MAGAZINE
ルーターマガジン
jupyter notebookで野球データをビジュアライズ part 1

jupyter notebookで野球データをビジュアライズ part 1
クライマックスシリーズ突入!!
こんにちは!
ルーターエンジニアのohkabeです。
今回はクライマックスシリーズ突入という事で、野球のデータをjupyter notebookでビジュアライズします。
なんでも、野球の世界では統計学やデータ分析が盛んで、セイバーメトリクスと呼ばれる分析手法が、戦略や選手の獲得に大きく関わっているそうです。
日本シリーズに向けて、これからどんどん盛り上がっていく野球シーンをネタに、jupyter notebookはこんなことができるぞ!というのを紹介します。
下準備
初めに以下のモジュールを使用します。
matplotlibで日本語フォントを使用するために、otf変換したメイリオフォントをインストールしています。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style="ticks")
import matplotlib as mpl
font = {"family":"meiryo"}
mpl.rc('font', **font)
なお、今回使用するデータはプロ野球データFreakさんのものを使用しました。
pandasのread_htmlメソッドにより、Webページ内の表をデータフレームとして読み込むことができます。
url = 'https://baseball-data.com/team/hitter.html'
datasets = pd.io.html.read_html(url)
datasets[0]
| 順位 | チーム | 試合 | 勝利 | 敗北 | ... | NOI | IsoD | IsoP | 得点平均 | 安打平均 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 順位 | チーム | 試合 | 勝利 | 敗北 | ... | NOI | IsoD | IsoP | 得点平均 | 安打平均 |
| 1 | 1 | 広島 | 143 | 82 | 59 | ... | .493 | .086 | .169 | 5.04 | 8.92 |
| 2 | 2 | ヤクルト | 143 | 75 | 66 | ... | .481 | .081 | .136 | 4.60 | 9.00 |
| 3 | 3 | 巨人 | 143 | 67 | 71 | ... | .460 | .068 | .146 | 4.37 | 8.78 |
| 4 | 4 | DeNA | 143 | 67 | 74 | ... | .446 | .057 | .165 | 4.00 | 8.45 |
| 5 | 5 | 中日 | 143 | 63 | 78 | ... | .451 | .059 | .115 | 4.18 | 9.01 |
| 6 | 6 | 阪神 | 143 | 62 | 79 | ... | .450 | .077 | .109 | 4.03 | 8.54 |
以下では、必要に応じて加工したcsvを使用するものとします。
個人成績の散布図を作る
使用するデータは、2018年度セリーグの選手の打撃成績一覧です 。
batter_2018 = pd.read_csv("data_sets/batter_2018.csv")batter_2018.head()
| チーム | 打率 | 打席数 | 安打 | 本塁打 | 打点 | 四球 | 死球 | 三振 | 犠打 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 中日 | 0.274 | 645 | 161 | 7 | 57 | 47 | 4 | 80 | 1 |
| 1 | 中日 | 0.235 | 632 | 136 | 4 | 44 | 19 | 6 | 111 | 26 |
| 2 | 広島 | 0.262 | 675 | 150 | 10 | 60 | 75 | 17 | 118 | 6 |
| 3 | 広島 | 0.233 | 642 | 130 | 13 | 60 | 51 | 3 | 111 | 30 |
| 4 | DeNA | 0.318 | 590 | 175 | 28 | 71 | 38 | 1 | 45 | 0 |
jointplotで2変数の関係を見る
seabornのjointplot関数で散布図を作ります。
x軸,y軸を、打率と本塁打として、その関係を見て見ましょう。
イメージでは、パワー系の選手は、テクニックが低くなりそうなので打率と本塁打は反比例すると予想します。
ax = sns.jointplot(batter_2018["打率"], batter_2018["本塁打"], batter_2018)
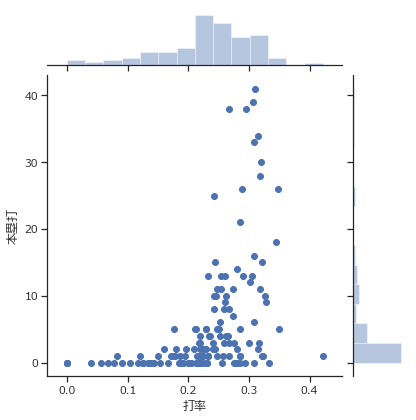
意外にも打率が3割付近の巧打の打者でなければ、ホームランを量産できないという結果が出ました。
聞いた話では、パワーでホームランを打つタイプの打者は最近では少ないそうです。
次は打率と犠打の関係を見ます。
自分の予想では、打率はそこそこですが守備が上手い、いぶし銀の選手がバントを得意としているイメージです。
ax = sns.jointplot(batter_2018["打率"], batter_2018["犠打"], batter_2018)
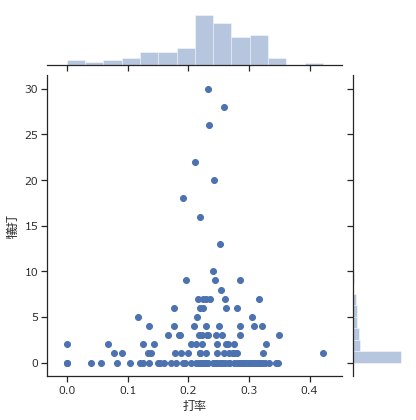
こちらはイメージ通りです。
swarmplot/violinplot
seabornでよく使うのはswarmplotとviolinplotで、swarmplotは散布図、violinplotは確率密度を出してくれます。
データフレームをチーム別に分解して描画して見ます。
plt.figure(figsize=(15, 8))ax = sns.violinplot(x=batter_2018["チーム"], y =batter_2018["打率"], inner=None, color="0.95", linewidth=0.3)ax = sns.swarmplot(x=batter_2018["チーム"], y =batter_2018["打率"])
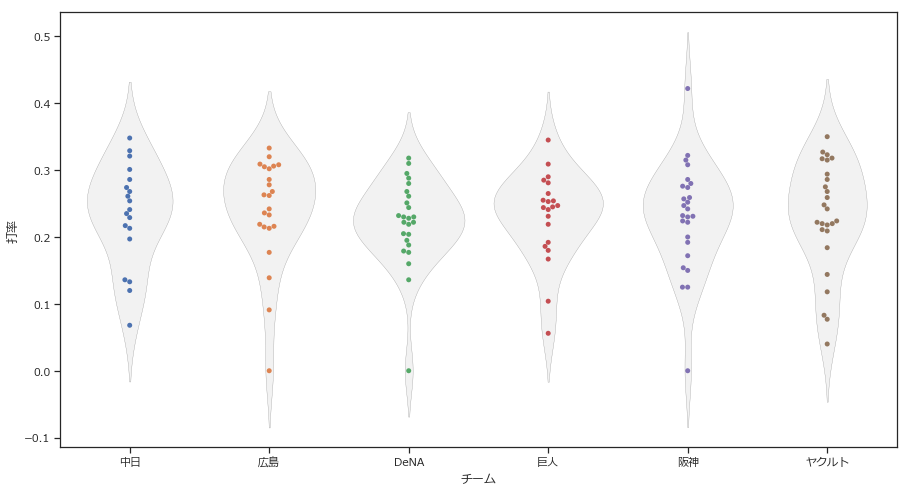
横に並べることでチーム別の比較がしやすくなりました。
微差ではありますが、
- 広島の打者は全体的に打率が高く、選手層が厚い
- DeNAは分布の厚みが下の方にあるため、打撃が苦手
などの傾向が見えてきます。
チーム打撃のグラフ化
数値の標準化
では次にチーム全体の打撃成績を見て見ましょう。
使用するのは過去5年間の各チームの打率などを集めたデータです。
team_batting = pd.read_csv("data_sets/team_batting.csv")team_batting.head(6)
| 年度 | チーム | 打率 | 得点 | 本塁打 | 盗塁 | 犠打 | |
|---|---|---|---|---|---|---|---|
| 0 | 2018 | ヤクルト | 0.266 | 658 | 135 | 68 | 109 |
| 1 | 2018 | 中日 | 0.265 | 596 | 97 | 60 | 86 |
| 2 | 2018 | 広島 | 0.262 | 721 | 175 | 95 | 109 |
| 3 | 2018 | 巨人 | 0.257 | 625 | 152 | 61 | 96 |
| 4 | 2018 | 阪神 | 0.253 | 574 | 85 | 75 | 108 |
| 5 | 2018 | DeNA | 0.250 | 572 | 181 | 71 | 71 |
うーん、よく分かりません。
個人では打率3割が目安ですが、チーム打率が2割6分と言われてもピンときません。
ましてや、盗塁や犠打については全く分からない。
よって、ここはデータを標準化します。
def normalize(df):df_norm = (df - df.mean()) / df.std()return df_norm
team_batting[["打率","得点","本塁打","盗塁","犠打"]] = normalize(team_batting[["打率","得点","本塁打","盗塁","犠打"]])team_batting.head(6)
| 年度 | チーム | 打率 | 得点 | 本塁打 | 盗塁 | 犠打 | |
|---|---|---|---|---|---|---|---|
| 0 | 2018 | ヤクルト | 1.062737 | 1.148216 | 0.560872 | -0.282448 | 0.012451 |
| 1 | 2018 | 中日 | 0.965238 | 0.306402 | -0.757466 | -0.698321 | -1.214815 |
| 2 | 2018 | 広島 | 0.672742 | 2.003608 | 1.948595 | 1.121126 | 0.012451 |
| 3 | 2018 | 巨人 | 0.185248 | 0.700154 | 1.150654 | -0.646337 | -0.681221 |
| 4 | 2018 | 阪神 | -0.204747 | 0.007694 | -1.173783 | 0.081442 | -0.040909 |
| 5 | 2018 | DeNA | -0.497244 | -0.019461 | 2.156754 | -0.126495 | -2.015205 |
0に近いほど平凡な成績になるように標準化しました。
正だと良い、負だと悪いと思ってください。
例えば、2018年の阪神の75盗塁は、標準化すると0.08なので平均的よりちょっと良いです。
データフレームの正規化
ではグラフ描画のため、このデータフレームを正規化します。
正規化とはID一個に値が一個のテーブル構造にする事です。
「横持ちを縦持ちにする」とか「ピボットテーブルにする」と同じ意味です。
pandasではpd.melt()で正規化ができます。
batting_melt = pd.melt(team_batting, id_vars=["年度","チーム"], value_vars=["打率","得点","本塁打","盗塁","犠打"])batting_melt.head(10)
| 年度 | チーム | variable | value | |
|---|---|---|---|---|
| 0 | 2018 | ヤクルト | 打率 | 1.062737 |
| 1 | 2018 | 中日 | 打率 | 0.965238 |
| 2 | 2018 | 広島 | 打率 | 0.672742 |
| 3 | 2018 | 巨人 | 打率 | 0.185248 |
| 4 | 2018 | 阪神 | 打率 | -0.204747 |
| 5 | 2018 | DeNA | 打率 | -0.497244 |
| 6 | 2017 | 広島 | 打率 | 1.745228 |
| 7 | 2017 | DeNA | 打率 | -0.302246 |
| 8 | 2017 | 巨人 | 打率 | -0.594743 |
| 9 | 2017 | 阪神 | 打率 | -0.594743 |
catplot
seabornのcatplotでグラフ化します。
ax = sns.catplot(x='年度', y='value', data=batting_melt, col='チーム', row='variable', kind='point')
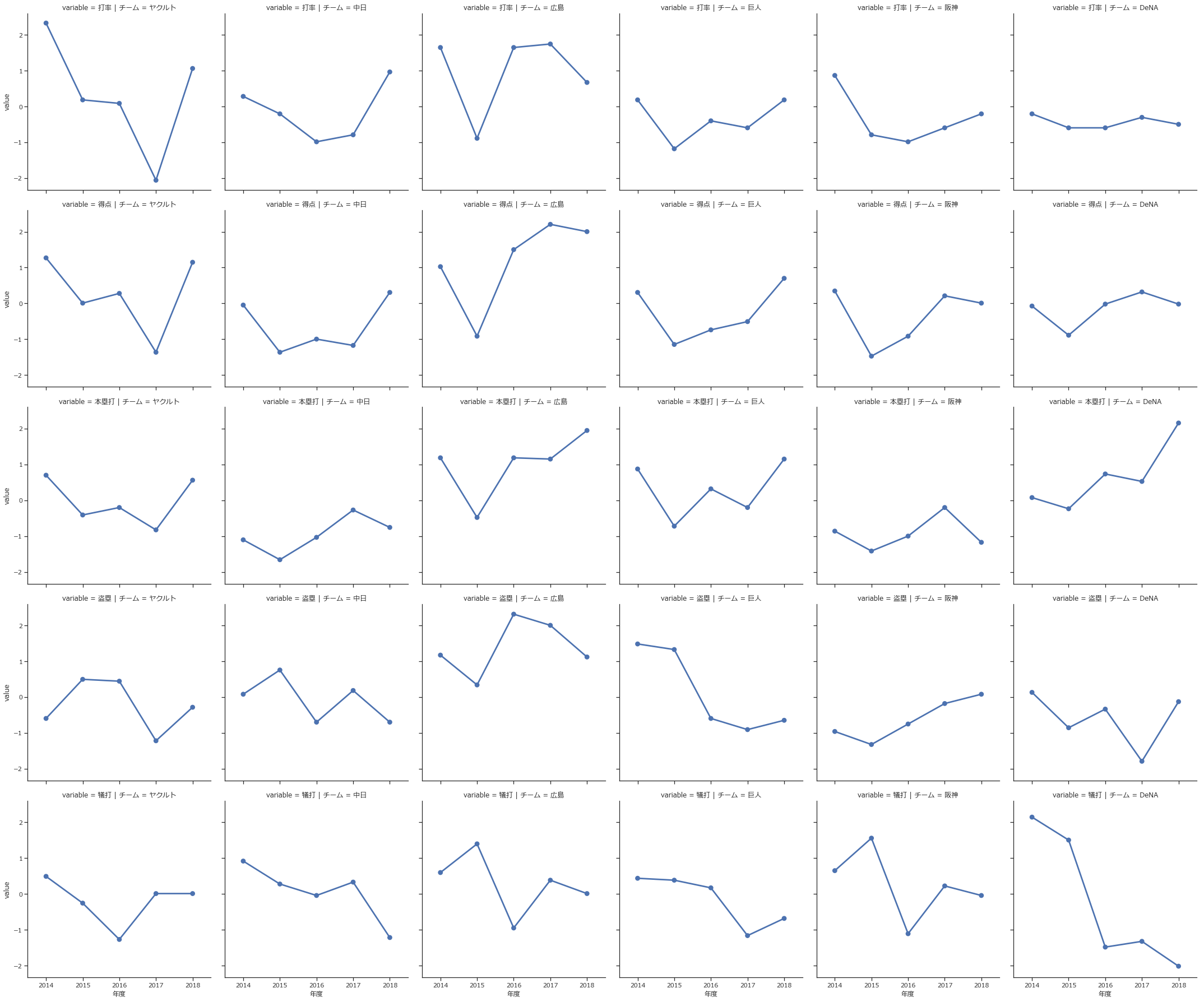
グラフがたくさんでてきました。
行方向は打率、得点などの成績名、列方向はチーム名です。
中の折れ線グラフは年度ごとの成績の推移を表しています。
例えば一番左の列を見ればヤクルトの成績の年度推移が一目で見れるわけですが、
2017年度はどの項目も谷になっているので、この年は調子悪かったんだなと読み取れます。
DeNAの打率が低いところで安定しているのも目立ちますね。
おまけ - matplotlibで日本語フォント
matplotlibでは日本語が表示できないません。(全部□になってしまう)
matplotlibはttfとotf形式にしか対応しておらず、日本語フォントはほぼttcという形式だからです。
よって使える形式の日本語フォントを探すか、フォントの形式を変換してインストールすると解決します。
そして以下のコマンドを実行します。
import matplotlib as mpl
font = {"family":"meiryo"}
mpl.rc('font', **font)
# ダメな場合はmatplotlibのキャッシュをリセットする
mpl.font_manager._rebuild()
終わりに
part1はここまで。
part2は日本シリーズ開幕時に公開します。
弊社ではデータスクレイピングだけでなく、pythonを用いた機械学習やデータビジュアライズなども承っております。
最近流行りのデータサイエンスでソリューションを生み出しましょう。
CONTACT
お問い合わせ・ご依頼はこちらから