MAGAZINE
ルーターマガジン
Pythonのデータ分析ライブラリpandasでreadで取込できるモノ

こんにちは。rooterエンジニアのohkabeです。
弊社はクローリング会社ですが、集めたデータについての分析も同様に重要な業務となっており、データコンサルティングサービスも提供しております。
今日はそんなデータ分析を効率的に行うをテーマにしたいと思います。
背景
データ分析はpandasでDataFrameを作ることから始まります。
基本的にはcsvファイルを読み込むことが多いですが、必ずしも手に入れたローデータがcsv形式であるとは限りません。
筆者はデータがエクセル形式だった場合、一度csvに変換して読み込むという手間をかけていました。
この作業がなかなか面倒だったのですが、実はエクセルもそのまま読めてしまうんですね。
よく使うものをあげると、
- csv
- tsv
- json
- excel
- sql
- html
というわけでpandasで直接DataFrameとしてreadできる物について紹介します。
import pandas as pd
csv/tsv
csvにはpd.read_csv()
tsvにはpd.read_table()が使えます。
基本的にはファイルパスを指定しますが、実はurlを指定してもOKです。
url = "https://raw.githubusercontent.com/fumingos/pandas_read/master/meibo.csv"df = pd.read_csv(url)df.head()
| name | gender | age | |
|---|---|---|---|
| 0 | john | m | 18 |
| 1 | paul | m | 20 |
| 2 | alice | f | 15 |
| 3 | dabid | m | 17 |
| 4 | jasmin | f | 17 |
json
ファイルが以下のようなjson形式であっても、keyをカラムとしたDataFrameに変換してくれます。
[{"name":"john","gender":"m","age":"18"},{"name":"paul","gender":"m","age":"20"},{"name":"alice","gender":"f","age":"15"},{"name":"dabid","gender":"m","age":"17"},{"name":"jasmin","gender":"f","age":"17"}]
df = pd.read_json("meibo.json")df.head()
| age | gender | name | |
|---|---|---|---|
| 0 | 18 | m | john |
| 1 | 20 | m | paul |
| 2 | 15 | f | alice |
| 3 | 17 | m | dabid |
| 4 | 17 | f | jasmin |
前述の通りurlも叩けるということは、apiも取得できます。
url = "https://raw.githubusercontent.com/fumingos/pandas_read/master/meibo.json"df = pd.read_json(url)df.head()
| age | gender | name | |
|---|---|---|---|
| 0 | 18 | m | john |
| 1 | 20 | m | paul |
| 2 | 15 | f | alice |
| 3 | 17 | m | dabid |
| 4 | 17 | f | jasmin |
excel
read_excel()でエクセルもDataFrame化できます。
sheet_nameでシートの指定もできますよ。
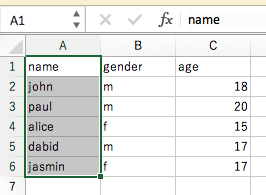
df = pd.read_excel('meibo.xlsx')df.head()
| name | gender | age | |
|---|---|---|---|
| 0 | john | m | 18 |
| 1 | paul | m | 20 |
| 2 | alice | f | 15 |
| 3 | dabid | m | 17 |
| 4 | jasmin | f | 17 |
sql
別途モジュールが必要になりますがmysqlclientなどを使えばデータベースもreadできます。pip install mysqlclient
import pandas.io.sql as psqlimport MySQLdbconn = MySQLdb.connect(host = "127.0.0.1",user = 'root',password = '',database = 'training',)cur = conn.cursor()
df = psql.read_sql("SELECT * from meibo;", conn)df.head()
| name | gender | age | |
|---|---|---|---|
| 0 | john | m | 18 |
| 1 | paul | m | 20 |
| 2 | alice | f | 15 |
| 3 | dabid | m | 17 |
| 4 | jasmin | f | 17 |
html
read_htmlを使えばweb上のtableタグを読み取ってDataFrameにすることができます。
スクレイピングいらずですね!
url = 'https://fumingos.github.io/pandas_read'datasets = pd.io.html.read_html(url, header=0)datasets[0]
| 名前 | 背番号 | ポジション | 打率 | 打点 | 本塁打 | 盗塁 | |
|---|---|---|---|---|---|---|---|
| 0 | 佐藤 | 1 | ライト | 0.302 | 40 | 18 | 20 |
| 1 | 鈴木 | 18 | ピッチャー | 0.188 | 10 | 1 | 2 |
| 2 | 田中 | 99 | キャッチャー | 0.280 | 70 | 38 | 0 |
| 3 | 山田 | 0 | ショート | 0.333 | 52 | 9 | 30 |
終わりに
以上のメソッドを使いこなせば、データの中身を覗き見る時や、ちょっとしたグラフを描きたい時にサクッと作業を終わらせることができます。
他にもgoogleスプレッドシートを読み込む方法などがあるようなので皆さんも試して見てください。
それでは。
CONTACT
お問い合わせ・ご依頼はこちらから