MAGAZINE
ルーターマガジン
PostgreSQLでの期間検索パフォーマンス改善 ~ B-treeからGiSTインデックス(daterange)への移行 ~
はじめに
Webアプリケーション開発において、「ある期間と重なるレコードを抽出したい」という要件は非常に一般的です。予約システム、イベントカレンダー、サブスクリプション期間の集計など、枚挙にいとまがありません。
私もこれまで、開始日と終了日という2つのカラムに対して複合インデックス(B-tree)を張り、泥臭いWHERE句で対応していました。しかし、データ量が増えるにつれてクエリが重くなる問題に直面しました。
そこで、PostgreSQLのRange型(daterange)とGiSTインデックスを導入したところ、パフォーマンスが劇的に向上しました。本記事では、実際の実装例とベンチマーク結果を交えて、その効果を紹介します。
1. 従来のアプローチ:B-treeと不等号の限界
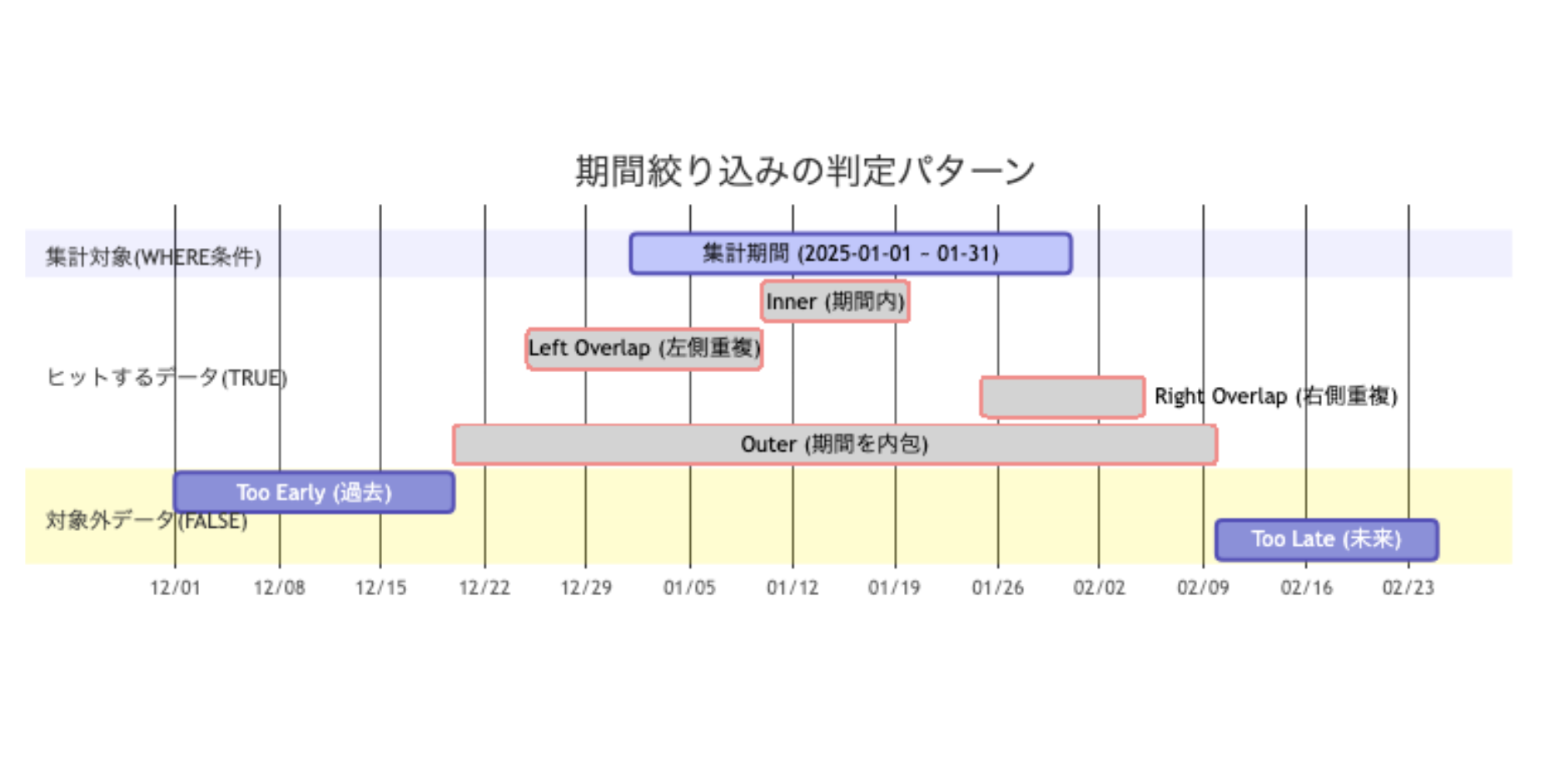
まず、今回の要件を整理します。「ある集計期間(例:2025年1月)と重なりを持つデータを抽出したい」という場合、対象となるデータは以下の4パターンが考えられます。
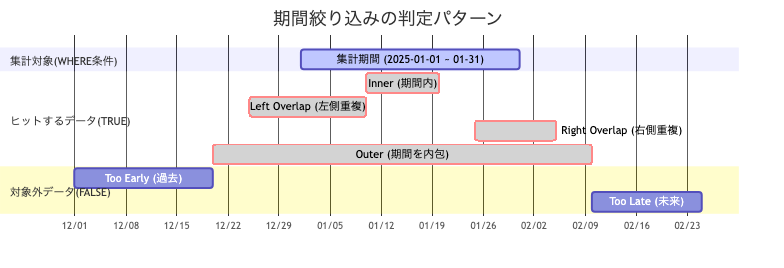
図の赤枠の4条件(内包、左側重複、右側重複、期間を覆う)のすべてを漏らさず取得する必要があります。 これを実現するために、これまでは以下のようなインデックスとクエリを書いていました。
今回はキャンペーン管理の例を取り上げます。
CREATE TABLE campaigns (
id SERIAL PRIMARY KEY,
name TEXT,
start_date DATE NOT NULL,
end_date DATE NOT NULL
);
-- 従来のインデックス戦略
CREATE INDEX idx_campaigns_dates ON campaigns (start_date, end_date);例えば、「2024年1月」に開催されているキャンペーンを集計したい場合、これまでは以下のようなクエリを書いていました。
-- 集計期間:2024-01-01 〜 2024-01-31
SELECT *
FROM campaigns
WHERE start_date <= '2024-01-31' -- 集計終了日以前に始まっていて
AND end_date >= '2024-01-01'; -- かつ、集計開始日以降に終わっているこの条件式で論理的には上の図の4パターンを完璧にカバーできます。
しかし、パフォーマンスの観点では大きな問題がありました。
なぜこれだと遅くなるのか?
このクエリに対して、PostgreSQLのB-treeインデックスは最適に機能しづらい弱点があります。
start_date = ’2024-01-31’の条件で、過去の全データを含む広範囲がヒットしてしまいます。- 複合インデックスの1列目で範囲検索(不等号)を行うと、2列目の
end_dateの順序性は崩れるため、インデックスの効きが悪くなります。
結果として、インデックススキャンをしているにも関わらず、多くの無駄な行を読み込むことになり、データ量に比例して遅くなっていました。
2. 新しいアプローチ:daterangeとGiSTインデックス
ここで登場するのが、PostgreSQL 9.2から導入された「範囲型(Range Types)」と、それを効率的に扱える「GiSTインデックス」です。
インデックスの変更
既存のテーブル構造(start_date, end_dateカラム)を変えずに、関数インデックスを使って対応することが可能です。
-- daterange関数に対するGiSTインデックスを作成
-- 第3引数の '[]' は閉区間(開始日・終了日を含む)を指定
CREATE INDEX idx_campaigns_range
ON campaigns
USING gist (daterange(start_date, end_date, '[]'));クエリの変更
クエリも「範囲の重なり」を表す演算子 && を使って書き換えます。
SELECT *
FROM campaigns
WHERE daterange(start_date, end_date, '[]') && daterange('2024-01-01', '2024-01-20', '[]');3. 実測:どれくらい速くなったのか?
実際に100万件程度のダミーデータを作成し、検証を行いました。 (データ分布:過去10年分のデータ、期間は1日〜30日程度でランダム)
実行計画の比較 (EXPLAIN ANALYZE)
▼ Before: B-tree複合インデックス
Index Scan using idx_campaigns_dates on campaigns ...
Index Cond: ((start_date <= '2024-01-31'::date) AND (end_date >= '2024-01-01'::date))
Filter: ...
Rows Removed by Filter: 450201
Execution Time: 180.5 msRows Removed に注目してください。インデックスで範囲を絞ったはずが、実際にはマッチしない45万行近くを読み込んでから捨てています。これが遅延の原因です。
▼ After: GiSTインデックス (daterange)
Index Scan using idx_campaigns_range on campaigns ...
Index Cond: (daterange(start_date, end_date, '[]'::text) && '[2024-01-01,2024-01-31]'::daterange)
Execution Time: 3.2 ms結果まとめ
| 戦略 | 実行時間 | 備考 |
|---|---|---|
| B-tree (start, end) | 180.5 ms | 無駄な読み込み(Filter)が大量発生 |
| GiST (daterange) | 3.2 ms | 約56倍の高速化。ピンポイントで対象を取得 |
B-treeが「1次元的な並び替え」であるのに対し、GiST(R-treeの一種)は「2次元的な空間」としてデータを捉えるため、期間の重なり判定において圧倒的な効率を発揮します。
4. 補足と注意点
区間の指定に注意
daterange関数の第3引数や、リテラルでの [](閉区間)、[)(半開区間)の使い分けは重要です。
[]: StartとEndの両方を含む(今回の例)[): Startは含むが、Endは含まない
ビジネスロジックに合わせて適切に設定してください。
排他制約(Exclusion Constraints)も使える
GiSTインデックスの副産物として、「期間の重複を許さない」という制約をDBレベルでかけることも可能になります。会議室予約システムなどで強力な武器になります。
ALTER TABLE campaigns ADD CONSTRAINT no_overlap
EXCLUDE USING gist (daterange(start_date, end_date, '[]') WITH &&);まとめ
「開始日」と「終了日」を持つデータに対して、期間指定での絞り込みを行う場合、B-tree複合インデックスよりも、daterangeを使ったGiSTインデックスの方が、パフォーマンス・可読性ともに優れています。
特に、「過去データが大量にあるが、直近の期間重複チェックを頻繁に行う」といったケースでは、劇的な改善が見込めます。まだ start_date = ? で消耗している方は、ぜひ daterange と && 演算子の導入を検討してみてください。
CONTACT
お問い合わせ・ご依頼はこちらから