NEWS
お知らせ
ニュースリリース
VOICECLOUD プロジェクトをスタートします
2018.01.03
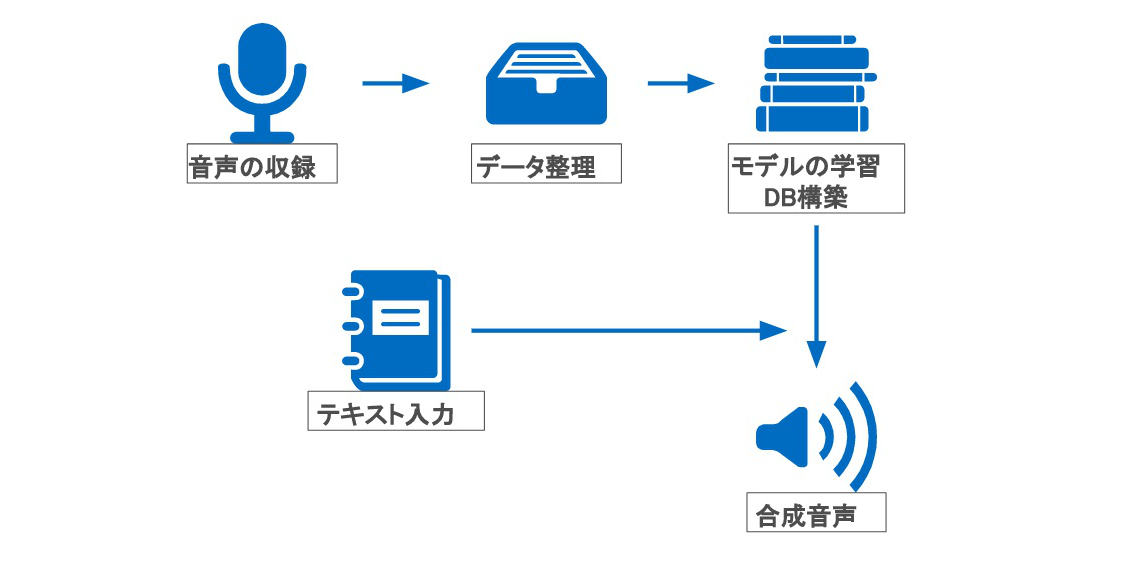
近頃、Google HomeやAmazon Echoを筆頭に、スマートスピーカーと呼ばれる音声対話インターフェースが市場に提供され始めています。これに伴い、音声対話によるデバイスの操作や情報のやり取りは、広く一般に浸透すると考えられます。
ここで問題になってくるのが、デバイスによる音声発話の品質です。現時点で日本語対応しているスマートスピーカーの発話を聞いてみると、英語の発話のときには感じなかった違和感があり、その違和感の主な原因は、抑揚やアクセントなどの韻律に関する部分の品質が十分でないと感じられます。
VOICECLOUDでは、この問題点を解決するべく、音韻性だけでなく韻律性においても高い品質を持つ合成音声を提供することを目標とします。 また、声優、アナウンサーの声や、エンドユーザーの声に近い合成音声も、需要は多くあると考えられます。 VOICECLOUDでは、これらのニーズに応えるべく、ユーザーが求める話者の合成音声を得られるような仕組みを備えることも目標とします。
合成手法(モデル、データベースによる分類)
以下に、合成手法のそれぞれの特長を紹介します。
HMM音声合成
- 比較的昔から研究されている手法その1
- 音声から声の高さや声道特性などのパラメータを扱う
- 学習時は、それらのパラメータに関してモデルを構築する
- 合成時は、モデルにしたがってパラメータを計算し、パラメータから音声波 形を再合成する
- 比較的滑らかな音声が得られるが、音声波形の再合成を行う関係上、やや機械的な音声になってしまう
- モデルの学習にかかる時間は、データ量にもよるが、通常のマシンで半日程度(要検証)
- 合成はほぼリアルタイムで行えるため、事前にモデルを用意しておけばAPI化も可能
素片接続法
- 比較的昔から研究されている手法その2
- 収録した音声を、音響素片と言われるパーツに分解して、そのパーツをつなぎ合わせて任意の発話を得る
- 音声波形をそのまま使うと継ぎ目が不自然になってしまうため、声の高さを合成時に調整する必要がある
- 音声波形をほぼそのまま使用するため、機械的な音声にはならないが、継ぎ目を目立たせないためには工夫が必要
- 合成はほぼリアルタイムで行えるため、API化も可能
DNN(ディープニューラルネットワーク)
- 最近盛んに研究されている、比較的新しい手法
- HMMの代わりにDNNによるモデルを学習する(要検証)
- データ量が十分であれば、音声波形をそのまま扱うことも可能と考えられる
- 学習にかかる時間は不明だが、合成にかかる時間は短いため、API化も可能
合成手法(話者依存の音声を得る方法)
- ゼロから目標話者のモデル、データベースを構築する
- 目標話者の音声発話を30分〜2時間程度収録し、モデルの学習やデータベースの構築を行う
- 話者適応と呼ばれる技術を用いる
- 特定話者、あるいは不特定話者のモデルやデータベースを用意する
- ここで、このモデル、データベースは十分な量、カバレッジを持つ必要がある
- 目標話者の音声発話を10分〜30分程度収録し、モデルの学習やデータベースの構築を行う
- 元々用意されているモデルやデータベースから、目標話者のモデルやデータベースへの、変換行列を計算する
- 元々のモデルやデータベースに計算した変換行列を適用し、目標話者の十分な量、カバレッジを持つモデルやデータベースを得る
サービス例 スマートスピーカー向け音声スキン
概要
- スマートスピーカーの発話を、好みの話者による発話に変更する
実現方法
- プロの話者に、事前に用意した、音韻、韻律に関して十分な量とカバレッジを持つ台本を読んでいただき、それを収録する
- 収録した音声に時間情報を付与する(手動or自動)
- モデルの学習、データベースの構築を行う
- 完成したモデル、データベースをサーバーに設置し、リクエストを受けたらその話者による発話音声を生成する
課題
- テキストから韻律情報の推測方法(形態素解析、中間言語の生成)
- レスポンスタイム
サービス例 オリジナルTTS
概要
- 自分、あるいは家族、友人の声で発話するText to Speech
実現方法
- 不特定話者による平均声モデル、データベースを用意する
- TTSを作成したい話者による指定の文章の発話を収録する
- 平均声からの変換行列を計算し、目標話者のモデル、データベースを作成
- 完成したモデル、データベースをサーバーに設置し、リクエストを受けたらその話者による発話音声を生成する
課題
- プロではない人の発話を用いるため、指示通りに読まれない可能性があり、その場合、時間情報以外の情報についても修正を行う必要がある
- 新しく収録された音声を利用し、不特定話者モデル、データベースを強化する手法の検討
- レスポンスタイム
CONTACT
お問い合わせ・ご依頼はこちらから