MAGAZINE
ルーターマガジン
7セグメントディスプレイの文字認識をするSSOCRを徹底検証

こんにちは、学生アルバイトのkyonoです。
夏も本格的になってきて、迸る汗と青春の季節となりました。 青春といえば、忘れもしない中学時代。 その時私は班活動での発表の直前であり、班に一人いた女子ともう一人の男子が険悪な雰囲気になっていました。 皆黙り込み、遅々として進まぬ話し合い。偶に口を開いたと思えば刺々しい言葉。 耐えきれなくなった私は、ボソッと「カルシウム不足」と呟きました。 すると眉間に皺を寄せていた女子は頓に真顔になり、その醸し出す空気がさっと冷たくなりました。 そして手に持っていたノートを机に叩きつけたのです。 嫌な汗が迸ります。南無三、と思ってももう手遅れです。 結局もう二度と口を利いてもらえませんでした。 嫌な青春でした。
OCR (光学文字認識)とは、さまざまな画像データから文字を抽出し、コンピュータで扱える形式の文字データに変換することです。 扱う対象としては活字、手書き文字などがありますが、ここでは7セグメントディスプレイの数字を扱ってみようと思います。 そのくらいだったらニューラルネットワークを使うというのもちょっと大仰すぎるというもの。 7セグの数字を認識するのに軽くて良いアプリケーションがあるそうです。
それがSSOCRです。 今回はSSOCRで遊んでみた結果、否、苦しんでみた結果について記録してみようと思います。
SSOCRのインストール
通常のインストール
私はMacでSSOCRを使うことにしたので、Imlib2をHomebrewでインストールする必要がありました。
$ brew install imlib2$ make
$ make install
でインストールできます。
Dockerを用いたインストール
Dockerfileが公開されていました。 こちらのブログを執筆なさった方が制作されたようです。 Imlib2を直接入れて環境を汚したくない……という方はこちらを使いましょう。
$ docker-compose build
ところが、私の環境でこれを実行すると、以下の所で止まってしまいました。
=> [2/6] RUN apt-get update -qq && apt-get install -y git libx11-dev libimlib2-dev 65.5s => => # enting => => # the time zones in which they are located. => => # 1. Africa 4. Australia 7. Atlantic 10. Pacific 13. Etc => => # 2. America 5. Arctic 8. Europe 11. SystemV => => # 3. Antarctica 6. Asia 9. Indian 12. US => => # Geographic area:
こちらのブログによれば、DockerfileにENV DEBIAN_FRONTEND=noninteractiveという記述を追加すれば良いとのこと。
その上で再実行してみました。
=> ERROR [3/6] RUN git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr 2.6s ------ > [3/6] RUN git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr: #7 0.657 Cloning into 'ssocr'... #7 2.543 /bin/sh: 1: make: not found ------ executor failed running [/bin/sh -c git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr]: exit code: 127 ERROR: Service 'ssocr' failed to build : Build failed
おっと、makeコマンドが存在しない。
Dockerfileのapt-get installのところでmakeもインストールするようにしましょう。
さあ今度こそ。
=> ERROR [4/7] RUN git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr 1.8s ------ > [4/7] RUN git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr: #7 0.307 Cloning into 'ssocr'... #7 1.155 cc -D_FORTIFY_SOURCE=2 -Wall -W -Wextra -pedantic -Werror -pedantic-errors -fstack-protector-all -O3 -c -o ssocr.o ssocr.c #7 1.422 In file included from /usr/include/string.h:495, #7 1.422 from ssocr.c:29: #7 1.422 In function 'strncat', #7 1.422 inlined from 'tmp_imgfile' at ssocr.c:79:12, #7 1.422 inlined from 'main' at ssocr.c:529:15: #7 1.422 /usr/include/x86_64-linux-gnu/bits/string_fortified.h:136:10: error: '__builtin_strncat' specified bound depends on the length of the source argument [-Werror=stringop-overflow=] #7 1.422 136 | return __builtin___strncat_chk (__dest, __src, __len, __bos (__dest)); #7 1.422 | ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #7 1.422 ssocr.c: In function 'main': #7 1.422 ssocr.c:67:19: note: length computed here #7 1.422 67 | pattern_len = strlen(dir) + strlen(DIR_SEP TMP_FILE_PATTERN) + 1; #7 1.422 | ^~~~~~~~~~~ #7 1.803 cc1: all warnings being treated as errors #7 1.809 make: *** [: ssocr.o] Error 1 ------ executor failed running [/bin/sh -c git clone https://github.com/auerswal/ssocr.git && cd ssocr && make && mv ./ssocr /usr/local/bin/ssocr]: exit code: 2 ERROR: Service 'ssocr' failed to build : Build failed
なぜだ。
GitHubのSSOCRにあるINSTALLには、以下のようなことが書いてありました。
Another problem can be the introduction of new compiler warnings. Some of those are prone to false positives, and this problem does occur for stable GCC releases as well. Because ssocr's CFLAGS include both options -Werror and -pedantic-errors, false positives will break compilation of ssocr. To work around this problem, you can remove both of these options from the CFLAGS definition in the Makefile: -Werror -pedantic-errors
という訳でこれを除外するようにDockerfileを変更してみます。最終的には以下のようになりました。
FROM ubuntu
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update -qq &&\
apt-get install -y git make libx11-dev libimlib2-dev
RUN git clone https://github.com/auerswal/ssocr.git &&\
cd ssocr &&\
make CFLAGS="-D_FORTIFY_SOURCE=2 -Wall -W -Wextra -pedantic -fstack-protector-all $(shell imlib2-config --cflags) -O3" &&\
mv ./ssocr /usr/local/bin/ssocr
RUN mkdir /app
WORKDIR /app
COPY . /app
無事インストールできました。
ちゃんと動くのかどうかテストしてみましょう。
$ docker-compose run ssocr Creating network "seven_segment_recognition_ssocr_docker_default" with the default driver Creating seven_segment_recognition_ssocr_docker_ssocr_run ... done root@b8d1d83dc716:/app# ssocr -d-1 ./images/test_22.jpg -D./images/temp.png -t 30 22
きちんと判定してくれています。
ある程度判然とした7セグメントの数字を認識する
使用する画像はこちらになります。以降この画像のファイル名は./images/4850859370_d9c38e9364_k.jpgとして扱われます。
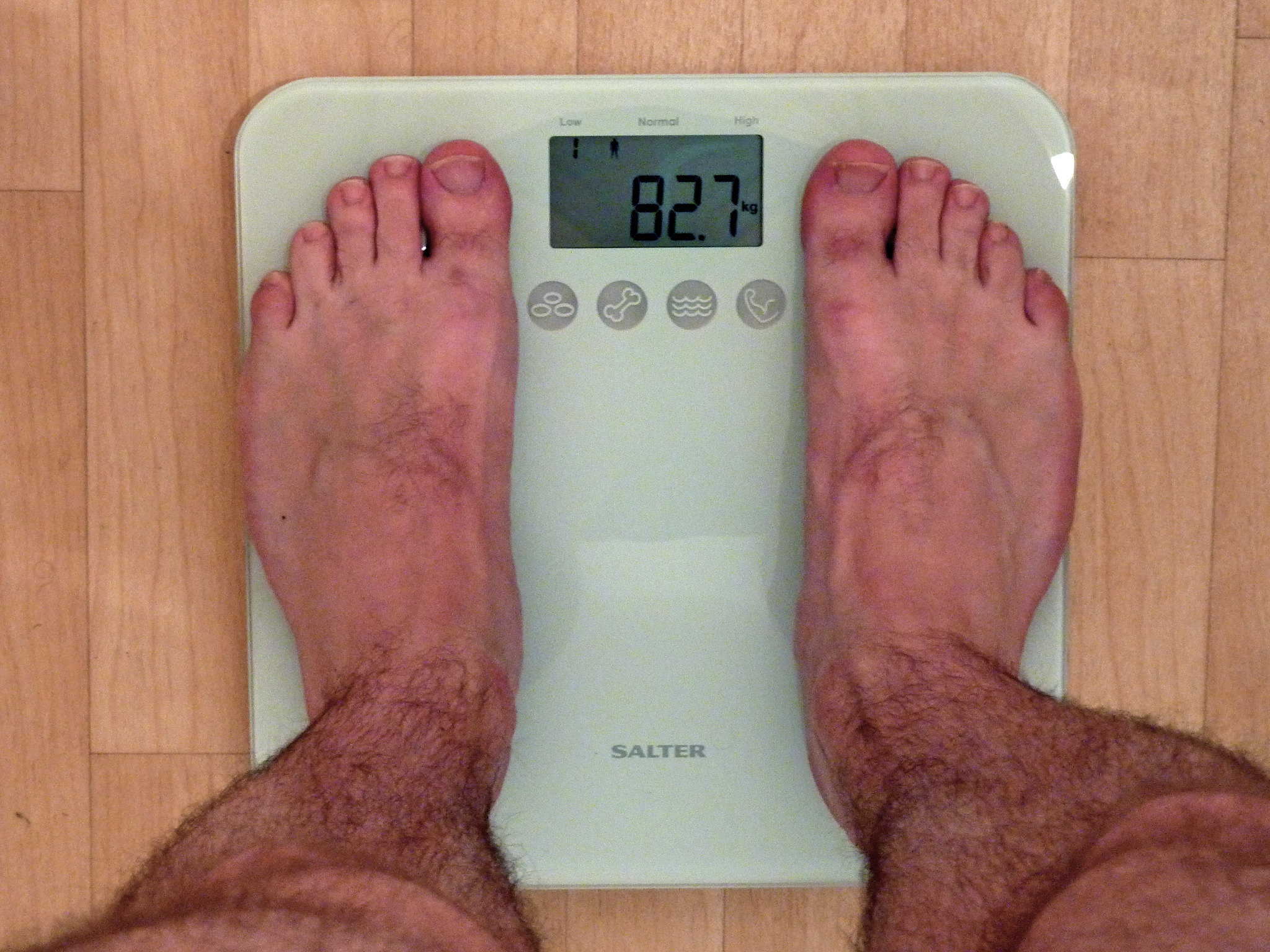 photo by Magnus D
photo by Magnus D
取り敢えず使ってみる
体重計の数字を抜き出してみるために、色々とパラメタをチューニングして実験してみます。
数字部分の座標はcrop 1000 200 200 200として、特殊なことは何も指定しないで実験してみます。
$ ssocr -D./temps/temp.jpg -d -1 -T crop 1000 200 200 200 ./images/4850859370_d9c38e9364_k.jpg
-Dではデバッグ用画像の出力先、-dでは検出する数字の桁数(-1なら自動判定)を指定します。 SSOCRでは判定時に画像を白黒で二値化しますが、-Tオプションではその閾値を自動判定してくれます。
結果は以下のようになりました。
8
また、デバッグ画像は以下のようになっていました。
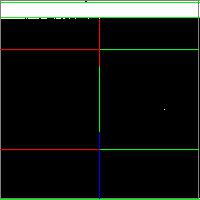
真っ黒ですね。カルシウム不足かな?
-tオプションで閾値を指定する
-Tオプションは使い物にならないので、-tで閾値を指定してあげましょう。これは画像の輝度をパーセンテージにして、その中での閾値を指定することになります。 画像の最も暗いところが0、最も明るいところが100です。
-aオプションを使えば、0~100の幅が画像固有にならず、真っ黒が0、真っ白が100として扱われます。
ここでは-at 20を指定してみましょう。
$ ssocr -D./temps/temp.jpg -d -1 -at 20 crop 1000 200 200 200 ./images/4850859370_d9c38e9364_k.jpg結果は以下のようになりました。
__1
また、デバッグ画像は以下のようになっていました。

人間の目ではもう十分数字が読めるのですが、プログラムにはそうもいかないようです。判定がノイズに吸われてしまっています。
erosionでノイズを軽減する
ここでノイズの軽減をしてみましょう。erosion(膨張)という処理を加えてみます。 この処理を行うと、白いピクセルと隣り合った黒いピクセルは、すべて白になります。 逆を行うdilation(収縮)もあります。

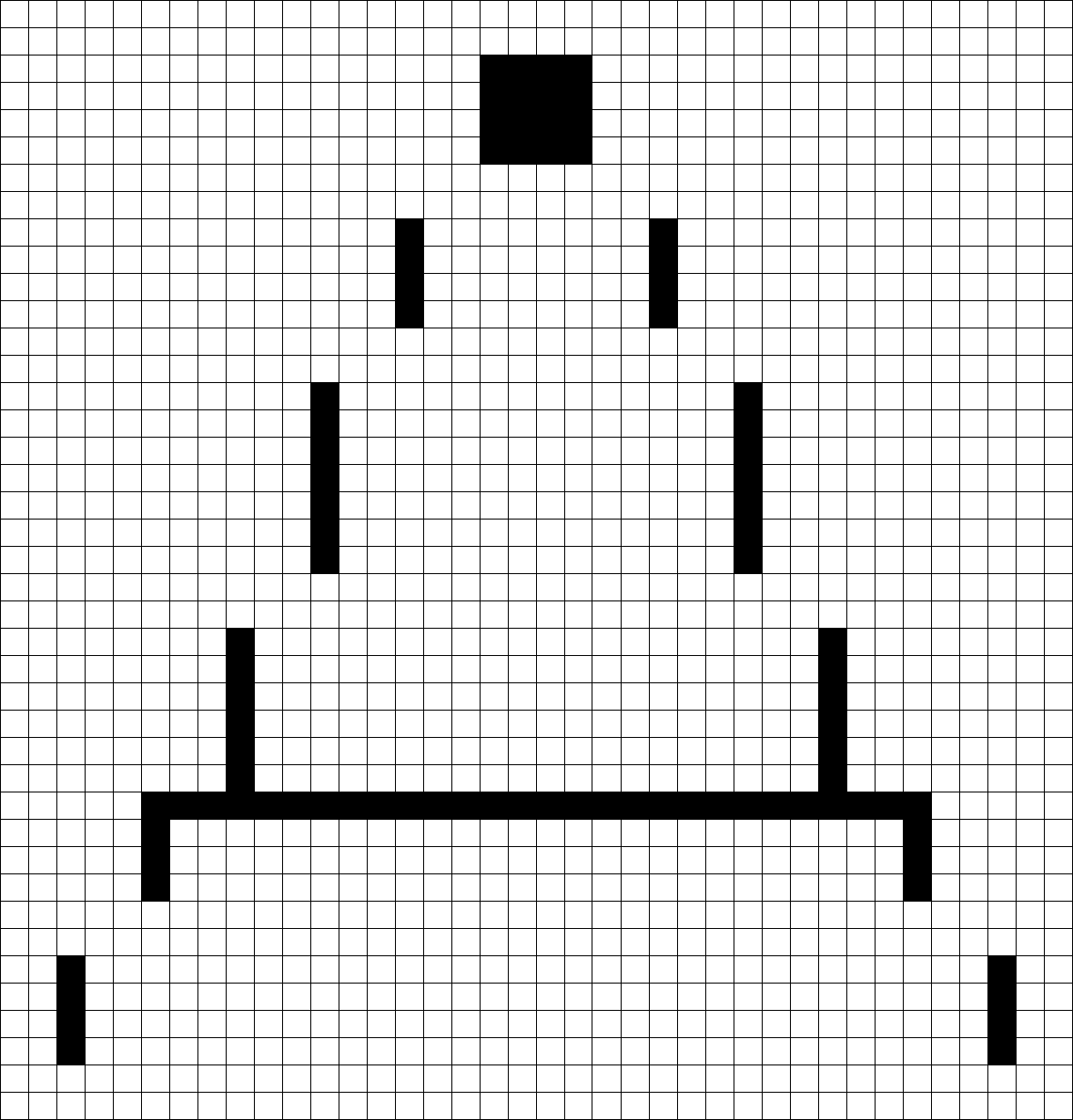
これを2回ほど行ってみましょう。
$ ssocr -D./temps/temp.jpg -d -1 -at 20 crop 1000 200 200 200 erosion 2 ./images/4850859370_d9c38e9364_k.jpg結果は以下のようになりました。
827
また、デバッグ画像は以下のようになっていました。
ノイズが綺麗に消えており、数字を抜き出すことはできました。本来小数点も検出されるはずなのですが、今回は上手くいかなかったようです。
因みにN回erosionをした後にN回dilationをする操作は、上記のコマンドでerosionの代わりにopeningを用いることで行えます。 試してみたところ、小数点は上の画像よりも判然と表示されましたが、やはり出力は827のままでした。
陰影の激しい7セグメントの数字を認識する
次は下のようなごちゃごちゃとしたデジタル時計の表示をうまく抜き出せるのか実験してみましょう。
ファイル名は./images/6_30.jpgとします。
数字が色々な場所にあり、陰影も激しいです。
これができたら御喝采。

全体に対してopening
取り敢えず全体に対して、openingを用いて処理してみます。
$ ssocr -D./temps/temp.jpg -d -1 -at 10 opening 3 ./images/6_30.jpg結果は以下のようになりました。
..1_
また、デバッグ画像は以下のようになっていました。
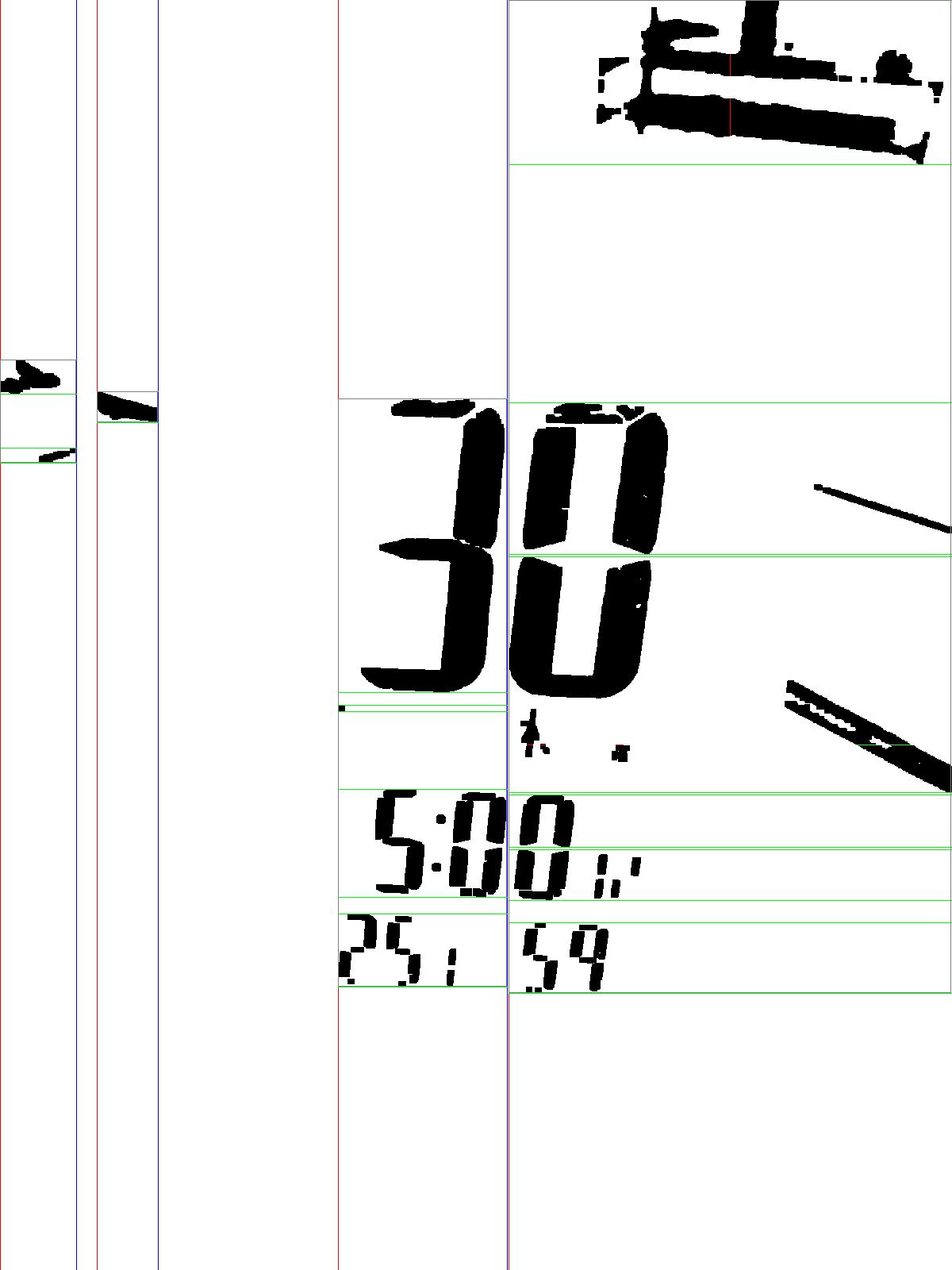
期待する動きをしてくれません。
数字だけ抜き出してほしいけど……
小数点やアンダーバーが変なところに表示されるのが気持ち悪いので、純粋に0から9のみを取得するよう、-c digitsを指定してみましょう。
$ ssocr -D./temps/temp.jpg -c digits -d -1 -at 10 opening 3 ./images/6_30.jpg結果は以下のようになりました。
__1_
数字以外を検出ロジックから外したのではなく、全部検出しておいて後から数字以外を_で潰したように見えます。期待するのは数字に寄せて解釈する動きでした。
こちらとしては数字以外を存在すら検出してほしくないので、-dオプションを使って桁数を制限してみましょう。
この画像からは1桁の数字が検出されているので、-d 1を指定してみます。
$ ssocr -D./temps/temp.jpg -c digits -d 1 -at 10 opening 3 ./images/6_30.jpg結果、found too many digits (2)というメッセージが返ってきました。
「2つ数字を見つけたから仕事しないよ」とのこと。
その後2、3と引数を増やしていくと、found too many digits (3)、found too many digits (4)と言われ、-d 4で漸く先程の__1_が得られました。
-dや-cを弄ると指定したものだけを上手く検出するようにロジックを変更してくれるのかと思いきや、何も指定しないのと全く同じロジックで検出した後に、数字以外をアンダーバーに置き換えてみたり、桁数が指定されたものと合わなかったらエラーを返したりするだけのように見えます。これならOCR後のフィルタでもできてしまうのであまりOCR自体の機能に期待するものではないです。
取り敢えず今後は-c digitsだけ指定して、sedコマンドでアンダーバーを消してしまいましょう。
背景が入らないようにして数字を検出する
背景が入らないようにcropして、大きな"30"という数字だけ検出してみます。
$ ssocr -D./temps/temp.jpg -c digits -d -1 -at 10 crop 300 300 700 700 opening 5 ./images/6_30.jpg | sed -e "s/_//g"30また、デバッグ画像は以下のようになっていました。
 正解です。
次は大きな数字だけではなく、デジタル時計全体から数字を抜き出してみようと思います。
正解です。
次は大きな数字だけではなく、デジタル時計全体から数字を抜き出してみようと思います。
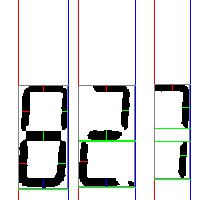
$ ssocr -D./temps/temp.jpg -cdigits -d -1 -at 10 crop 350 300 600 1000 opening 3 ./images/6_30.jpg | sed -e "s/_//g"11また、デバッグ画像は以下のようになっていました。
 デバッグ画像に引かれた線のうち、赤い縦棒は数字の左端、青い縦棒は数字の右端を表していて、灰色の長方形が検出した数字を囲んでいます。
つまりこれは大きな3と下側の数字群で1つの数字、大きな0と下側の数字群で1つの数字と看做されています。
結果、このデジタル時計のように数字が複雑に配置されている場合、それらを纏めて判定することはできず、数字ごとにcropで座標を指定して判定する必要があることがわかります。
デバッグ画像に引かれた線のうち、赤い縦棒は数字の左端、青い縦棒は数字の右端を表していて、灰色の長方形が検出した数字を囲んでいます。
つまりこれは大きな3と下側の数字群で1つの数字、大きな0と下側の数字群で1つの数字と看做されています。
結果、このデジタル時計のように数字が複雑に配置されている場合、それらを纏めて判定することはできず、数字ごとにcropで座標を指定して判定する必要があることがわかります。
時刻部分だけ検出する
時刻部分5:00 32を抜き出してみようと思います。$ ssocr -D./temps/temp.jpg -c digits -d -1 -at 15 crop 450 950 370 200 ./images/6_30.jpg | sed -e "s/_//g"結果は以下のようになりました。
8
また、デバッグ画像は以下のようになっていました。

ノイズに引っ張られて滅茶苦茶な結果になっています。
回転を加えたり、cropの範囲を更に絞ったりと細かなチューニングを繰り返し、やっとまともな結果が得られるようになりました。
$ ssocr -D./temps/temp.jpg -c digits -d -1 -at 15 crop 455 980 360 160 rotate 357 erosion 1 ./images/6_30.jpg | sed -e "s/_//g"結果は以下のようになりました。
510032
また、デバッグ画像は以下のようになっていました。

SSOCRで":"を判定させる方法はないため、出力が1になっています。それ以外は良い結果です。
でもここまで厳密なcropをしないと駄目なのでしょうか。もう少しだけ範囲を拡げて判定してみましょう。y座標の範囲を少し拡大します。
$ ssocr -D./temps/temp.jpg -c digits -d -1 -at 15 crop 455 950 360 200 rotate 357 erosion 1 ./images/6_30.jpg | sed -e "s/_//g"結果は以下のようになりました。
また、デバッグ画像は以下のようになっていました。
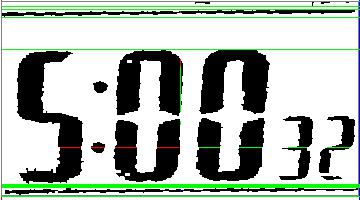
少し範囲を広げただけででも数字が検出されなくなってしまいました。
結局SSOCRはどうなのか
SSOCRは数字の座標が完全に特定できれば、判定が非常に速いので使い心地は良いです。 但し非常にノイズに弱いです。 数字を囲う枠が二値化した時に残ってしまえば、もうまともに判定できません。 今回のブログでは省略しましたが、小さな縦棒があれば直ぐに1と判定してしまいます。 erosionやopeningはノイズの除去に非常に有効な手法ですが、ノイズの大きさと数字の大きさがあまり変わらなかった場合、数字ごと消えてしまうためノイズが不定な環境では厳しいです。
汎用性のある設定はSSOCRには存在しない/使えないので、数字の座標、明るさ、白黒の閾値、適切な前処理、これらを判定対象毎に決め打ちする必要があります。明るさなどが一定のセブンセグメントディスプレイの環境であれば、同じ前処理が機能するかも知れません。それさえできれば、速くて快適です。 色々な7セグメントの数字を大量に並べて一つの設定で一遍に判定、といったことはできないので注意しましょう。
CONTACT
お問い合わせ・ご依頼はこちらから