NEWS
お知らせ
AIクローラーに本文抽出サービスが加わりました。
概要
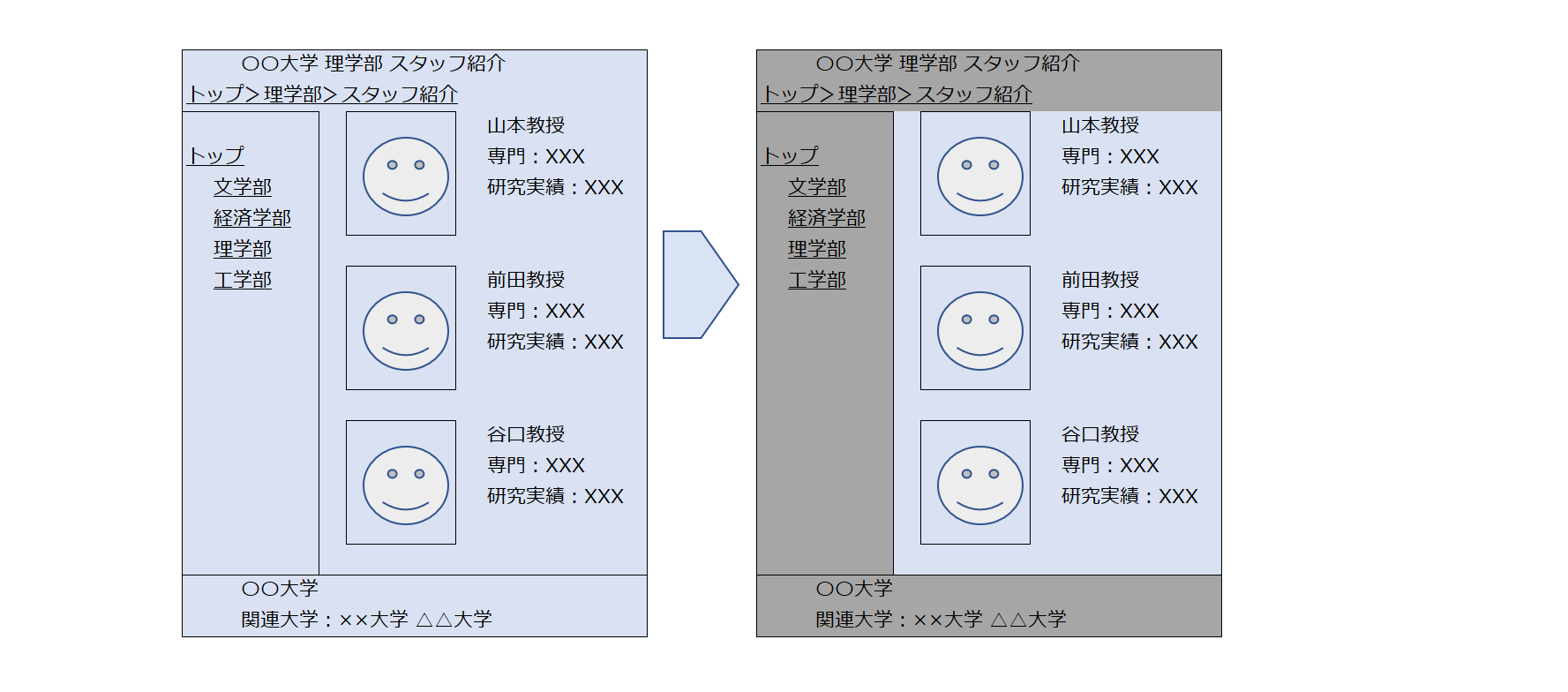
AIクローラーに未知のレイアウトのWebサイトから、ナビゲーションバーやサイドバー、フッターなどを取りのぞいた、本文部分のみを抽出するサービスを提供いたします。
背景
通常のスクレイピング技術では、あらかじめレイアウトが決まっており、どの部分がコンテンツとして重要かということがわかってることが前提となっております。しかしながら、未知のレイアウトのサイトでは、本文領域が分かってないため重要ではない単語も同時に取得してしまいます。
上記の例では、教授の情報を取得したいにもかかわらず、サイドバーやフッターなどから別のスタッフの情報もまじるため、精度高くナビゲーション領域を排除する必要があります。
弊社の技術
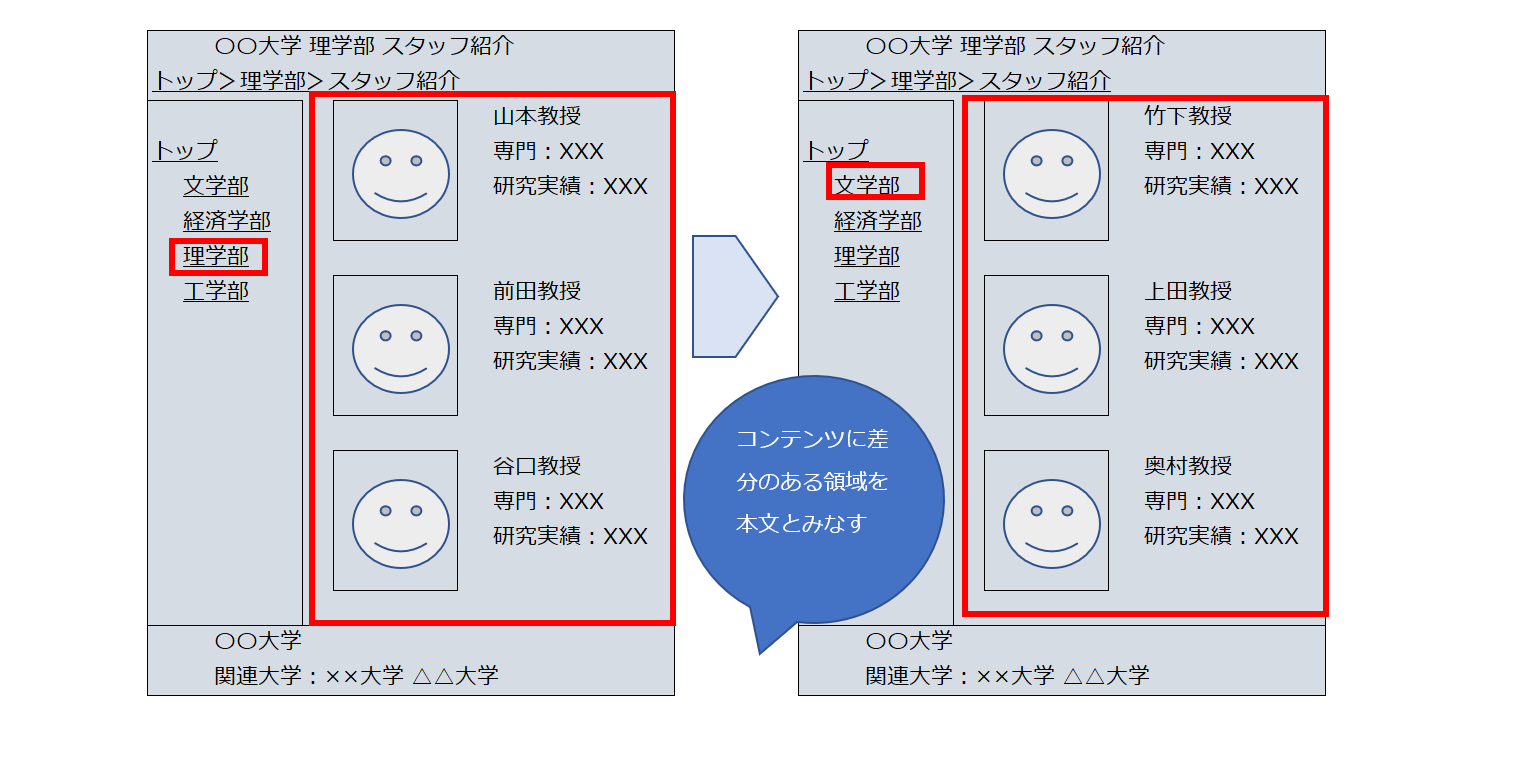
一般的な本文抽出技術では、リンクが多い領域をナビゲーション領域とみなして排除するルールで提供されいることが多いですが、ECサイトなどは本文領域にもリンクが多いためこのルールでは適用できません。
弊社の技術では、ページの中からナビゲゲーションリンクをたどり、別ページとの差分をとることで、「変わらない領域は本文ではない」という判定をすることで、本文部分を判定しております。
用途
コンテンツSEO
昨今のSEOでは本文のコンテンツが重要視されております。SEO上位のサイトの本文部分のみの情報を収集することで、検索エンジンが評価しているフレーズが何かということを分析いたします。
人気コンテンツの分析
マーケティング用途で収集されたユーザのアクセス先URLから、ユーザがコンテンツの何に反応しているかということを分析します。人間は本文領域に反応するために、分析時も同様にページの本文部分のみを抽出します。
機械学習のための教師データ
機械学習の教師データとしてWebサイト上の情報を取得する例が多く見られます。何ゲーション上の単語は出現頻度も単語としての重要性も高いですが、本文とは無関係なデータであるため、排除した上で教師データを作る必要があります。
CONTACT
お問い合わせ・ご依頼はこちらから