
オブジェクト検出とは画像内に何が写っているか判定すること。
最近社内でもその需要が高まっています。
オブジェクト検出といえばGoogleのCloud Vision APIやMicrosoft AzureのComputer Vision APIなど既に学習済みのモデルを利用できるサービスがあります。
しかし検出したいものが一般的なものではない場合(例えばゲームのキャラの顔を検出したいなど)これらのAPIでは検出することができません。
そんな時に有効なのがGoogle Cloud AutoML Visionです。
自分好みにカスタマイズされたオブジェクト検出モデルを作成することができます。
Google Cloud AutoML Vision
Google Cloud AutoML Vision は、誰でも簡単にカスタム機械学習モデルを作成することができるサービスです。 WEBブラウザから Cloud AutoML Vision に学習させたい画像ファイルをアップロードしてラベル付けをするだけで、カスタム機械学習モデルをトレーニングすることができます。
人間がやることは
- 教師画像を用意する
- 正解ラベルが書かれたCSVを用意する
ことだけです。
教師データさえあればモデル作成は自動的に行ってくれるため簡単に自分用にカスタマイズされたモデルが作れます。
利点1. ブラウザ上の作業で完結している
全ての作業がブラウザ上で完結しているため非エンジニアでも作成できます。
ソースコードを書いたりPCの環境を整える必要もありません。
画像のインポートもブラウザ上でできます。
利点2. 機械学習の知識がいらない
機械学習には知識と経験が必要ですが、AutoMLが煩雑なチューニングを全て自動でやってくれるため、専門的な知識は必要ありません。
例えばデータセットを
- トレーニング
- バリデーション
- テスト
に分けるなどは自動でやってくれるため、初心者でも信頼の置けるモデルが作成できます。
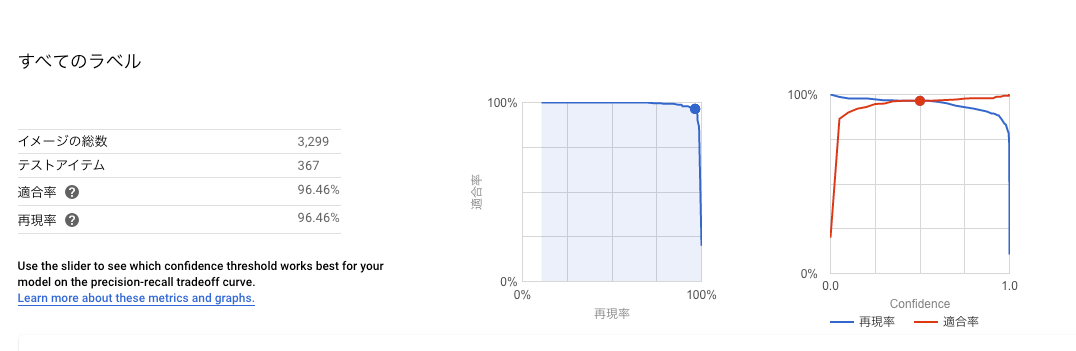
モデルの精度
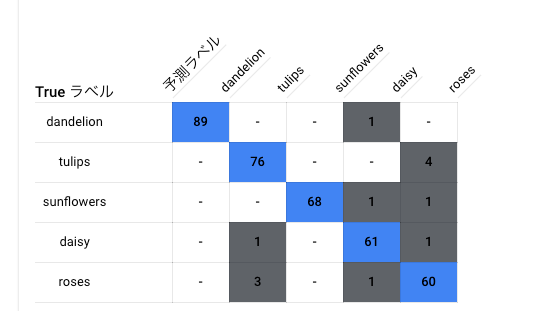
オブジェクトごとの精度
実際にモデルを作ってみる
ケンタッキーのロゴを判定してみました。このロゴを検出したいとします。

教師データの作成ですがランダムで選んだ背景画像にロゴを貼り付けることで作成します。
綺麗な山です。

合成方法はなんでもOKですが、私はImageMagickを使って作成しました。
composite -gravity southeast -compose over logo.png back_ground.jpg after.jpg

このような画像を1000枚ほど作って学習させました。

検出結果
全く同じロゴはもちろんのこと、微妙に違うロゴや物体にプリントされたロゴまで検出できました



終わりに
ちょっとしたオブジェクト検出が手軽にできると自作ツールの可能性も広がりそうですね。
私はゲームのレベル上げなどの単純作業が自動化できるんじゃないかと考えています。
皆さんも何か有効活用してみましょう。
それでは。