NEWS
お知らせ
対話特化型音声合成エンジン、VOICECLOUDのデモをリリース
昨年、対話に特化した音声合成エンジンVOICECLOUD(ボイスクラウド)の開発スタートを発表致しました。その後開発が進み、第一弾の音声合成エンジンのサンプルができあがりましたので、この度、皆様にご利用いただける音声合成のデモを公開させていただきます。
本デモの音声合成エンジンは、プロの話者が音韻、韻律に関して十分な量とカバレッジで音声を収録し、音声合成モデルを作成したものです。弊社の音声合成は対話に特化しており、複数話者間の対話音声生成に関してリアルな発話を生成可能です。下記のデモ画面よりぜひお試し頂ければと思います。
近年、スマートスピーカーに代表される、音声対話UI(VUI: Voice User Interface)デバイスが急速に普及しています。しかし、現在のスマートスピーカーの開発環境において、スキル開発者が利用できる話者(声色)の種類は数種類に限られており、また、現在利用可能な発話音声は「対話」において、抑揚のなさや、違和感のあるアクセントなどがどうしても目立ってしまいます。人間の話者による録音音声を利用して人間のようにリアルな発話を実現する方法もありますが、収録可能な音声バリエーションには限りがあり、また、質の高い音声の収録には膨大な時間とコストが必要となります。VOICECLOUDはこのような音声対話UI開発上の課題において有効なソリューションとなると考えております。
株式会社ルーターはVOICECLOUDを通して音声対話UI時代の開発上の問題を解消し、世の中の技術の発展に貢献してまいります。
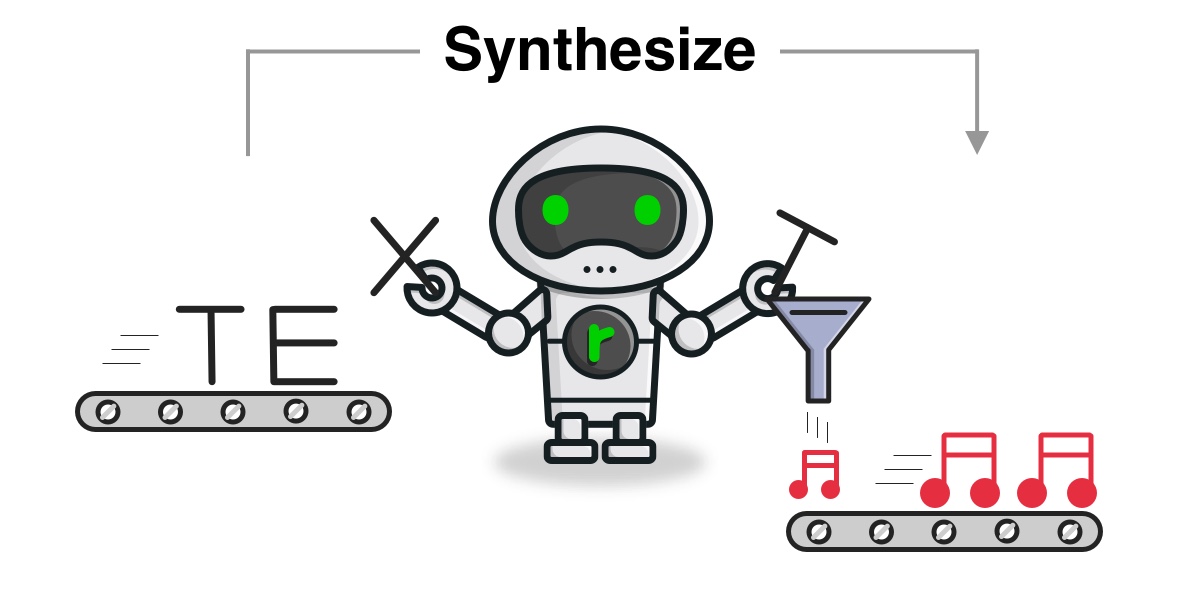
VOICECLOUDの音声合成手法について
入力テキスト→発話音声の流れ
入力テキスト
↓
漢字、数字の読み、抑揚、アクセントなどを推定
↓
事前に学習したDNNを用いて、声の高さなどを表す音響パラメータを推定
↓
推定された音響パラメータから、音声波形を生成
↓
発話音声読み、アクセントなどの推定
漢字、数字の読み方は、基本的にルールに従って推定しています。ただし、文脈によって読み方が変わる場合(ex. 四番→よんばん、よばん)や固有名詞の推定は、単純なルールだけでは完全に対応することが難しいため、精度に課題があります。
アクセントについても、基本的に日本語の単語のアクセントのルールに従って推定しています。「広場(ひろば)」は先頭の音が高く、「卵(たまご)」は真ん中の音が高く、「桜(さくら)」は平坦、というようなルールです。
また、これらの単語が実際に文章の中で使われる場合、単語単体の場合とアクセントが異なることがあります。例えば、「最高(さいこう)」と「気温(きおん)」は、どちらも平坦に発音される単語ですが、「最高気温(さいこうきおん)」のように結合すると、真ん中の「き」の音が高くなる、という性質を持っています。こちらについてもルールにしたがって推定を行なっていますが、こちらの場合も結合するしないの判断 や固有名詞への対応が課題となっています。
DNNの学習
プロの女性話者の発話音声を収録し、音声波形から声の高さなどを表す音響パラメータを抽出し、それぞれのパラメータについて、DNNを学習しています。
収録音声の原稿は、より品質の高い合成音声を生成するために、出現頻度の低い音(半濁音、拗音など)も多く含まれるよう、バランスを取っています。また、対話調の文章においても自然な音声が得られるよう、「〜〜だよ」、「〜〜しましょう」などの文末のパターンをピックアップし、そのような文末を持つ文章も含んでいます。
収録音声に対して、読みやアクセントなどの情報(ラベル)を付与し、また音声から声の高さなどを表す音響パラメータを抽出します。抽出した音響パラメータとラベルを学習データセットとし、DNNを学習しました。
より品質の良いDNNを学習するために、どのようなラベルを付与するべきか、いくつものパターンを用意し、それらのパターンの中から最良のラベルを使用しています。
強み
DNNの学習の部分で説明したように、対話調の文章も学習データに含んでいるため、対話調の音声、特に文末の部分の自然性が高いです。
CONTACT
お問い合わせ・ご依頼はこちらから