AIクローラー | 求人原稿のフリーワードを対象にしたコンテンツ分析
求人原稿のフリーワードを対象にしたコンテンツ分析
AIクローラーの特長として、非構造化データからもメタデータを抽出することが可能となっております。以下の事例では、求人情報から、エンジニアスキルに相当する単語を抽出し、各原稿をベクトル化しております。
indeedの求人情報よりテキストデータを取得
以下の例では、indeedより渋谷 * IT * エンジニアの検索結果約800件を対象に情報収集しております。弊社のクローリング技術を用いて、募集要項のみを取得します。
エンジニアリングスキル辞書
求人情報からプログラミング言語や使用技術のみを抽出する辞書を保有しております。元となる技術情報はqiita上でタグとして使われている単語上位2000件を取得し、これを元に形態素解析の辞書を作成します。これにより、フリーワードからエンジニアのスキルに言及している部分を取り出すことができます。
原稿の分析
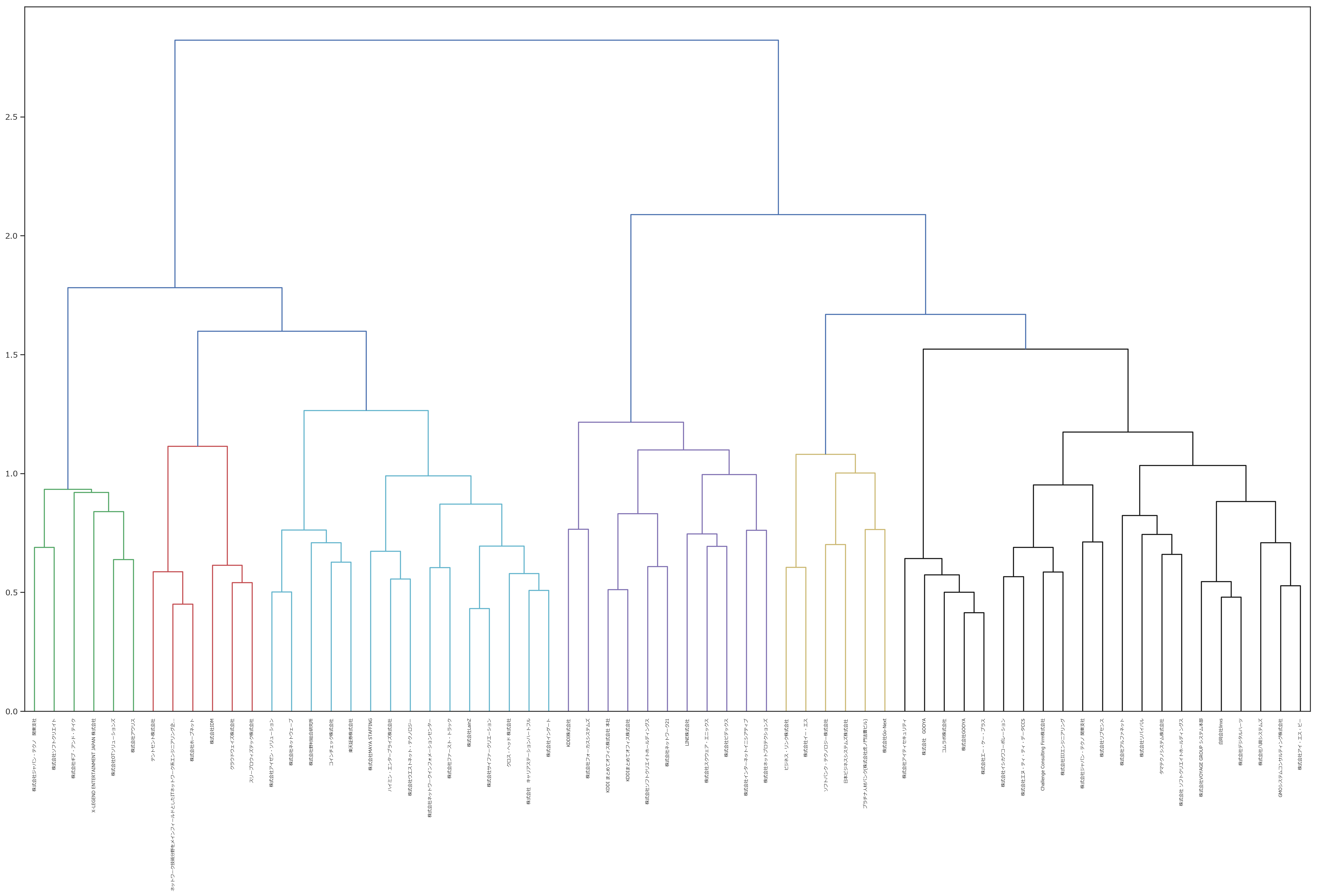
募集要項からエンジニアスキルを抽出し、スキルの出現有無によって各企業をベクトル化 ベクトルの近さを計算することで各企業の類似度を作成します。この例では、「求めるエンジニアが近い企業」を抽出することが可能となります。
さらに距離が計測できることにより、チャート化が可能になります。全体を俯瞰する画像をがこちらになります。これにより原稿上の類似企業が把握できます。本当は似通ってるはずなのに、想定外の企業と類似している場合には、求人原稿を見直すなどの方法をとることが可能になります。
{kind=link}
発展の方向性
今回はエンジニアスキルをベクトル化しましたが、別職種の求人で求められる資質や待遇などの単語もベクトル化することにより、「効果のよい原稿/悪い原稿」との相関を求めることが可能になります。
本件では求人原稿というコンテンツを対象にしましたが、すべてのテキストコンテンツを対象にベクトル化・分析が可能となっております。