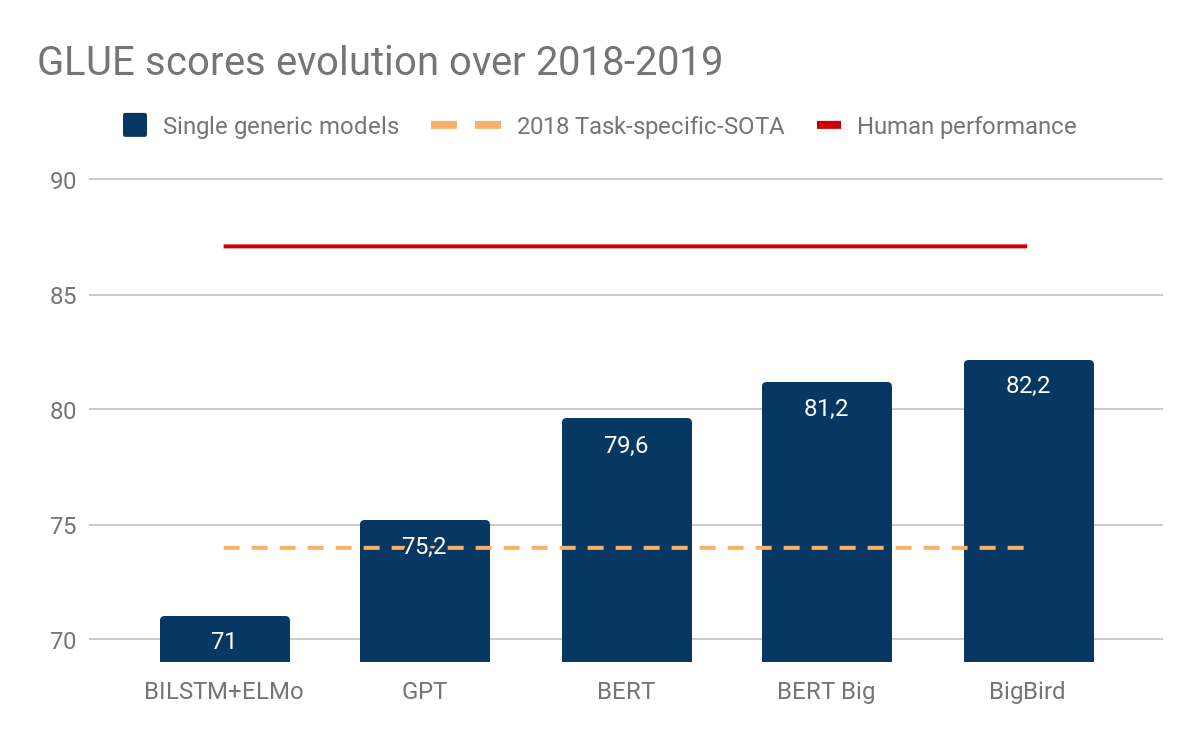 自然言語モデルのパフォーマンスを計測するGLUEベンチマークのスコア表
自然言語モデルのパフォーマンスを計測するGLUEベンチマークのスコア表
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. (2019). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.
その翌年、同じ研究チームがAttentionという仕組みを活用したBERT言語モデルを発表し、LSTMネットワークによる学習が主流だった時代の幕が閉じました。今までコツコツLSTMネットワークを改良して71点しか出せなかったが、BERTが登場した瞬間、最高スコアが一気に80点台まで登ることができました。人間の平均スコアを凌駕する時代はそう遠くありません!
BERTの仕組み
BERTの仕組みを解説する前に、LSTMの説明に入らないといけませんが、今回はその仕組みを深く解説しません。ただ、LSTM学習では複数のLSTMネットワークを時系列に組み立てて、文章などの時系列データをー単語ずつ順番に各ネットワークに与えて、表現ベクトルを計算している。そして、私達は生成された表現ベクトルの集計ベクトルh_tを使って文章分類・翻訳・文章生成する、とだけ理解しとくと良いです。
Xt:単語, A:LSTMネットワーク, ht:表現ベクトル
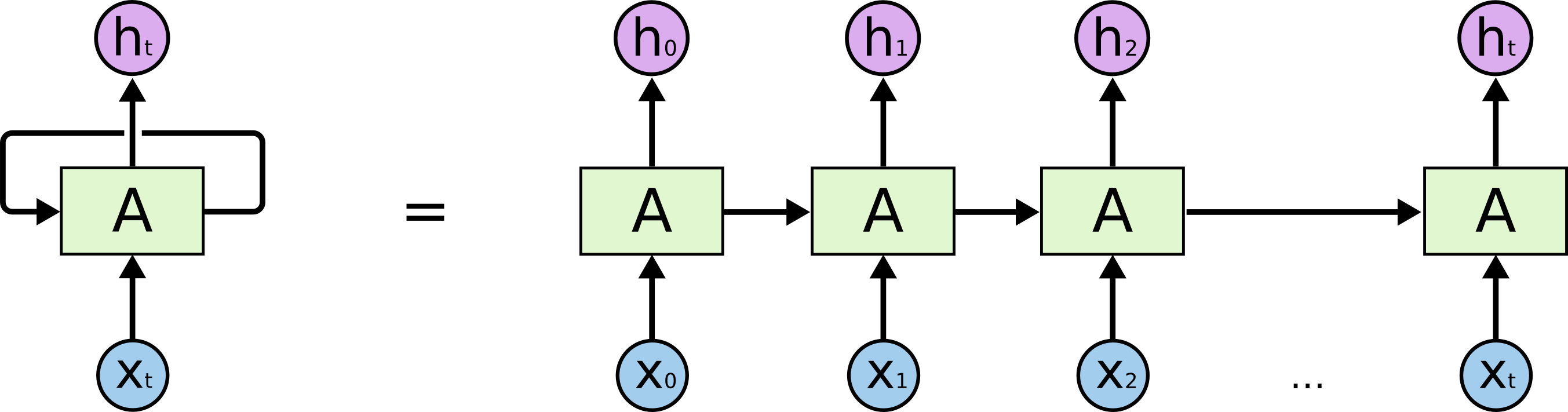 Christopher O. (2015). ‘Understanding LSTM Networks’, colah’s blog, August 27. Available at: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (Accessed: 30 October 2020)
Christopher O. (2015). ‘Understanding LSTM Networks’, colah’s blog, August 27. Available at: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (Accessed: 30 October 2020)
LSTMの問題点:
- 一文字ずつ読み込んで最適な表現ベクトルを計算しているため、GPUを使った並行処理に向いていない。
- 文章の長さ問わず、文章の情報を固定長ベクトルhに保存しないといけない。
- データセットごとのファインチューニングができない。
BERTはこれらの問題を解決するために文章に出ている各単語のAttention(単語同士の紐付き)を計算しているのです。
 Jesse V. (2019). ‘Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention’, towards data science, Jan 8. Available at: https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1 (Accessed: 30 October 2020)
Jesse V. (2019). ‘Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention’, towards data science, Jan 8. Available at: https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1 (Accessed: 30 October 2020)
日本語文章の例をみてみましょう。
明日研究発表があるが、緊張して眠れなかった。
この文章に出ている「緊張」を見ると私たちは「研究発表」があるから緊張していると理解できます。BERTの学習フェーズはこの「緊張」と「研究発表」のAttention値を最大化させるように最適化していて、私たちは学習後の各単語のAttentionベクトルを文章分類・文章生成・翻訳タスクに回すことができます。
BERTによる分類タスク
BERTファインチューニング解説
Googleが発表したBERTモデルには12層のAttentionを計算するTransformer層があります。BERTモデルから出たAttentionベクトルを通常の密ニューラルネットワークに入力して、出力層から出る値のロスを最小化するのがファインチューニング側にいる私たちの目標です。
学習課題の説明
今回は弊社が開発したスクレーピングツールで集計した2020年4月分のユーチューブの限定公開広告動画のタグ付をしたいと思います。行数は2万になります。
弊社のデータベースから広告主名、広告に記載されていた文章(total文章)、そして手動でタグ付した「女男コンプレックス・健康食品・コスメ」に該当するか、しないか情報(is_cosme)を抽出しました。
| 広告主 | total文章 | is_cosme |
|---|---|---|
| ABEMA【アベマ】公式 | 【驚愕の過去】アンミカが"国際スパイ"の元彼に暗殺されかけた過去を告白!結婚詐 | 0 |
| 10分不動産・みわ | 家賃収入 不動産 LINE 家賃収入1000万円講座 家賃収入1000万... | 0 |
| 2K Japan | #2元サッカー日本代表・前園真聖が本気でNBAに挑んでみた- | 0 |
| Add Tube | 若見え美肌革命sirobariメラノアタック集中プログラム sirobariオフィシャルサイトsirobariオフ... | 1 |
| angfaOfficial | スカルプD ボーテ スカルプD scalpd 頭皮 スカルプ アンファー angfa スカルプケア... | 1 |
| 2K Japan | シヴィライゼーション Civ Civilization シヴ6 Civ6 ストラテジーゲーム 戦略ゲーム 歴史 任天堂... | 0 |
| ABEMA【アベマ】公式 | ドッキリ】千鳥ノブの"ブチギレ演技力"に後輩芸人がまさかの大号泣!?全く... | 0 |
| Add Tube | 松本伊代さんも愛用「次世代オールインワン」【公式】ライスビギン | 1 |
| Apple | Apple学生・教職員価格と学生割引-教育-Apple(日本)学習で使う新しいMaciPad | 0 |
| 岩岡誠也 | 岩岡誠也binarisビナリス腸活ダイエットヤセ菌乳酸菌腸内フローラ【公式】binaris(ビナリ... | 1 |
... 2万行
今回の課題は各広告主が出している全ての広告のtotal文章からis_cosmeを予測するモデルの作成です。
データ事前処理偏
事前処理の流れは以下のようになります:
- totals文章を形態素に分割
- BERT入力用データの作成
- BERT辞書idベクトルを生成
- BERT maskベクトルを生成
- BERT input typeベクトルを生成
- 広告主idに以下の情報を紐付けるpython辞書を作成
- 広告主 <-> 同じ広告主が出している各広告のBERT辞書idベクトルのリスト
- 広告主 <-> 同じ広告主が出している各広告のBERT maskベクトルのリスト
- 広告主 <-> 同じ広告主が出している各広告のBERT input typeベクトルリスト
- 広告主 <-> 答え (cosmeなのか(1)・そうじゃないのか(0))
- 広告主名別に教師用・検証用データに分割
- 各教師用広告主idに該当する下の情報をpython辞書から引っ張る
- BERT辞書idベクトルリスト
- BERT maskベクトルのリスト
- BERT input typeベクトルリスト
- 答え
- 検証用データでも5と同じ処理を行う
- 教師用・検証用双方のData Loaderを作成 batch sizeは4
1. 形態素解析
今回は東北大学の乾・鈴木研究所がHugging Faceライブラリーに公開したBERTモデルで学習したいと思います。モデルの詳細は下にページから確認できます。
https://www.nlp.ecei.tohoku.ac.jp/news-release/3284/
例
DB から抽出したデータ
[広告主A,広告主A,広告主A,広告主B,広告主B...] : (20346行)
[文章A,文章B,文章C,文章D,文章E...] : (20346行)
[0,0,0,1,1...] : (20346行)
↓
[ [文章A形態素分割...],
[文章B形態素分割...],
[文章C形態素分割...],
[文章D形態素分割...],
[文章E形態素分割...]
]: (20346,?)
なお,「?」は各total文章の形態素の数
2. BERT入力用データセット作成
BERTの入力層には文章のId,Mask,Input type情報を入力しないといけません。これらを全て該当するBERTモデルの辞書から引っ張る必要があります。
- IdはBert辞書保存されている形態素のid
- Maskは各形態素がスペシャルトークン([CLS]・[PAD]・[EOS]など)なのか、私たちが見る「文字」なのか、を定義している
- Input typeは文章の区切りを表している
形態素に分割されたtotal文章をBert辞書に渡して、エンべディング(Id, Mask, Input Type)情報を取得します。なお、文章の長さにばらつきがあるため、256行の固定長ベクトルを設定し、そのベクトルを形態素のidで埋め、残りは[PAD]というSpecial Tokenを付けます。形態素数が256を超えた場合、はみ出た部分を排除します。また、文章の冒頭に[CLS]というSpecial Tokenを付けてBERTに「これは分類用文章だよ」と伝えます。最後に、文章の後尾に[EOS]というSpecial Tokenを付けて文章の終わりを表します。
例: エンべディングベクトルの長さが10の場合:
明日学校に行くよ!
↓ 形態素に分割
明,日,学校,に,行く,よ,!
↓ スペシャルトークンを付ける
[CLS],明,日,学校,に,行く,よ,!,[EOS],[PAD],[PAD]
↓ id, mask , type ベクトルに変換
id = [2,11475,466,7,3488,54,679,3,0,0]
mask = [1,0,0,0,0,0,1,1,1,1]
type = [1,1,1,1,1,1,1,1,0,0]
処理流れ:
[ [文章A形態素分割...],
[文章B形態素分割...],
[文章C形態素分割...],
[文章D形態素分割...],
[文章E形態素分割...]
]: (20346,?)
↓
id配列 : (20346 , 256)
type配列 : (20346 , 256)
mask配列 : (20346 , 256)
3. 広告主BERT入力層の情報を紐付けるpython辞書を作成
課題は広告ではなく、広告主に対してタグづけをするこtでああるため、一旦、広告主別に教師用・検証用データに分割しないといけません。そのため、一旦広告主に該当する以下の情報を取り出す必要があります。
- 広告主名<->is_cosme
- 広告主名<->広告主に該当する全ての広告のbert辞書idベクトル
- 広告主名<->広告主に該当する全ての広告のmaskベクトル
- 広告主名<->広告主に該当する全ての広告のinput_typeベクトル
処理流れ:
[広告主A,広告主A,広告主A,広告主B,広告主B...] : (20346)
id配列 : (20346 , 256)
type配列 : (20346 , 256)
mask配列 : (20346 , 256)
↓
{ "広告主A" => [id配列] : (3,256),
"広告主B" => [id配列] : (2,256),
...
} : (2666)
{ "広告主A" => [type配列] : (3,256),
"広告主B" => [type配列] : (2,256),
...
} : (2666)
{ "広告主A" => [mask配列] : (3,256),
"広告主B" => [mask配列] : (2,256),
...
} : (2666)
{ "広告主A" => 0,
"広告主B" => 1,
...
} : (2666)
4. 広告主名別に教師用・検証用データに分割
広告主ごとに教師データ・評価データに分けます。比率は8:2です。
広告主の数: 2666
教師用: 2132
評価用: 534
5. 教師用広告主の各広告のbert層入力情報を3の辞書から引っ張る
学習するときは広告文章単位でやるので、各広告の答えは該当する広告主のis_cosme値になるように設定します。
IN
print(X_train_id.shape)
print(X_train_mask.shape)
print(X_train_type.shape)
print(y_train.shape)
print(y_train.type())
#広告主配列上位10個
print(advertiser_test[:10])
OUT
torch.Size([13007, 256])
torch.Size([13007, 256])
torch.Size([13007, 256])
torch.Size([13007, 1])
torch.FloatTensor
['公式YouTubeチャンネルロジャー堀',
'Rapha Films',
'mau movie',
'購入促進チャンネル',
'Candy Crush Official',
'M&M,Ltd.',
'お値打ち',
'Shopify Japan',
'GMOとくとくBBチャンネル',
'ちょちょ']
6. 検証用データセットでも同じ処理を行う
IN
print(X_test_id.shape)
print(X_test_attention.shape)
print(X_test_type.shape)
print(y_test.shape)
OUT
torch.Size([7338, 256])
torch.Size([7338, 256])
torch.Size([7338, 256])
torch.Size([7338, 1])
7. 教師用・検証用双方のData Loaderを作成
学習データを一気にGPUにロードさせると7.8TBのGPUメモリーが必要になりますので、現実的ではありません。そのため、4広告づつGPUに振り付けるpytorchのDataLoaderを作成する必要があります。バッチ数4の場合、教師用データのsizeは以下のようになります:
教師用: 3252バッチ x 4(バッチ数) x 256列のidベクトル、maskベクトル, typeベクトル
検証用: 1835バッチ x 4(バッチ数) x 256列のidベクトル、maskベクトル, typeベクトル
学習モデル定義
東北大学が出している分類用BERTモデルの形式が以下のようになります。
IN
model.to(device)
OUT
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(32000, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
他11枚のBert Layer
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
pooler層を使って12層のBert Layerの出力を集計したのち、1層の密ニューラルネットワーク層(classifier)で分類するような設計になっています。また、classifier層とBert層(encoder)の間に0.1の確率でノードの道を「閉じらせる」 dropout層も入れることによってか過剰適合を防ぐことができます。
学習環境
| 項目 | 備考 |
|---|---|
| GPU | Nvidia GTX 1050 Ti |
| GPUメモリー | 4GB |
| Cudaコア数 | 768 |
| Cuda Version | 10.2 |
| Pytorch Ver. | 1.6.0 |
学習用パラメター
| epoch数 | learning rate | 1 epoch学習時間 | Optimizer | 総学習時間 | lr decay |
|---|---|---|---|---|---|
| 5 | 0.00002 | 26.5分 | AdamW | 2時間12分 | なし |
学習中のロス
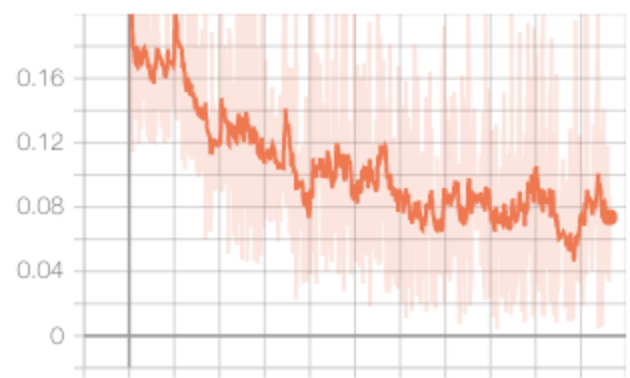
学習結果
学習後、検証用広告主に該当する広告のtotal文章を使って予測を行い、各広告の予測の確率の平均値を計算してからp値ごとの予測を計算するように設定しました。ここで言うp値は学習モデルの自分の予測に対する「信頼度」と考えればいいと思います。
処理流れ
検証用広告主のリスト
↓
事前処理作業で作成した広告主に対してid,mask,typeベクトルを紐付けたpython辞書を使ってid , mask , typeベクトルを取得
↓
id , mask , typeベクトルをmodelに入力して予測を出す(logits)
↓
modelから出力された各広告のlogitsをSigmoidで通して確率を得る
↓
各広告の予測の確率の平均を計算
↓
各広告の予測の確率の平均がp以上の場合cosme=1、p以下の場合cosme=0と設定
↓
集計
学習結果
p値ごとの正確度(accuracy)、再現率(recall)、精度(precision)と広告主に対する予測を集計した結果になります。
| p値=0.1 | p値=0.2 | p値=0.3 | p値=0.4 | p値=0.5 | p値=0.6 | p値=0.7 | p値=0.8 | p値=0.9 | 実際 | 広告主 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.9118198874 | 0.91369606 | 0.9305816135 | 0.9380863039 | 0.9343339587 | 0.9343339587 | 0.9268292683 | 0.9287054409 | 0.9287054409 | Accuracy | |
| 0.9634146341 | 0.9573170732 | 0.9512195122 | 0.9451219512 | 0.9024390244 | 0.8963414634 | 0.8658536585 | 0.8597560976 | 0.8475609756 | Recall | |
| 0.7939698492 | 0.8010204082 | 0.8432432432 | 0.8659217877 | 0.8862275449 | 0.8909090909 | 0.893081761 | 0.9038461538 | 0.9144736842 | Precision | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Rapha Films |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | mau movie |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 購入促進チャンネル |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Candy Crush Official |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | M&M,Ltd. |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | お値打ち |
...
p値=0.4に設定したときの再現率と精度が一番バランスが良いので今回はp値=0.4の予測モデルを採用することになります。
まとめ
短時間の学習でも95%前後の再現率・精度・正確度を得られました! これは日頃クローリングして集計した弊社の高品質なランディングページデータと最新鋭の自然言語処理モデルを使ったからこそ得られたスコアになります。弊社では日々スクレイピングにより高品質なデータ収集を行っております。今後、それをもとにしたデータ分析・機械学習方面にも力を入れてまいります。今後ともご贔屓のほどよろしくお願いいたします。
CONTACT
お問い合わせ・ご依頼はこちらから