MAGAZINE
ルーターマガジン
アレクサスキルの音声認識・発話の精度を向上させる

こんにちは。学生アルバイトの齋藤です。
今回、Amazonが出しているAmazon Alexaのスキル開発をするにあたって、音声認識の精度を向上させ、Alexa音声の読み上げを正しいものに修正するためのテストを行っていました。
そこで、具体的にどのようにしてAlexaスキルの精度を上げていったかを紹介しようと思います。
同義語を登録して認識精度をあげる
Alexaは素のままだと意外と正しく認識してくれません。そこで、同義語で誤認識したワードを登録してあげることで、精度を上げることができます。
具体的な手順は以下のようになります。
手順1, 登録したものを読み上げる
まずはAlexaを使って開いてワードが正しく認識されるかどうか確かめてみます。
手順2, もし間違って他のワードでAlexaに認識されていたとき、ログを見てどのようなワードが認識されたかを確かめる
ホーム画面上の「ビルド」から、「対話モデル」の中にある種類のデータが入っている「スロットタイプ」から作成することでできます。
手順3, 正しくないと認識されてしまったワードを同義語として登録する
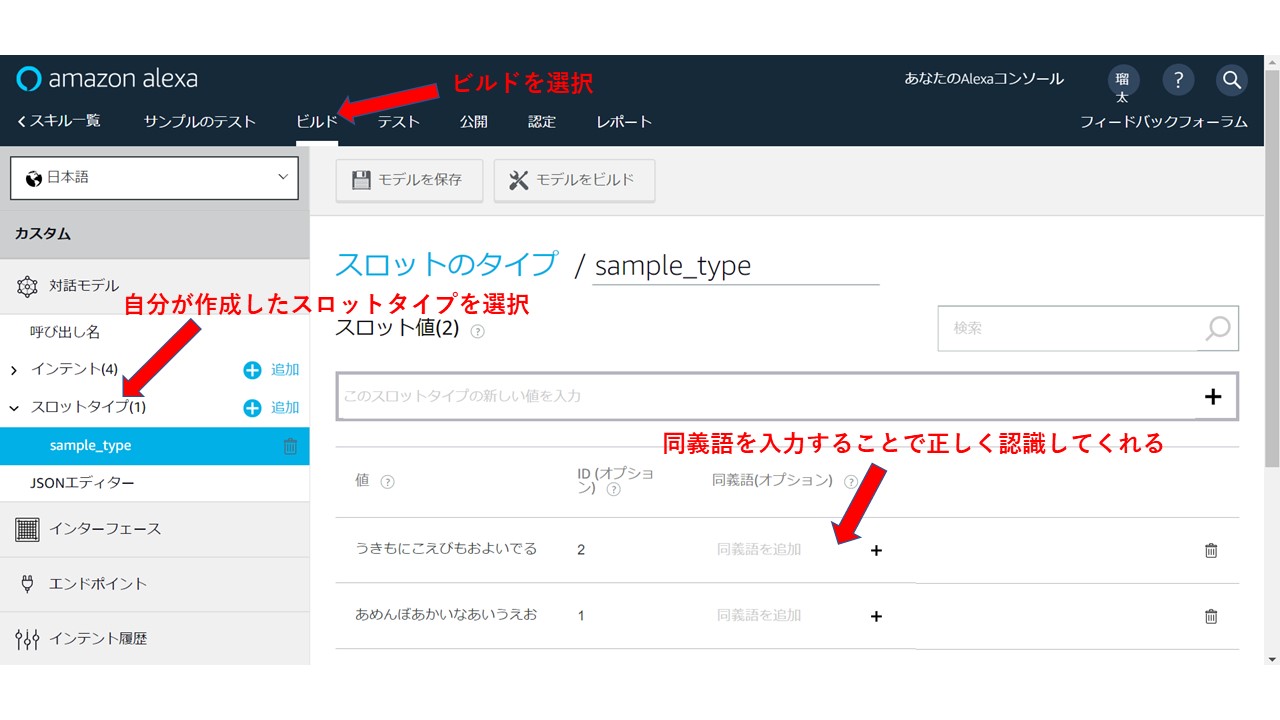
そして、これらの手順1~3を精度が上がるまで繰り返します。
単純な作業ですが、これをするかしないかで認識精度が格段に向上します。
自分はデータ数が600程度のものに対してこれを行ったところ、精度は格段に良くなりました。
Alexa音声の読み上げを正しいものに修正する
発音の認識のテストしていたところ、Alexaの読み上げが間違っているということが多々ありました。
なので、ちゃんと正しく発音してくれるかどうかを確かめるためのテストをやる必要がありました。
「テスト」にある「音声と語調」で音声シミュレータを使用することができます。speakタグで囲まれた部分に話させたい文字列を入力することで読み上げてくれるので、これで正しく読み上げるかをテストを行えます。
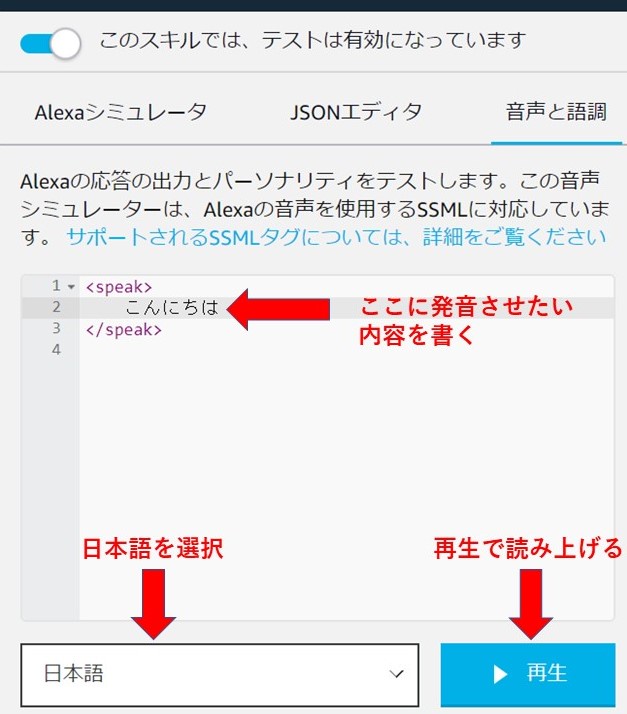
そこでAlexaの発音テストで気づいた特徴的なところがいくつかあったため、紹介しようと思います。
特徴1, 日本語発話で英語の文字列を入力してもそれをむりやりローマ字で読むことがある
日本語発話の状態で英語の「student」や「teacher」を入力したときは少し片言の英語をしゃべってくれるのですが、たとえば「BMI」や「bmi」と入力したとき、「ビーエムアイ」としゃべらずに「ブミ」と発音してしまいます。
この解決策として、「BMI」や「bmi」という文字列を「B M I 」という風に空白を挿入した形で内部で置換させて文字と文字の間に半角スペースを入れることにより、正しく発音させることができます。また、「BMI」や「bmi」を「ビーエムアイ」と登録することでも発音させることができますが、これより英語の文字間に半角スペースを入れたほうが発音時のイントネーションをそれっぽく発音してくれます。
特徴2, 「α」や日本語文字間の半角/全角スペースはなにもないのと同じ扱いをする
日本語文字間の半角/全角スペースはアレクサは認識せずに、エラーにもなりません。そのため間を空けるといったこともせずに読み上げます。また、「α」も認識せずにエラーにもならないため認識されていないため、「α」を「アルファ」に内部的に置き換えて解決しましょう。
特徴3, 「()」は最初に間が入る
括弧「()」が入った文字列の読み上げの際、Alexaは最初の「(」の部分に空白を置き、「)」はαと同様になにもないのと同じ文字列として扱うため、「カッコ」など特になにか特別な発音はしません。
特徴4, 「&」「<>」は認識できない文字であるため、文中にあるとエラーがでて読み上げるのをやめてしまう
「<>」を読み上げるとき、「入力内容が矛盾しています。」というエラーがでて、読み上げてくれません。そのため「<」を「(」に、「>」を「)」に置き換えることで解決しましょう。
おわりに
Alexaスキルの開発をする際、発音の認識精度向上と、Alexaの発音修正は必須項目なので、ぜひ参考にしてください。
CONTACT
お問い合わせ・ご依頼はこちらから